VSA
1.0.0
[プロジェクトページ] [?論文] [?ハグフェイススペース] [模型動物園] [紹介] [?ビデオ]

git clone https://github.com/cnzzx/VSA.git
cd VSA
conda create -n vsa python=3.10
conda activate vsa
cd models/LLaVA
pip install -e .
pip install -r requirements.txt
ローカル デモは gradio に基づいており、次のものを使用して簡単に実行できます。
python app.py
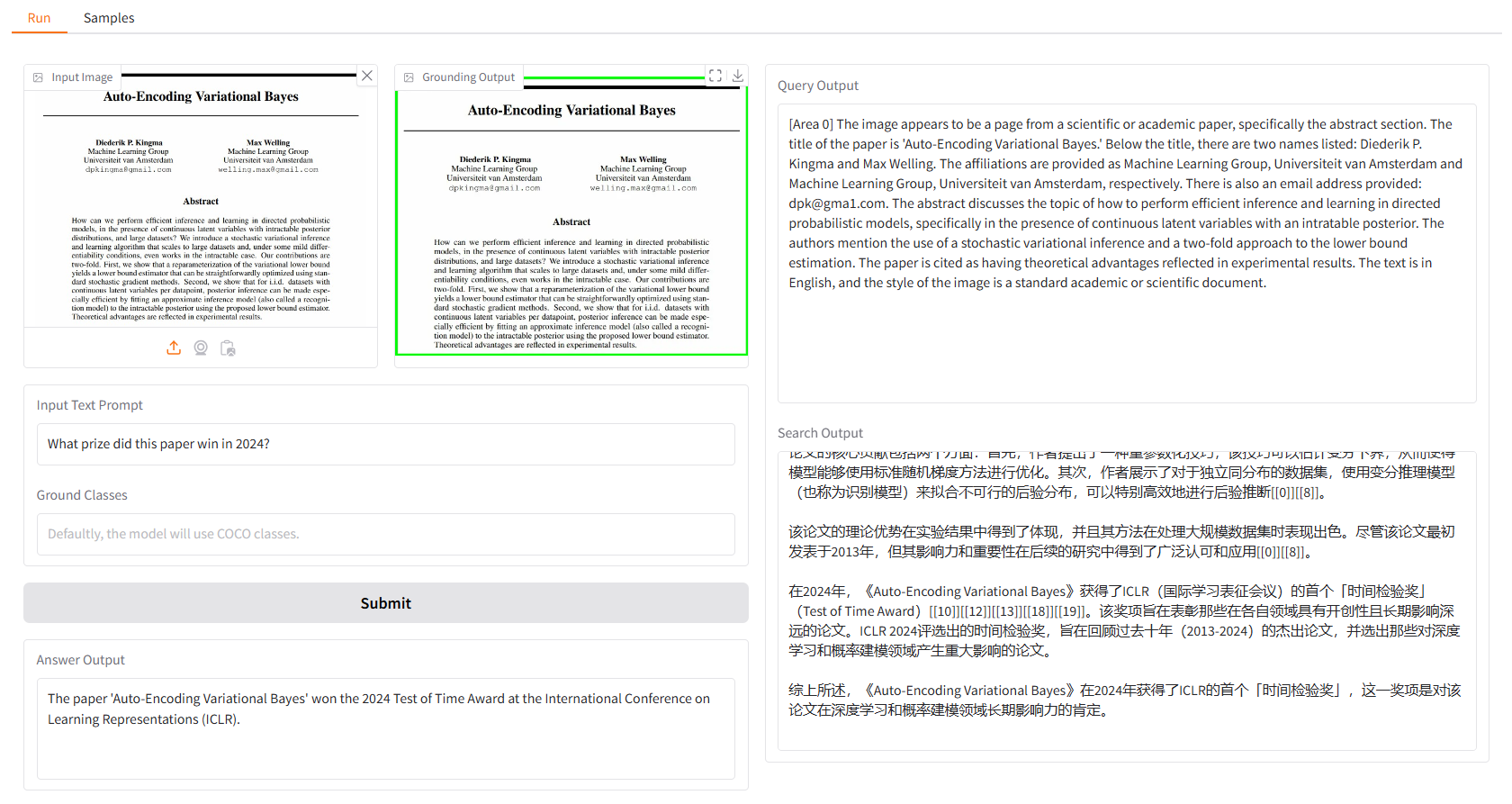
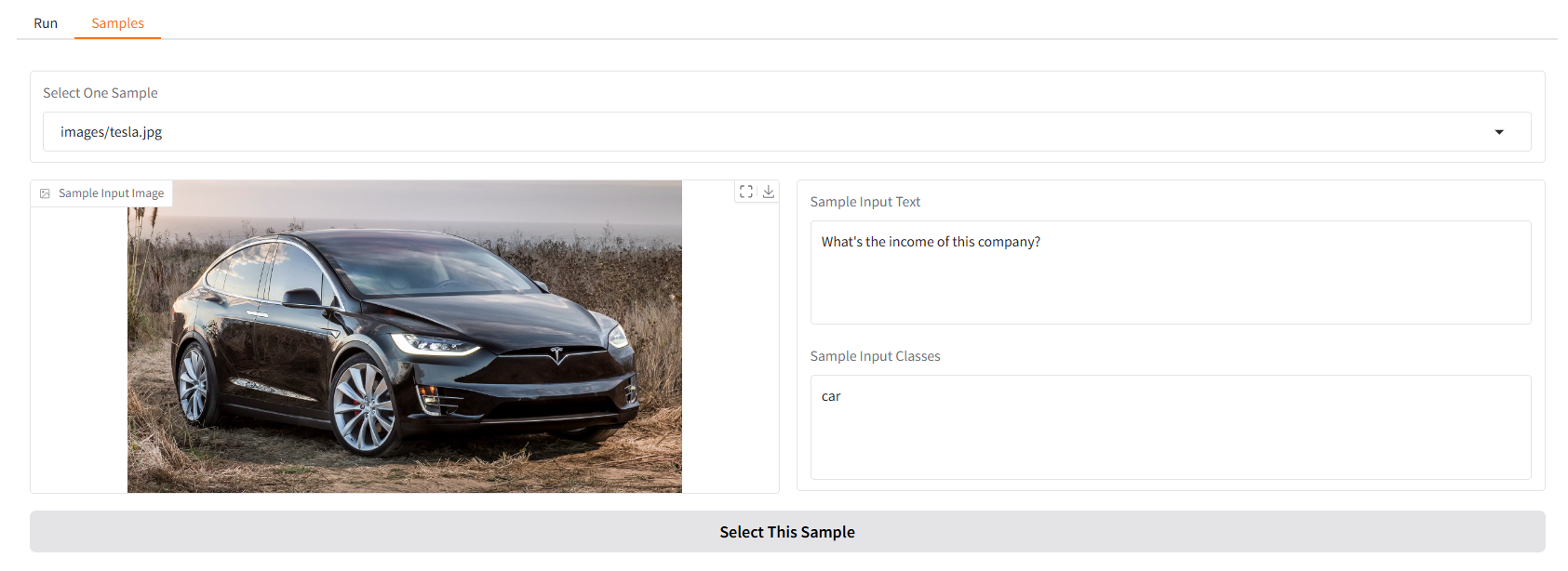
まずはいくつかのサンプルをご用意しています。 「サンプル」UI では、「サンプル」パネルで 1 つを選択し、「このサンプルを選択」をクリックすると、「実行」UI にサンプル入力がすでに入力されていることがわかります。
実行してターミナル内のビジョン検索アシスタントとチャットすることもできます。
python cli.py
--vlm-model "liuhaotian/llava-v1.6-vicuna-7b"
--ground-model "IDEA-Research/grounding-dino-base"
--search-model "internlm/internlm2_5-7b-chat"
--vlm-load-4bit
次に、画像を選択し、質問を入力します。
このプロジェクトは、Apache 2.0 ライセンスに基づいてリリースされています。
Vision Search Assistant は、オープンソース コミュニティへの傑出した貢献から多大な影響を受けています: GroundingDINO、LLaVA、MindSearch。
このプロジェクトがあなたの研究に役立つと思われる場合は、次の引用を検討してください。
@article{zhang2024visionsearchassistantempower,
title={Vision Search Assistant: Empower Vision-Language Models as Multimodal Search Engines},
author={Zhang, Zhixin and Zhang, Yiyuan and Ding, Xiaohan and Yue, Xiangyu},
journal={arXiv preprint arXiv:2410.21220},
year={2024}
}


