ndvr
1.0.0
ニューラル検索ハッカソンで2位?
さまざまなビデオ共有 Web サイトでビデオ データが爆発的に増加し、インターネット上で数十億のビデオが利用できるようになりました。大規模なビデオ データベースからほぼ重複したビデオの検索 (NDVR) を実行することが大きな課題となっています。 NDVR は、大規模なビデオ データベースからほぼ重複したビデオを取得することを目的としています。ここで、ほぼ重複したビデオは、オリジナルのビデオに視覚的に近いビデオとして定義されます。
ユーザーには、注目を集めるために、トレンドの短いビデオをコピーし、拡張バージョンをアップロードするという強いインセンティブがあります。短いビデオの増加に伴い、ほぼ重複した短いビデオを検出する際に新たな困難や課題が生じています。
ここでは、Jina を使用して NDVR の課題を解決するニューラル検索ソリューションを構築しました。
目次

ハードポジティブ候補者のビデオの例。上の列: 側面を染色、カラーフィルター、水洗い。中段: 水平画面が大きな黒マージンのある垂直画面に変更されました。下の行: 回転
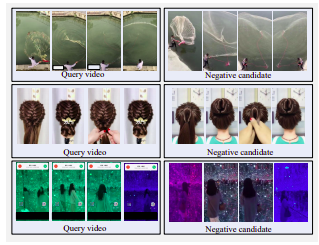
ハードネガティブビデオの例。すべての候補は視覚的にクエリに似ていますが、ほぼ重複していません。
候補ビデオを選択するには 3 つの戦略があります。
時間とリソースの制約により、変換された取得戦略を採用することにしました。実際のアプリケーションでは、ユーザーは個人的なインセンティブを得るために、トレンドのビデオをコピーします。通常、ユーザーはコピーしたビデオをわずかに変更して検出を回避することを選択します。これらの変更には、ビデオのトリミング、境界線の挿入などが含まれます。
このようなユーザーの動作を模倣するために、1 つの時間的変換 (つまり、ビデオの高速化) と 3 つの空間的変換 (つまり、ビデオのトリミング、黒枠の挿入、およびビデオの回転) を定義します。
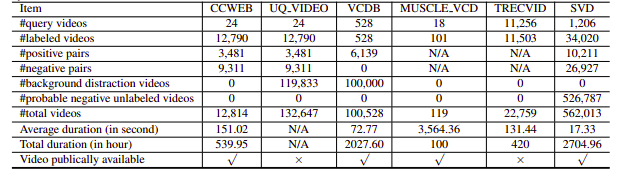
残念ながら、調査対象となった NDVR データセットは、解像度が低かったり、巨大だったり、ドメイン固有だったり、公開されていなかったりしました (個人的に連絡を取ったデータセットも少数でした)。そこで、実験用の小さなカスタム データセットを作成することにしました。
pip install --upgrade -r requirements.txtbash ./get_data.shpython app.py -t indexインデックス フローは次のように定義されます。
!Flow
with :
logserver : false
pods :
chunk_seg :
uses : craft/craft.yml
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
tf_encode :
uses : encode/encode.yml
needs : chunk_seg
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
doc_idx :
uses : index/doc.yml
needs : gateway
join_all :
uses : _merge
needs : [doc_idx, chunk_idx]
read_only : trueこれは次の手順に分かれます。
ここでは、YAML ファイルを使用してフローを定義し、それを使用してデータのインデックスを作成します。 index関数は、ファイル パスを渡すイテレータを取るinput_fnパラメータを受け取ります。ファイル パスはさらにIndexRequestにラップされてフローに送信されます。
DATA_BLOB = "./index-videos/*.mp4"
if task == "index" :
f = Flow (). load_config ( "flow-index.yml" )
with f :
f . index ( input_fn = input_index_data ( DATA_BLOB , size = num_docs ), batch_size = 2 ) def input_index_data ( patterns , size ):
def iter_file_exts ( ps ):
return it . chain . from_iterable ( glob . iglob ( p , recursive = True ) for p in ps )
d = 0
if isinstance ( patterns , str ):
patterns = [ patterns ]
for g in iter_file_exts ( patterns ):
yield g . encode ()
d += 1
if size is not None and d > size :
break python app.py -t queryその後、カスタム エンドポイントhttp://localhost:45678/api/searchを使用して Jinabox を開くことができます。
クエリ フローは次のように定義されます。
!Flow
with :
logserver : true
read_only : true # better add this in the query time
pods :
chunk_seg :
uses : craft/index-craft.yml
parallel : $PARALLEL
tf_encode :
uses : encode/encode.yml
parallel : $PARALLEL
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
polling : all
uses_reducing : _merge_all
timeout_ready : 100000 # larger timeout as in query time will read all the data
ranker :
uses : BiMatchRanker
doc_idx :
uses : index/doc.ymlクエリ フローは次のステップに分かれます。


