CrawlerTutorial
1.0.0
インターネットを閲覧すると、ニュース、製品、ビデオ、写真など、さまざまな興味深いコンテンツが表示されます。しかし、これらの Web ページから特定の情報を大量に収集したい場合、手動での操作は時間と労力がかかります。
そんな時はWebクローラー(Web Crawler)が便利です!簡単に言えば、Web クローラーは人間のブラウザーの動作を模倣し、Web 情報を自動的に巡回できるプログラムです。このプログラムの自動化機能を使用すると、Web サイトから関心のあるデータを簡単に「クロール」し、後の分析のためにこのデータを保存できます。
Web クローラーの通常の動作方法は、まず HTTP リクエストをターゲット Web サイトに送信し、次に Web サイトから HTML 応答を取得し、ページのコンテンツを解析して、有用なデータを抽出することです。たとえば、PTT ゴシップ掲示板の記事のタイトル、著者、時刻、その他の情報を収集したい場合、Web クローラー テクノロジーを使用して、この情報を自動的に取得して保存できます。これにより、Web サイトを手動で閲覧することなく、必要な情報を取得できます。
Web クローラーには、次のような多くの実用的な用途があります。
もちろん、Web クローラーを使用する場合は、Web サイトの利用規約とプライバシー ポリシーに従う必要があり、Web サイトの規制に違反する情報をクロールすることはできません。同時に、Web サイトの正常な動作を保証するために、Web サイトへの過剰な負荷を避けるために適切なクロール戦略を設計する必要もあります。
このチュートリアルでは Python3 を使用し、pip を使用して必要なパッケージをインストールします。次のパッケージをインストールする必要があります。
requests : HTTP リクエストとレスポンスの送受信に使用されます。requests_html : HTML 内の要素の分析とクロールに使用されます。rich : 美しいテーブルを表示するなど、コンソールに情報を美しく出力させます。lxmlまたはPyQuery : HTML 内の要素を解析するために使用されます。これらのパッケージをインストールするには、次の手順を使用します。
pip install requests requests_html rich lxml PyQuery基本章では、PTT Web ページから記事のタイトル、著者、時間などのデータを収集する方法を簡単に紹介します。
PTT のバージョン読み取り記事をクローラーのターゲットとして使用してみましょう。
Web ページをクロールするときは、 requests.get()関数を使用して、Web ページを「閲覧」するために HTTP GET リクエストを送信するブラウザをシミュレートします。この関数は、Web ページの応答コンテンツを含むrequests.Responseオブジェクトを返します。ただし、このコンテンツは純粋なテキスト ソース コードの形式で表示され、ブラウザによってレンダリングされないことに注意してください。これは、 response.textプロパティを通じて取得できます。
import requests
# 發送 HTTP GET 請求並獲取網頁內容
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
response = requests . get ( url )
print ( response . text )
以降の使用では、 requests_html使用してrequestsブラウザのように閲覧するだけでなく、HTML Web ページを解析して、後で使用できるようにrequests_htmlテキストのresponse.textソース コードをrequests_html.HTMLにパッケージ化する必要もあります。書き換えも非常に簡単です。 session.get()使用して上記のrequests.get()を置き換えます。
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text )ただし、この方法をゴシップに適用しようとすると、エラーが発生する可能性があります。これは、私たちが初めてゴシップ掲示板を閲覧するときに、Web サイトで私たちが 18 歳以上であるかどうかを確認するため、クリックして確認すると、ブラウザは対応する Cookie を記録して、次回からは尋ねないようにするためです。 Enter (シークレット モードを使用してテストを開いて、Bagua バージョンのホームページを確認してみてください)。ただし、Web クローラーの場合、ブラウジング中に 18 歳のテストに合格したふりをできるように、この特別な Cookie を記録する必要があります。
import requests
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
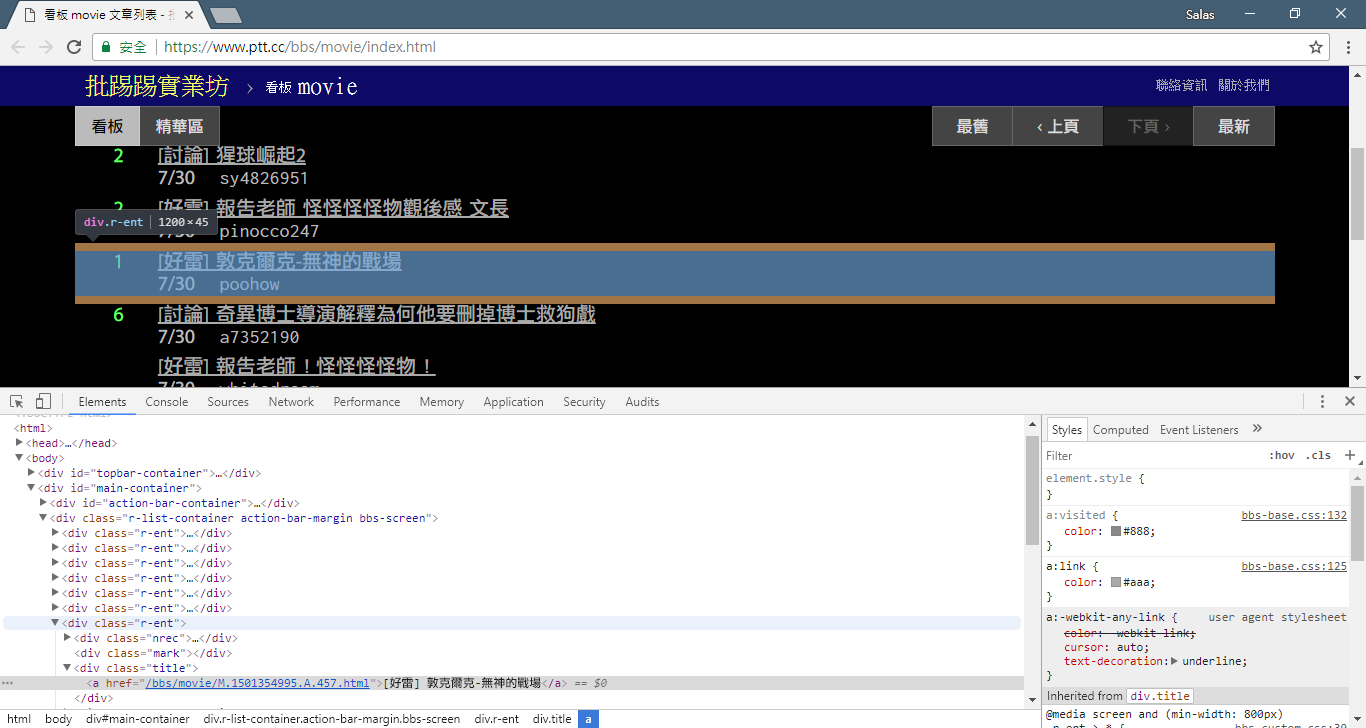
print ( response . text )次に、 response.html.find()メソッドを使用して要素を見つけ、CSS セレクターを使用してターゲット要素を指定します。このステップでは、PTT Web バージョンでは、各記事のタイトル情報がr-entカテゴリを持つdivタグ内に配置されていることがわかります。したがって、CSS セレクターdiv.r-ent使用して、これらの要素をターゲットにすることができます。
response.html.find()メソッドを使用すると、条件を満たす要素のリストが返されるので、 forループを使用してこれらの要素を 1 つずつ処理できます。各要素内では、 element.find()メソッドを使用して要素をさらに解析し、CSS セレクターを使用して抽出する情報を指定できます。この例では、CSS セレクターdiv.title使用して、title 要素をターゲットにできます。同様に、 element.textプロパティを使用して要素のテキスト コンテンツを取得できます。
ここでは、 requests_htmlを使用したサンプルコードを示します。
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
for element in elements :
# 提取資訊... 前のステップでは、 response.html.find()メソッドを使用して各記事の要素を見つけました。これらの要素は、 div.r-ent CSS セレクターを使用してターゲットに設定されます。 開発者ツール機能を使用すると、Web ページの要素構造を観察できます。 Web ページを開いて F12 キーを押すと、Web ページの HTML 構造やその他の情報を含む開発者ツール パネルが表示されます。
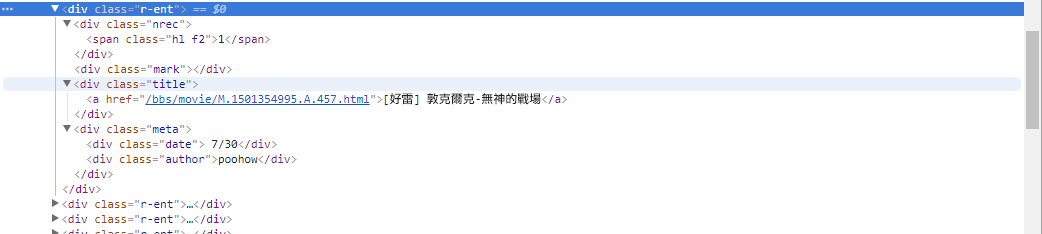
開発者ツールを使用すると、マウス ポインタを使用して Web ページ上の特定の要素を選択し、要素の HTML 構造、CSS 属性、およびその他の詳細を開発者ツール パネルに表示できます。これは、どの要素をターゲットにするか、および対応する CSS セレクターを決定するのに役立ちます。 さらに、プログラムが時々失敗する理由がわかるかもしれません? ! Web 版を見ると、ページ上の記事が削除されたときに、Web ページ上の<本文已被刪除>要素のソース コード結構元のものと異なっていることがわかりました。記事が削除された場合にも対応できるよう、さらに強化していきます。
ここで、 requests_htmlを使用した情報抽出のサンプル コードに戻りましょう。
import re
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
# 逐個處理每個元素
for element in elements :
# 可能會遇上文章已刪除的狀況,所以用例外處理 try-catch 包起來
try :
push = element . find ( '.nrec' , first = True ). text # 推文數
mark = element . find ( '.mark' , first = True ). text # 標記
title = element . find ( '.title' , first = True ). text # 標題
author = element . find ( '.meta > .author' , first = True ). text # 作者
date = element . find ( '.meta > .date' , first = True ). text # 發文日期
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ] # 文章網址
except AttributeError :
# 處理已經刪除的文章資訊
if '(本文已被刪除)' in title :
# e.g., "(本文已被刪除) [haudai]"
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
# e.g., "(已被cappa刪除) <edisonchu> op"
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
print ( '推文數:' , push )
print ( '標記:' , mark )
print ( '標題:' , title )
print ( '作者:' , author )
print ( '發文日期:' , date )
print ( '文章網址:' , link )
print ( '---' )出力ワードプロセッサ:
ここでは、 rich使用して美しい出力を表示できます。まず、 richテーブル オブジェクトを作成し、上記のコード例のループ内のprintテーブルへのadd_rowに置き換えます。最後に、 richのprint関数を使用して、テーブルを端末に正しく出力します。
実行結果
import rich
import rich . table
# 建立 `rich` 表格物件,設定不顯示表頭
table = rich . table . Table ( show_header = False )
# 逐個處理每個元素
for element in elements :
...
# 將每個結果新增到表格中
table . add_row ( push , title , date , author )
# 使用 rich 套件的 print 函式輸出表格
rich . print ( table )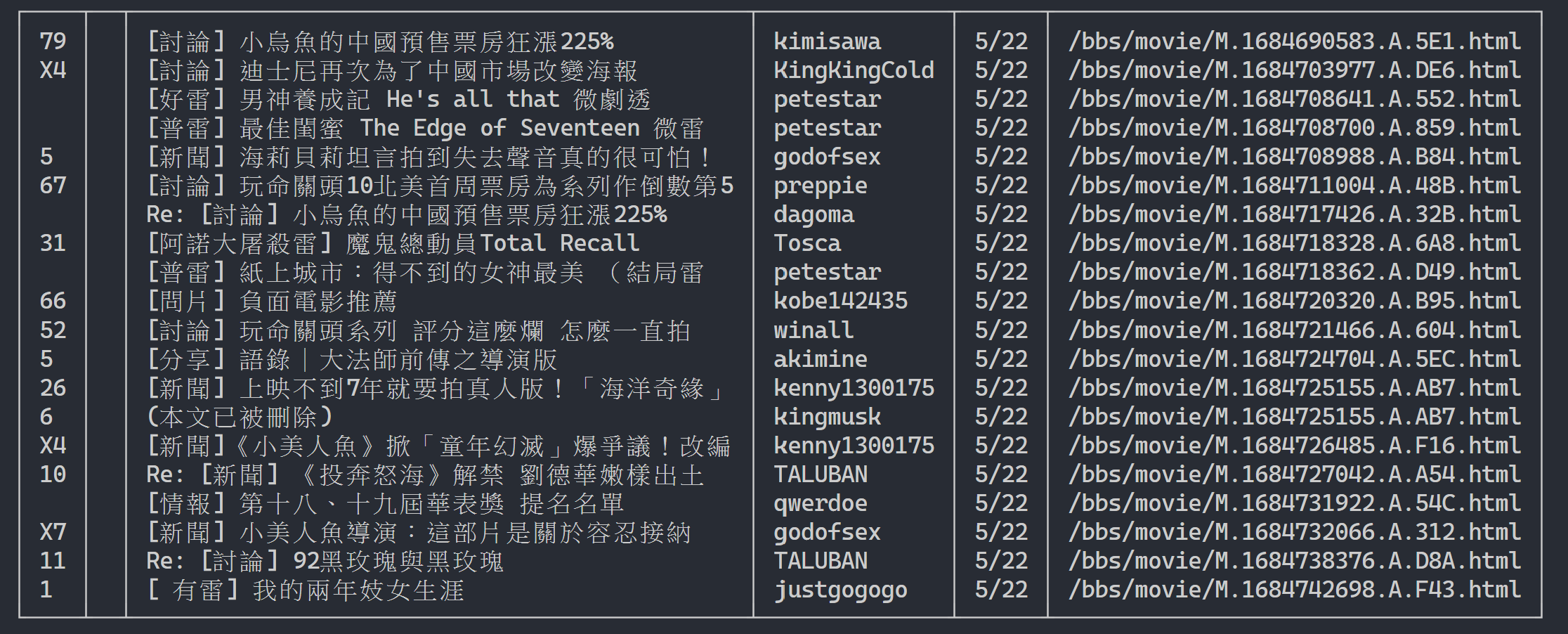
次に、「観察法」を使用して、前のページへのリンクを見つけます。いいえ、私はブラウザ上のボタンがどこにあるかを尋ねているのではなく、開発者ツールの「ソース ツリー」を尋ねています。ページジャンプ用のハイパーリンクが<div class="action-bar">の<a class="btn wide">要素にあることがわかったと思います。したがって、次のように抽出できます。
# 控制頁面選項: 最舊/上頁/下頁/最新
controls = response . html . find ( '.action-bar a.btn.wide' )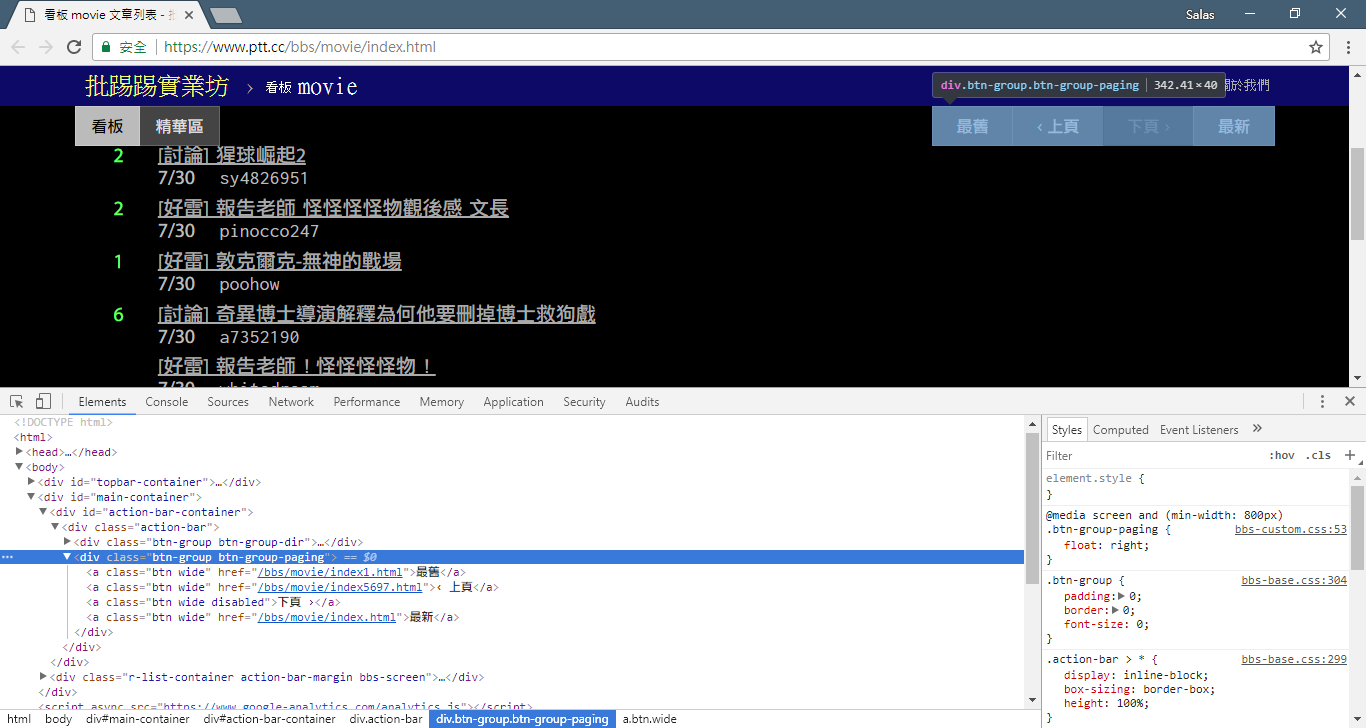
必要なのは「前のページ」機能です。 PTTの最新記事が最前面に表示されるので、情報を掘りたい場合は前にスクロールする必要があります。
では、どうやって使うのでしょうか?まずcontrol内の 2 番目のhref (インデックスは 1) を取得します。次に、これは/bbs/movie/index3237.htmlのようになり、完全な Web サイト アドレス (URL) はhttps://www.ptt.cc/ (ドメイン URL)なので、 urljoin() (または直接文字列接続) を使用して、映画ホームページのリンクと新しいリンクを比較し、完全な URL にマージします。
import urllib . parse
def parse_next_link ( controls ):
link = controls [ 1 ]. attrs [ 'href' ]
next_page_url = urllib . parse . urljoin ( 'https://www.ptt.cc/' , link )
return next_page_url次に、後の説明を容易にするために関数を再配置しましょう。ステップ 3 の各記事要素を処理する例を変更してみましょう。これらのタイトル メッセージを独立した関数parse_article_entries(elements)に見てみましょう。
# 解析該頁文章列表中的元素
def parse_article_entries ( elements ):
results = []
for element in elements :
try :
push = element . find ( '.nrec' , first = True ). text
mark = element . find ( '.mark' , first = True ). text
title = element . find ( '.title' , first = True ). text
author = element . find ( '.meta > .author' , first = True ). text
date = element . find ( '.meta > .date' , first = True ). text
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ]
except AttributeError :
# 處理文章被刪除的情況
if '(本文已被刪除)' in title :
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
# 將解析結果加到回傳的列表中
results . append ({ 'push' : push , 'mark' : mark , 'title' : title ,
'author' : author , 'date' : date , 'link' : link })
return results次に、複数ページのコンテンツを処理できます
# 起始首頁
url = 'https://www.ptt.cc/bbs/movie/index.html'
# 想要收集的頁數
num_page = 10
for page in range ( num_page ):
# 發送 GET 請求並獲取網頁內容
response = session . get ( url )
# 解析文章列表的元素
results = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一個連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 建立表格物件
table = rich . table . Table ( show_header = False , width = 120 )
for result in results :
table . add_row ( * list ( result . values ()))
# 輸出表格
rich . print ( table )
# 更新下面一位 URL~
url = next_page_url出力結果:
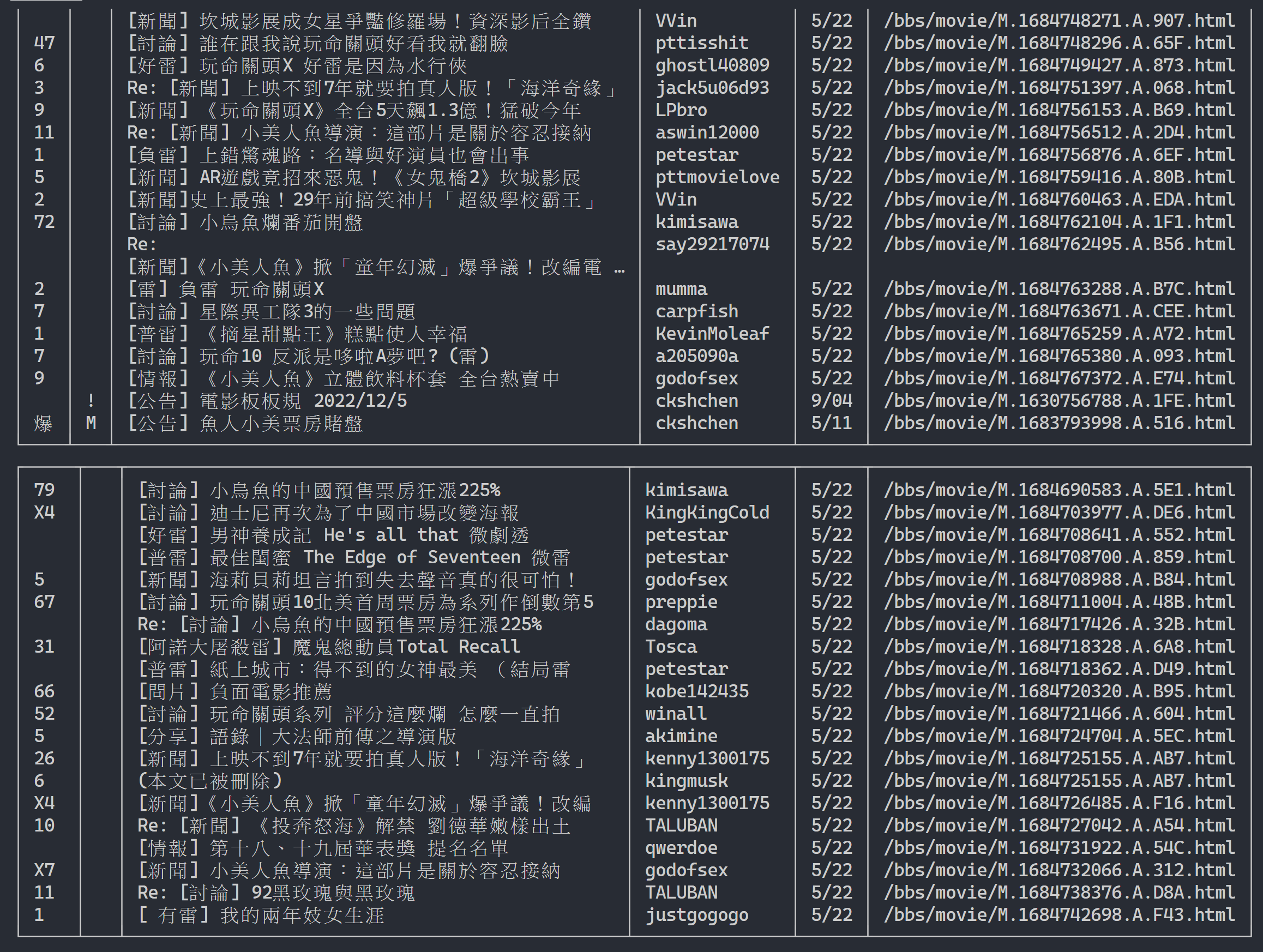
記事一覧情報を取得したら、次は記事(PO記事)のコンテンツ(投稿コンテンツ)を取得します! メタデータ内のlinkは各記事のリンクです。また、 urllib.parse.urljoin使用して完全な URL を連結し、HTTP GET を発行して記事のコンテンツを取得します。 各記事のコンテンツをキャプチャするタスクは非常に反復的であり、並列化手法を使用した処理に非常に適していることがわかります。
Python では、 multiprocessing.Pool使用して高レベルのマルチプロセス プログラミングを実行できます。これは、Python でマルチプロセスを使用する最も簡単な方法です。これは、この SIMD (単一命令複数データ) アプリケーション シナリオに非常に適しています。 withステートメント構文を使用して、使用後にプロセス リソースを自動的に解放します。 ProcessPool の使用法も非常に簡単で、 pool.map(function, items)という関数型プログラミングの概念に似ており、各項目に関数を適用し、最終的に項目と同じ数の結果リストを取得します。
前に紹介した記事コンテンツをクロールするタスクで使用されます。
from multiprocessing import Pool
def get_posts ( post_links ):
with Pool ( processes = 8 ) as pool :
# 建立 processes pool 並指定 processes 數量為 8
# pool 中的 processes 將用於同時發送多個 HTTP GET 請求,以獲取文章內容
responses = pool . map ( session . get , post_links )
# 使用 pool.map() 方法在每個 process 上都使用 session.get(),並傳入文章連結列表 post_links 作為參數
# 每個 process 將獨立地發送一個 HTTP GET 請求取得相應的文章內容
return responses
response = session . get ( url )
# 解析文章列表的元素
metadata = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一頁的連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 一串文章的 URL
post_links = [ urllib . parse . urljoin ( url , meta [ 'link' ]) for meta in metadata ]
results = get_posts ( post_links ) # list(requests_html.HTML)
rich . print ( results ) import time
if __name__ == '__main__' :
post_links = [...]
...
start_time = time . time ()
results = get_posts ( post_links )
print ( f'花費: { time . time () - start_time :.6f }秒,共 { len ( results ) } 篇文章' )実験結果を添付します。
# with 1-process
花費: 15.686177秒,共 202 篇文章
# with 8-process
花費: 3.401658秒,共 202 篇文章全体的な実行速度は 5 倍近く高速化されていることがわかりますが、 Process CPU などのハードウェア仕様に加えて、主にネットワーク カードやネットワーク カードなどの外部デバイスの制限に依存します。ネットワーク速度。
上記のコードは ( src/basic_crawler.py ) にあります。
PTT Web の新機能: 検索!ついにWeb版でも利用可能になりました
映画版の PTT もクローラーのターゲットとして使用してみましょう。新機能で検索できるコンテンツには次のものが含まれます。
最初の 3 つはすべて、新しいバージョンのページのソース コードからルールを見つけてリクエストを送信できますが、ツイート数の検索は Web バージョンの UI インターフェイスには表示されないようなので、作成者がPTT 網站原始碼からマイニングしたパラメーターを次に示します。 PTT 網站原始碼。私たちが普段閲覧している PTT には、実際には BBS サーバー (つまり BBS) とフロントエンド Web サーバー (Web バージョン) が含まれており、フロントエンド Web サーバーは Go 言語 (Golang) で書かれており、バックエンドに直接アクセスできます。 BBS データとその使用 一般的な Web サイト対話モードでは、コンテンツが閲覧用の Web ページにレンダリングされます。
実際、これらの新しい関数の使用は非常に簡単で、 HTTP GETリクエストを使用し、標準のクエリ文字列を追加するだけでこの情報を取得できます。検索機能を提供するendpoint URL は/bbs/{看板名稱}/searchです。ここから検索結果を取得するには、対応するクエリを使用するだけです。まず、タイトルキーワードを例に挙げます。
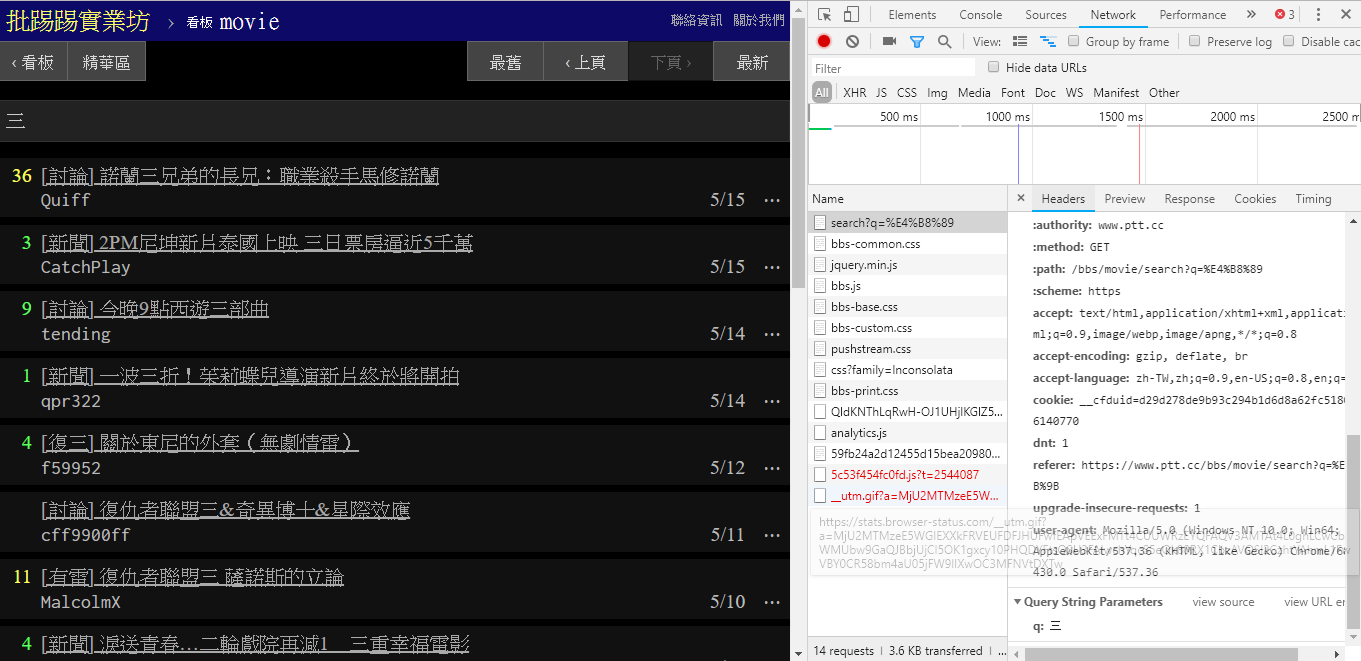
図の右下隅からわかるように、検索時には、 q=三を指定したGETリクエストが実際にendpointに送信されるため、完全な URL 全体はhttps://www.ptt.cc/bbs/movie/search?q=三のようになります。 https://www.ptt.cc/bbs/movie/search?q=三、中国語が使用されているため、アドレス バーからコピーされた URL はhttps://www.ptt.cc/bbs/movie/search?q=%E4%B8%89の形式になる可能性があります。 HTML エンコードされていますが、同じ意味を表します。 requestsで追加のクエリ パラメータを追加したい場合は、手動で文字列フォームを構築する必要はなく、次のようにparam=の dict() を介して関数パラメータに入力するだけです。
search_endpoint_url = 'https://www.ptt.cc/bbs/movie/search'
resp = requests . get ( search_endpoint_url , params = { 'q' : '三' })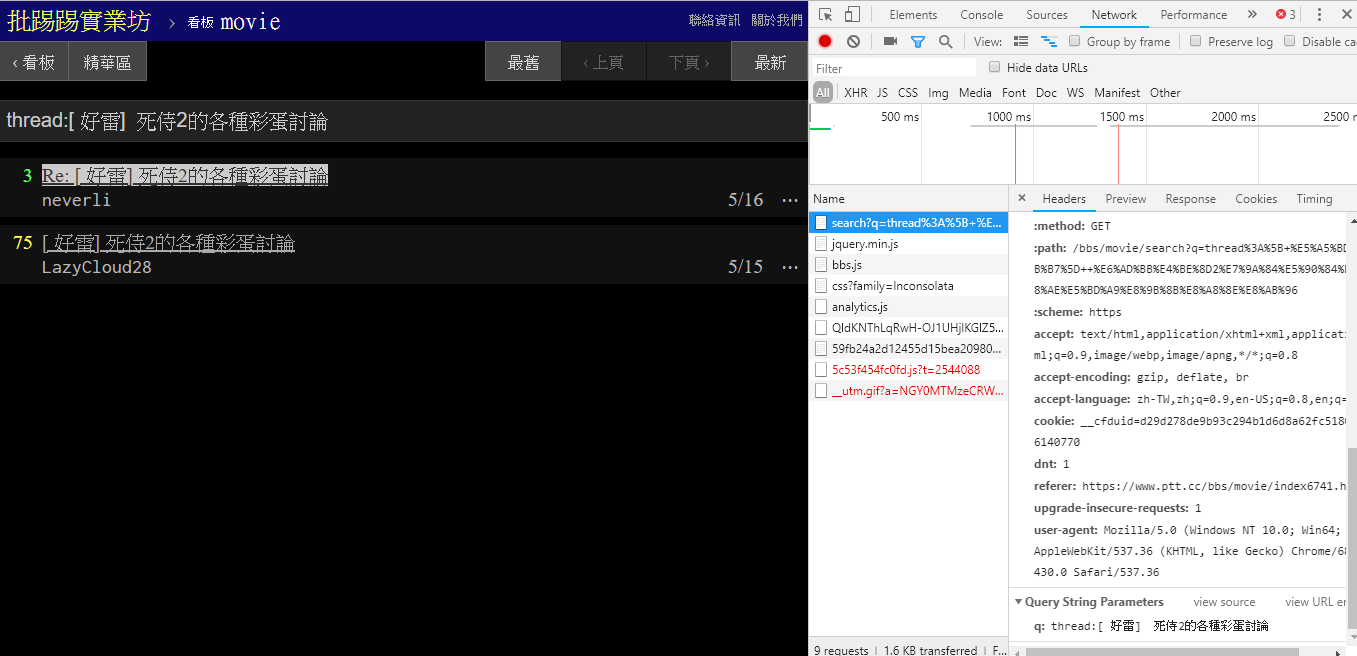
同じ記事 (スレッド) を検索する場合、右下の情報から、実際にはタイトルの前に文字列thread:並べてクエリを送信していることがわかります。
resp = requests . get ( search_endpoint_url , params = { 'q' : 'thread:[ 好雷] 死侍2的各種彩蛋討論' })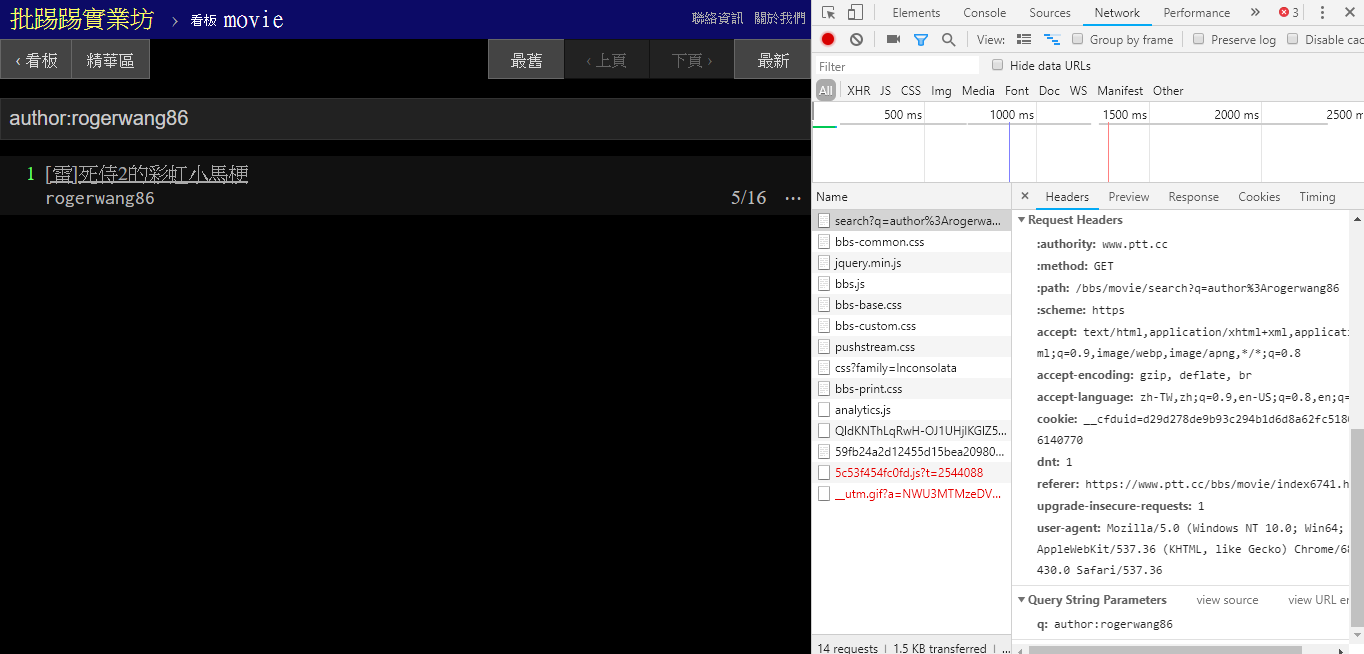
同じ著者(著者)の記事を検索する場合、右下の情報からもauthor:という文字列と著者名を連結してクエリを送信していることがわかります。
resp = requests . get ( search_endpoint_url , params = { 'q' : 'author:rogerwang86' })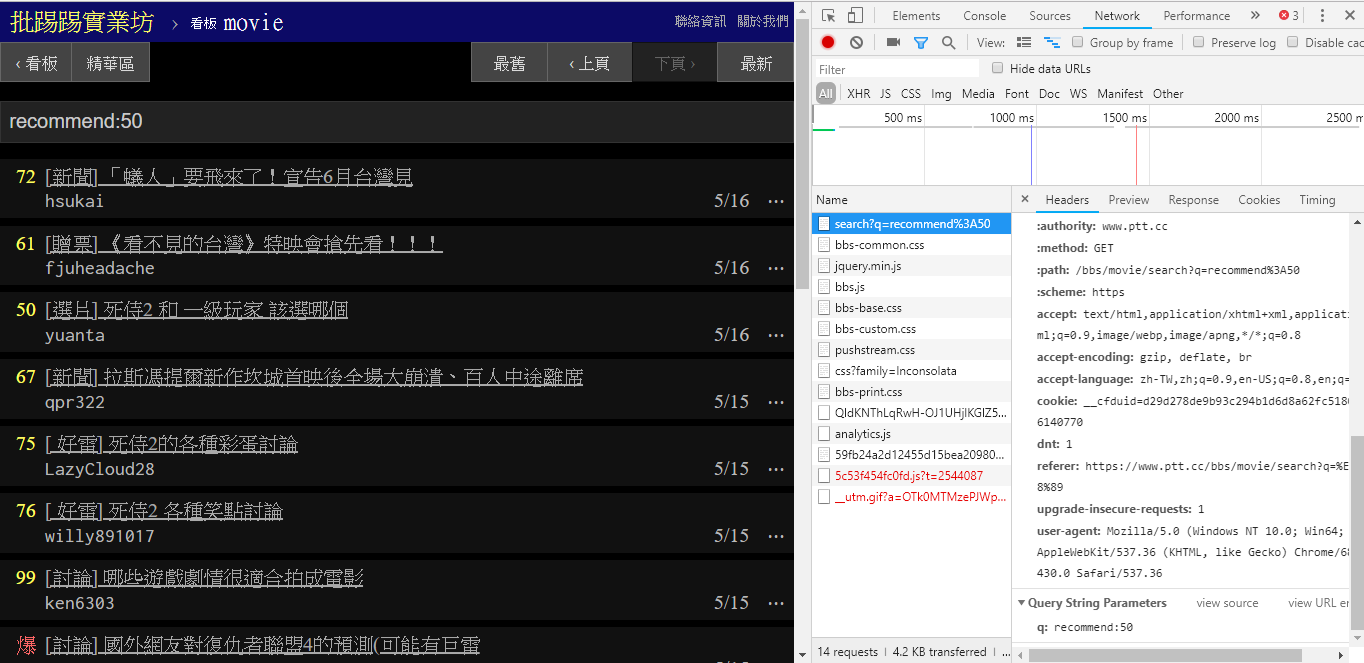
(推奨) を超えるツイート数の記事を検索する場合は、文字列recommend:に検索する最小のツイート数を指定してクエリを送信します。また、PTT Webサーバーのソースコードからツイート数は±100以内でしか設定できないことが分かります。
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })これらのパラメータの PTT Web 解析関数のソース コード
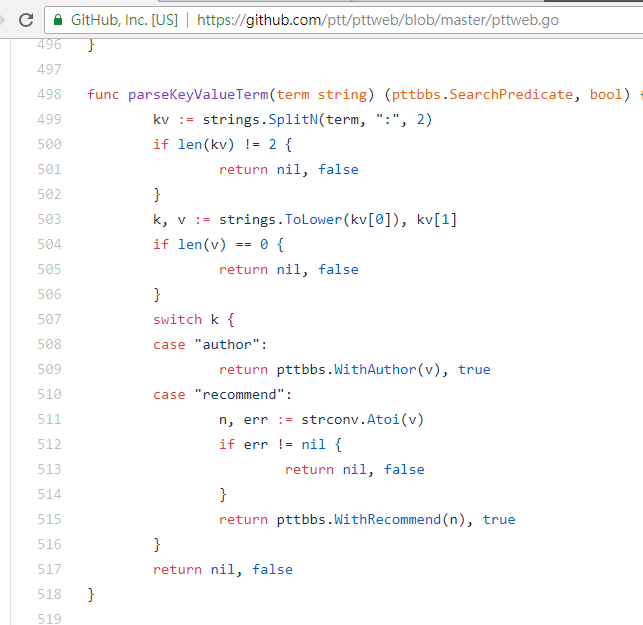
検索結果の最終的な表示は、基本で説明した一般的なレイアウトと同じであるため、以前の機能を直接Don't do it again!利用できることにも注意してください。
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })
post_entries = parse_article_entries ( resp . text ) # [沿用]
metadata = [ parse_article_meta ( entry ) for entry in post_entries ] # [沿用]検索には別のパラメーターがあり、Google 検索と同様に、検索結果に多くのpageが含まれる場合があるため、この追加パラメーターを使用して、リンクを解析せずに取得する結果のページを制御できます。ページ。
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' , 'page' : 2 })以前のすべての機能を ptt-parser に統合すると、プログラムで呼び出すことができる API の形式でコマンドライン関数と爬蟲提供できます。
scrapyを使用して PTT データを安定してクロールします。
この作品は leVirve によって制作され、クリエイティブ コモンズ表示 4.0 国際ライセンスに基づいてリリースされています。


