fine grained sentiment app streamlit
1.0.0
このリポジトリには、既存のインタラクティブ アプリケーションに相当する Streamlit が含まれており、この中シリーズで詳細に説明されている、きめ細かいセンチメント分類の結果を説明します。
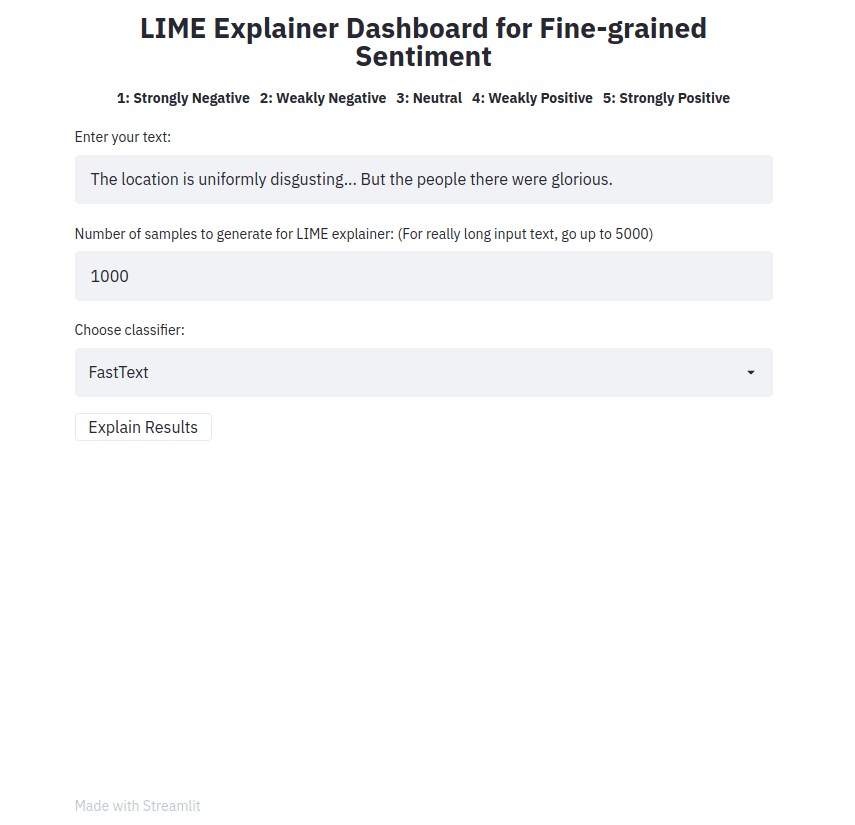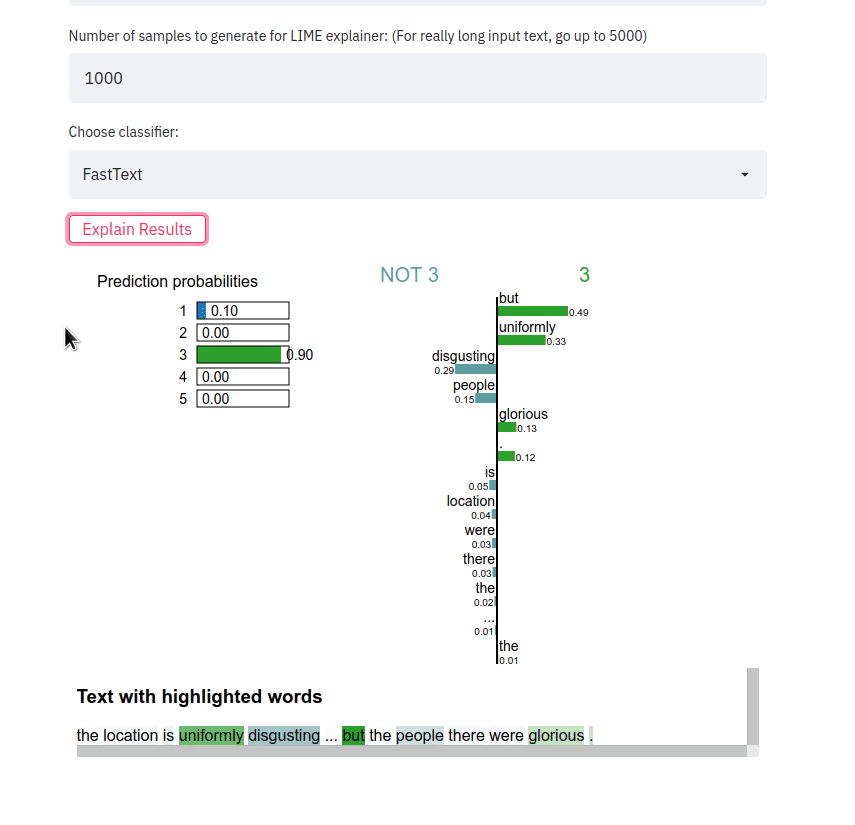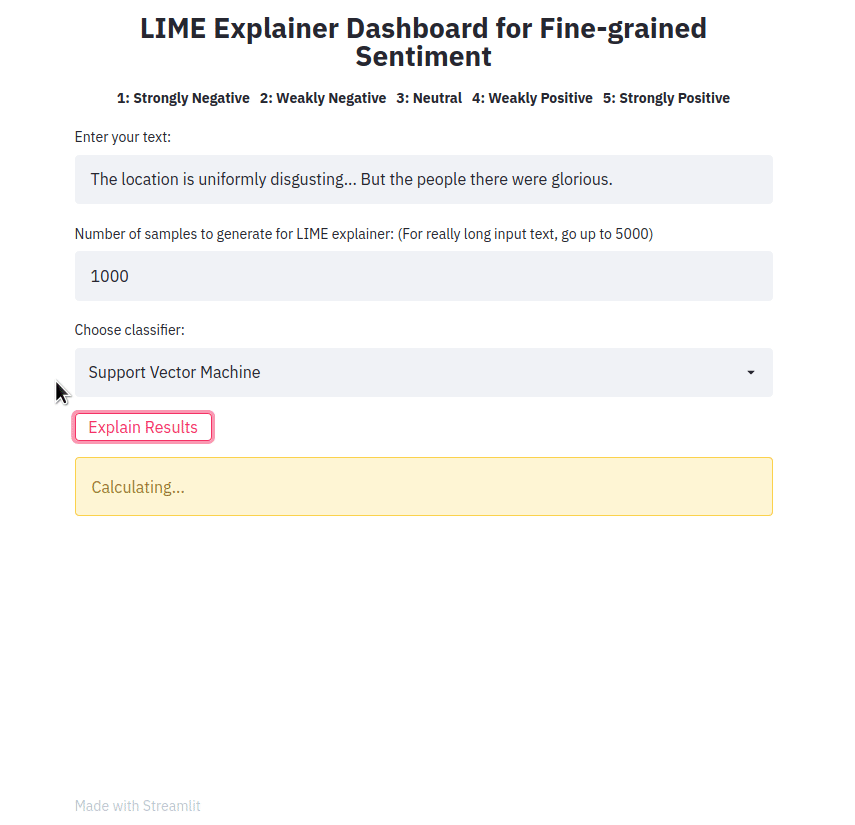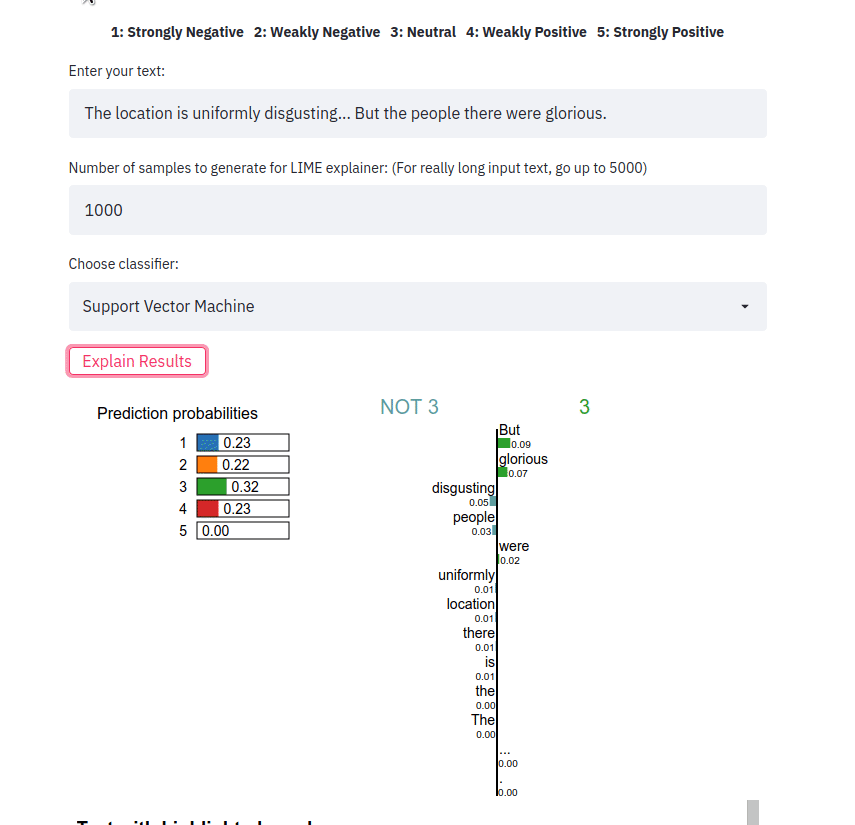
多数の分類子が実装されており、その結果は LIME エクスプローラーを使用して説明されます。分類者は Stanford Sentiment Treebank (SST-5) データセットでトレーニングされました。クラス ラベルは[1, 2, 3, 4, 5]のいずれかです。1 1非常に負で、 5非常に正です。
Streamlit は、Python でダッシュボードを構築するための軽量で最小限のフレームワークです。 Streamlit の主な焦点は、開発者ができるだけ少ないコード行で UI デザインのプロトタイプを迅速に作成できるようにすることです。バックエンド サーバーとそのルートの定義、HTTP リクエストの処理など、Web アプリケーションのデプロイに通常必要となるすべての重労働は、ユーザーから抽象化されます。その結果、開発者の経験に関係なく、Web アプリを迅速に実装することが非常に簡単になります。
まず、仮想環境をセットアップし、 requirements.txtからインストールします。
python3 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt
さらに開発するには、既存の仮想環境をアクティブ化するだけです。
source venv/bin/activate
仮想環境をセットアップしてアクティブ化したら、以下のコマンドを使用してアプリを実行します。
streamlit run app.py文を入力し、分類子の種類を選択して、 Explain resultsボタンをクリックします。その後、特定のクラス ラベルを予測する分類器に寄与した特徴 (つまり、単語またはトークン) を観察できます。
フロントエンド アプリはテキスト サンプルを取得し、さまざまなメソッドの LIME 説明を出力します。アプリは Heroku を使用して次の場所にデプロイされます: https://sst5-explainer-streamlit.herokuapp.com/
以下に示すように独自のテキスト例を試して、詳細な感情結果の説明を確認してください。
注: PyTorch ベースのモデル (Flair および因果変換器) は推論を実行するには非常に高価であるため (GPU が必要)、これらのメソッドはデプロイされていません。ただし、アプリのローカル インスタンス上で実行することはできます。