pianola
1.0.0
 ピアノラの動作" style="max-width: 100%;">
ピアノラの動作" style="max-width: 100%;">
pianola 、AIが生成したピアノ音楽を演奏するアプリです。ユーザーは、キーボードで音を弾いたり、古典作品からサンプル スニペットを選択したりすることで、AI モデルをシード (つまり「プロンプト」) します。
この Readme では、AI がどのように機能するかを説明し、モデルのアーキテクチャについて詳しく説明します。
音楽は、生のオーディオ波形から半構造化された MIDI 標準に至るまで、さまざまな方法で表現できます。 pianolaでは、音楽のビートを規則的で均一な間隔 (16 分音符/半四分音符など) に分割します。インターバル内で演奏されたノートは同じタイムステップに属しているとみなされ、一連のタイムステップがシーケンスを形成します。 AI モデルは、グリッドベースのシーケンスを入力として使用して、次のタイムステップのノートを予測します。これは、自己回帰的に次のタイムステップを予測するための入力として使用されます。
モデルは、演奏するノートに加えて、各ノートのデュレーション(ノートが押されている時間の長さ) とベロシティ(キーを叩く強さ) も予測します。
モデルは、エンベッダー、トランスフォーマー、デコーダーの 3 つのモジュールで構成されています。これらのモジュールは、Inception ネットワーク、LLaMA トランスフォーマー、マルチラベル分類子チェーンなどのよく知られたアーキテクチャを借用していますが、音楽データを処理するように適応されており、新しいアプローチで結合されています。
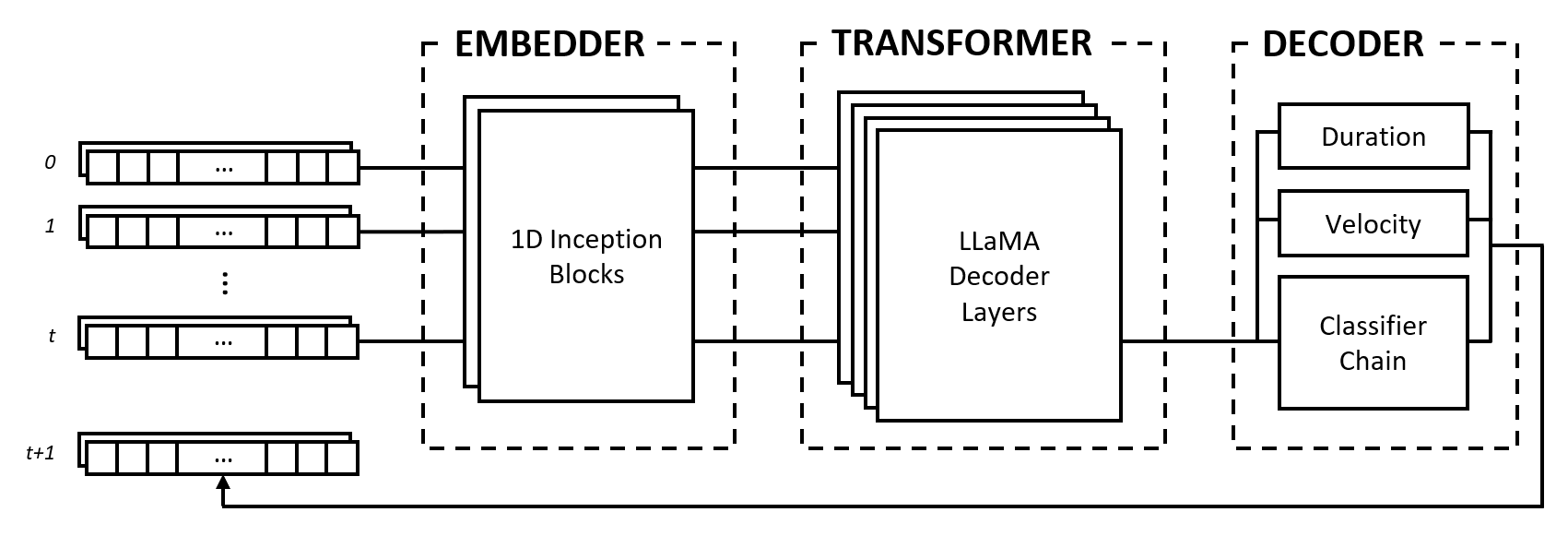
エンベッダーは、形状(num_notes, num_features)の各入力タイムステップを、トランスフォーマーに入力できる埋め込みベクトルに変換します。ただし、ワンホット ベクトルを別の次元空間にマッピングするテキスト埋め込みとは異なり、入力に畳み込み層とプーリング層を適用することで誘導バイアスを提供します。私たちがこれを行うのには、次のような理由があります。
2^num_notes 、ここでnum_notes短いピアノから通常のピアノまでは 64 または 88 です)、したがってそれらをワンホット ベクトルとして表すことはできません。エンベッダーがどの距離が有用かを学習できるようにするために、インセプション ネットワークからインスピレーションを得て、さまざまなカーネル サイズの畳み込みをスタックします。
変換モジュールは、入力埋め込みベクトルのシーケンスに自己注意を適用する LLaMA 変換層で構成されます。
多くの生成 AI モデルと同様に、このモジュールは Vaswani らによるオリジナルのトランスフォーマー モデルの「デコーダー」部分のみを使用します。 (2017年)。ここでは、このモジュールを、セルフ アテンション レイヤーによって生成された状態の実際のデコードを行う次のモジュールと区別するために、「トランスフォーマー」というラベルを使用します。
他のタイプの変換器ではなく LLaMA アーキテクチャを選択した主な理由は、タイムステップによる距離減衰で相対位置をエンコードする回転位置埋め込み (RoPE) を使用するためです。音楽データを固定間隔として表現すると、相対的な位置とタイムステップ間の距離は、トランスフォーマーが一貫したリズムで音楽を理解して生成するために明示的に使用できる重要な情報となります。
デコーダは、参加している状態を取得し、再生されるノートをその持続時間と速度とともに予測します。このモジュールは、いくつかのサブコンポーネント、つまり音符予測用の分類子チェーンと特徴予測用の多層パーセプトロン (MLP) で構成されています。
分類子チェーンは、 num_notesのバイナリ分類子、つまりピアノのキーごとに 1 つで構成され、マルチラベル分類子を作成します。ノート間の相関関係を利用するために、前のノートの結果が次のノートの予測に影響を与えるように、バイナリ分類子が連鎖されます。たとえば、オクターブノート間に正の相関がある場合、アクティブな低いノート (たとえばC3 ) により、高いノート (たとえばC4 ) が予測される可能性が高くなります。これは、負の相関の場合にも有益です。この場合、長音階または短音階 (例: CDEとCD-Eb ) のどちらかが得られる 2 つの隣接する音符のどちらかを選択することができますが、両方ではありません。
計算効率を高めるため、チェーンの長さを 12 リンク、つまり 1 オクターブに制限します。最後に、サンプリング デコード戦略を使用して、予測確率に応じてノートを選択します。
期間と速度の特徴は回帰問題として扱われ、バニラ MLP を使用して予測されます。特徴はノートごとに予測されますが、ローカリゼーション タスクによる画像分類で使用される損失関数と同様に、アクティブなノートからの特徴損失のみを集計するカスタム損失関数をトレーニング中に使用します。
音楽データをグリッドとして表すという選択には、長所と短所があります。これらの点について、Oore らによって提案されたイベントベースの語彙と比較して説明します。 (2018) は、音楽世代において高く評価されている貢献です。
私たちのアプローチの主な利点の 1 つは、音楽のミクロとマクロの理解を切り離すことで、エンベッダーとトランスフォーマーの間の職務の明確な分離につながります。前者の役割は、音符間の相対的な距離がコードのような音楽的関係をどのように形成するかなど、音符の相互作用をミクロレベルで解釈することであり、後者の役割は、この情報を時間次元にわたって総合して音楽スタイルをマクロで理解することです。レベル。
対照的に、イベントベースの表現では、ピッチ、タイミング、速度という 3 つの異なる概念を表すワンホット トークンを解釈するという負担全体がシーケンス モデルに課されます。黄ら。 (2018) は、一貫した継続を生成するには、Transformer モデルに相対的な注意メカニズムを追加する必要があることを発見しました。これは、モデルがこの表現で適切に機能するには、誘導バイアスが必要であることを示唆しています。
グリッド表現では、間隔の長さの選択は、データの忠実性とスパース性の間のトレードオフになります。間隔を長くすると、音符のタイミングの粒度が低下し、音楽の表現力が低下し、トリルや反復音符などの素早い要素が圧縮される可能性があります。一方、間隔が短いと、多くの空のタイムステップが導入されるため、スパース性が指数関数的に増加します。これは、シーケンスの長さに制限がある Transformer モデルにとって重大な問題となります。
さらに、音楽データは、時間の経過 ( 1 timestep == X milliseconds ) またはスコアに書かれたもの ( 1 timestep == 1 sixteenth note/semiquaver ) のいずれかでグリッドにマッピングできますが、それぞれ独自のトレードオフがあります。 。イベントベースの表現では、時間の経過をイベントとして指定することで、これらの問題を完全に回避します。
欠点はあるものの、グリッド表現には、 pianolaの開発での作業がはるかに簡単であるという実用的な利点があります。モデルの出力は人間が判読可能であり、タイムステップ数は固定時間に対応しているため、新機能の開発がより迅速になります。
さらに、Transformer モデルのシーケンス長を拡張する研究とハードウェアの継続的な改善により、データの疎性によって引き起こされる問題が徐々に軽減され、2023 年後半の時点では、数万のトークンを処理できる大規模な言語モデルが登場しています。技術が最適化され、強力なハードウェアがより利用しやすくなるにつれて、画像生成の場合と同様に忠実度が向上し続け、AI で生成された音楽の表現力やニュアンスが向上すると私たちは考えています。
このプロジェクトのソース コードは、学術研究と知識の共有を目的として一般に公開されています。明示的に許可が付与されていない限り、すべての権利は作成者が保持します。
Freepik - Flaticon から変更されたサイト アイコン。
Outlook.com のアドレスbruce <dot> ckcまでご連絡ください。


