DiSQ Score
1.0.0
私たちの論文の正式な実装: Discursive Socratic Questioning: Evaluating the Faithhood of Language Models' Understanding of Discourse Relations (2024) Yisong Miao 、Hongfu Liu、Wenqiang Lei、Nancy F. Chen、Min-Yen Kan. ACL 2024。
論文PDF: https://yisong.me/publications/acl24-DiSQ-CR.pdf
スライド: https://yisong.me/publications/acl24-DiSQ-Slides.pdf
ポスター: https://yisong.me/publications/acl24-DiSQ-Poster.pdf
git clone [email protected]:YisongMiao/DiSQ-Score.git
conda activate
cd DiSQ-Score
cd scripts
pip install -r requirements.txt
言語モデルのDiSQ Scoreを知りたいですか?この 1 行コマンドをぜひ使用してください。

HuggingFace モデル ハブでホストされている言語モデル (LM) を評価するための簡略化されたコマンドが提供されています。新しいモデル (特に本稿で調査されていないモデル) にはこれを使用することをお勧めします。
bash scripts/one_model.sh <modelurl>
modelurl変数は、ハグフェイス ハブ内の短縮パスを指定します。たとえば、次のようになります。
bash scripts/one_model.sh meta-llama/Meta-Llama-3-8B
bash ファイルを実行する前に、bash ファイルを編集してローカル HuggingFace キャッシュへのパスを指定してください。
たとえば、scripts/one_model.sh では次のようになります。
#!/bin/bash
# Please define your own path here
huggingface_path=YOUR_PATH
YOUR_PATH Huggingface キャッシュの絶対ディレクトリの場所 (例: /disk1/yisong/hf-cache ) に変更できます。
少なくとも 200GB の空き容量をお勧めします。
出力テキスト ファイルはdata/results/verbalizations/Meta-Llama-3-8B.txtに保存されます。これには以下が含まれます。
=== The results for model: Meta-Llama-3-8B ===
Dataset: pdtb
DiSQ Score : 0.206
Targeted Score: 0.345
Counterfactual Score: 0.722
Consistency: 0.827
DiSQ Score for Comparison.Concession: 0.188
DiSQ Score for Comparison.Contrast: 0.22
DiSQ Score for Contingency.Reason: 0.164
DiSQ Score for Contingency.Result: 0.177
DiSQ Score for Expansion.Conjunction: 0.261
DiSQ Score for Expansion.Equivalence: 0.221
DiSQ Score for Expansion.Instantiation: 0.191
DiSQ Score for Expansion.Level-of-detail: 0.195
DiSQ Score for Expansion.Substitution: 0.151
DiSQ Score for Temporal.Asynchronous: 0.312
DiSQ Score for Temporal.Synchronous: 0.084
=== End of the results for model: Meta-Llama-3-8B ===
=== The results for model: Meta-Llama-3-8B ===
Dataset: ted
DiSQ Score : 0.233
Targeted Score: 0.605
Counterfactual Score: 0.489
Consistency: 0.787
DiSQ Score for Comparison.Concession: 0.237
DiSQ Score for Comparison.Contrast: 0.268
DiSQ Score for Contingency.Reason: 0.136
DiSQ Score for Contingency.Result: 0.211
DiSQ Score for Expansion.Conjunction: 0.268
DiSQ Score for Expansion.Equivalence: 0.205
DiSQ Score for Expansion.Instantiation: 0.194
DiSQ Score for Expansion.Level-of-detail: 0.222
DiSQ Score for Expansion.Substitution: 0.176
DiSQ Score for Temporal.Asynchronous: 0.156
DiSQ Score for Temporal.Synchronous: 0.164
=== End of the results for model: Meta-Llama-3-8B ===
データセットはdata/datasets/dataset_pdtb.jsonおよびdata/datasets/dataset_ted.jsonにある JSON ファイルに保存されます。たとえば、PDTB データセットからインスタンスを 1 つ取り出してみましょう。
"2": {
"Didx": 2,
"arg1": "and special consultants are springing up to exploit the new tool",
"arg2": "Blair Entertainment, has just formed a subsidiary -- 900 Blair -- to apply the technology to television",
"DR": "Expansion.Instantiation.Arg2-as-instance",
"Conn": "for instance",
"events": [
[
"special consultants springing",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
],
[
"special consultants exploit the new tool",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
]
],
"context": "Other long-distance carriers have also begun marketing enhanced 900 service, and special consultants are springing up to exploit the new tool. Blair Entertainment, a New York firm that advises TV stations and sells ads for them, has just formed a subsidiary -- 900 Blair -- to apply the technology to television. "
},
この辞書エントリのフィールドは次のとおりです。
Didx : 談話 ID。arg1およびarg2 : 2 つの引数。DR : 談話関係です。Conn : 談話接続詞。events : ペアのリスト。顕著な信号として予測されたイベントのペアを保存します。context : 談話のコンテキスト。 cd DiSQ-Score
bash scripts/question_generation.sh
この bash ファイルは、 question_generation.pyを呼び出して、さまざまな構成で質問を生成します。
question_generation.pyの引数は次のとおりです。
--dataset : データセット ( pdtbまたはtedを指定します。--modelname : モデルのエイリアスが作成されました。 13b LLaMA2-13B を、 13bchat LLaMA2-13B-Chat を、 vicuna-13bは Vicuna-13B を指します。これらのモデルの特定の URL はdisq_config.pyにあります。--version : 使用するプロンプト テンプレートのバージョンを、オプションv1 、 v2 、 v3 、およびv4で指定します。--paraphrase : 標準の質問を、オプションp1およびp2を使用して言い換えたバージョンに置き換えます。 qa_utils.py呼び出す標準的な関数とは異なり、言い換えられた関数はそれぞれqa_utils_p1.pyおよびqa_utils_p2.pyを呼び出します。--feature : ディスカッションの質問に使用する言語特徴を指定します。言語的特徴には、 conn (談話接続詞) とcontext (談話文脈) が含まれます。過去の QA データには別のスクリプトが必要です。出力は、たとえば、 data/questions/dataset_pdtb_prompt_v1.json構成dataset==pdtbおよびversion==v1の下に保存されます。
このアプローチは自動であり、GitHub リポジトリ内のスペース (追加すると最大 200 MB になる可能性があります) の節約に役立つため、ユーザーには自分で質問を作成するようお願いしています。 bash ファイルを実行できない場合は、質問ファイルについてお問い合わせください。
cd DiSQ-Score
bash scripts/question_answering.sh
この bash ファイルは、 question_answering.py呼び出して、特定のモデルに対して Discursive Socratic Questioning (DiSQ) を実行します。 question_answering.py 、 question_generation.pyからのすべての引数に加えて、次の新しい引数を受け取ります。
--modelurl : 現在構成ファイルにない新しいモデルの URL を指定します。たとえば、「meta-llama/Meta-Llama-3-8B」は LLaMA3-8B モデルを指定し、 modelname引数を上書きします。--hf-path : 大きなモデル パラメーターを保存するパスを指定します。少なくとも 200 GB の空きディスク容量が推奨されます。--device_number : 使用する GPU の ID を指定します。出力は、たとえばdata/results/13bchat_dataset_pdtb_prompt_v1/に保存されます。各質問の予測は、フォルダー内の pickle ファイルに保存されているトークンとその確率のリストです。
注意: Wizard モデルは開発者によって削除されました。これらのモデルを試さないことをお勧めします。 https://huggingface.co/posts/WizardLM/329547800484476 でディスカッション スレッドを確認してください。
cd DiSQ-Score
bash scripts/eval.sh
この bash ファイルはeval.py呼び出して、以前に取得したモデル予測を評価します。
eval.py question_answering.pyと同じパラメータのセットを受け取ります。
指定されたデータセットが PDTB の場合、評価の結果はdisq_score_pdtb.csvに保存されます。
CSV ファイルには次の 20 列があります。
taskcode : テストされる構成を示します (例: dataset_pdtb_prompt_v1_13bchat 。modelname : どの言語モデルをテストするかを指定します。version : プロンプトのバージョンを示します。paraphrase : パラフレーズのパラメータ。feature : どの機能が使用されているかを指定します。Overall : 全体的なDiSQ Score 。Targeted : DiSQ Scoreの 3 つのコンポーネントの 1 つである、ターゲット スコア。Counterfactual : Counterfactual スコア、 DiSQ Scoreの 3 つのコンポーネントの 1 つ。Consistency : 一貫性スコア。DiSQ DiSQ Scoreの 3 つのコンポーネントの 1 つです。Comparison.Concession : この特定の談話関係のDiSQ Score 。プロンプト テンプレートの影響を最小限に抑えるために、バージョン v1 ~ v4 の中から最良の結果を選択することに注意してください。
これを行うために、 eval.py自動的に最良の結果を抽出します。
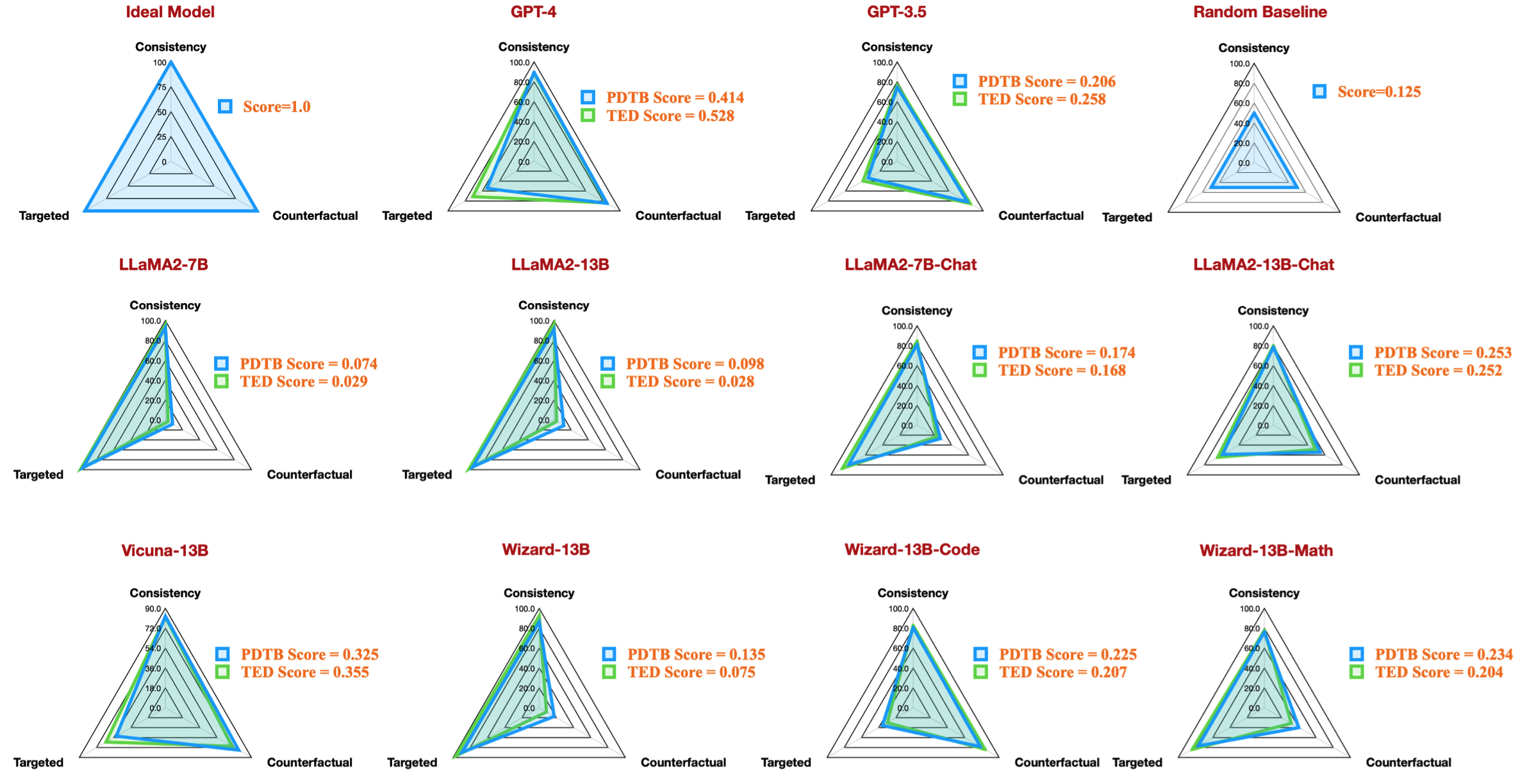
| タスクコード | モデル名 | バージョン | 言い換える | 特徴 | 全体 | ターゲットを絞った | 反事実的 | 一貫性 | 比較.譲歩 | 比較・コントラスト | 偶発的な理由 | 偶発性の結果 | 展開・結合 | 拡張.等価性 | 拡張.インスタンス化 | 展開.詳細レベル | 拡張.置換 | 時間的、非同期 | 時間的同期 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dataset_pdtb_prompt_v4_7b | 7b | v4 | 0.074 | 0.956 | 0.084 | 0.929 | 0.03 | 0.083 | 0.095 | 0.095 | 0.077 | 0.054 | 0.086 | 0.068 | 0.155 | 0.036 | 0.047 | ||
| dataset_pdtb_prompt_v1_7bチャット | 7bチャット | v1 | 0.174 | 0.794 | 0.271 | 0.811 | 0.231 | 0.435 | 0.132 | 0.173 | 0.214 | 0.105 | 0.121 | 0.15 | 0.199 | 0.107 | 0.04 | ||
| データセット_pdtb_prompt_v2_13b | 13b | v2 | 0.097 | 0.945 | 0.112 | 0.912 | 0.037 | 0.099 | 0.081 | 0.094 | 0.126 | 0.101 | 0.113 | 0.107 | 0.077 | 0.083 | 0.093 | ||
| dataset_pdtb_prompt_v1_13bチャット | 13bチャット | v1 | 0.253 | 0.592 | 0.545 | 0.785 | 0.195 | 0.485 | 0.129 | 0.173 | 0.289 | 0.155 | 0.326 | 0.373 | 0.285 | 0.194 | 0.028 | ||
| dataset_pdtb_prompt_v2_vicuna-13b | ビクーニャ-13b | v2 | 0.325 | 0.512 | 0.766 | 0.829 | 0.087 | 0.515 | 0.201 | 0.352 | 0.369 | 0.0 | 0.334 | 0.46 | 0.199 | 0.511 | 0.074 |
たとえば、次の表は、利用可能なオープンソース モデルの PDTB データセットの最良の結果を示しており、論文のレーダー図を再現しています。
また、言語的特徴に関するディスカッションの質問を評価するための手順も提供します。
question_generation.pyでconnおよびcontextとして--featureを指定し (ステップ 1)、すべての実験を再実行します。question_generation_history.pyを実行します。このスクリプトは、保存された QA 結果から回答を抽出し、新しい質問を生成します。ほとんどの NLPer にとって、おそらく既存の仮想 (conda) 環境でコードを実行できるでしょう。
実験を行ったときのパッケージのバージョンは次のとおりです。
torch==2.0.1
transformers==4.30.0
sentencepiece
protobuf
scikit-learn
pandas
ただし、新しいモデルにはアップグレードされたパッケージ バージョンが必要であることが確認されています。
torch==2.4.0
transformers==4.43.3
sentencepiece
protobuf
scikit-learn
pandas
私たちの取り組みに興味を持っていただけましたら、ぜひデータセット/コードベースをお試しください。
私たちのデータセット/コードベースを使用したことがある場合は、私たちの研究を引用してください:
@inproceedings{acl24discursive,
title={Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' Understanding of Discourse Relations},
author={Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, and Min-Yen Kan},
booktitle={Proceedings of the Annual Meeting fof the Association of Computational Linguistics},
month={August},
year={2024},
organization={ACL},
address = "Bangkok, Thailand",
}
ご質問やバグレポートがある場合は、問題を提起するか、電子メールで直接ご連絡ください。
電子メールアドレス: ?@?
ここで、 ?️= yisong 、 ?= comp.nus.edu.sg
CC バイ 4.0


