mlmm evaluation
1.0.0
多言語大規模言語モデルの評価フレームワーク
このリポジトリには、多言語大規模言語モデル (LLM) のベンチマーク データセットと評価スクリプトが含まれています。これらのデータセットは、26 の異なる言語にわたってモデルを評価するために使用でき、ARC、HellaSwag、MMLU という 3 つの異なるタスクを網羅します。これは、人間のフィードバックからの強化学習を使用して、多言語の命令を調整した LLM 用の Okapi フレームワークの一部としてリリースされています。
現在、当社のデータセットは 26 の言語をサポートしています: ロシア語、ドイツ語、中国語、フランス語、スペイン語、イタリア語、オランダ語、ベトナム語、インドネシア語、アラビア語、ハンガリー語、ルーマニア語、デンマーク語、スロバキア語、ウクライナ語、カタロニア語、セルビア語、クロアチア語、ヒンディー語、ベンガル語、タミル語、ネパール語、マラヤーラム語、マラーティー語、テルグ語、カンナダ語。
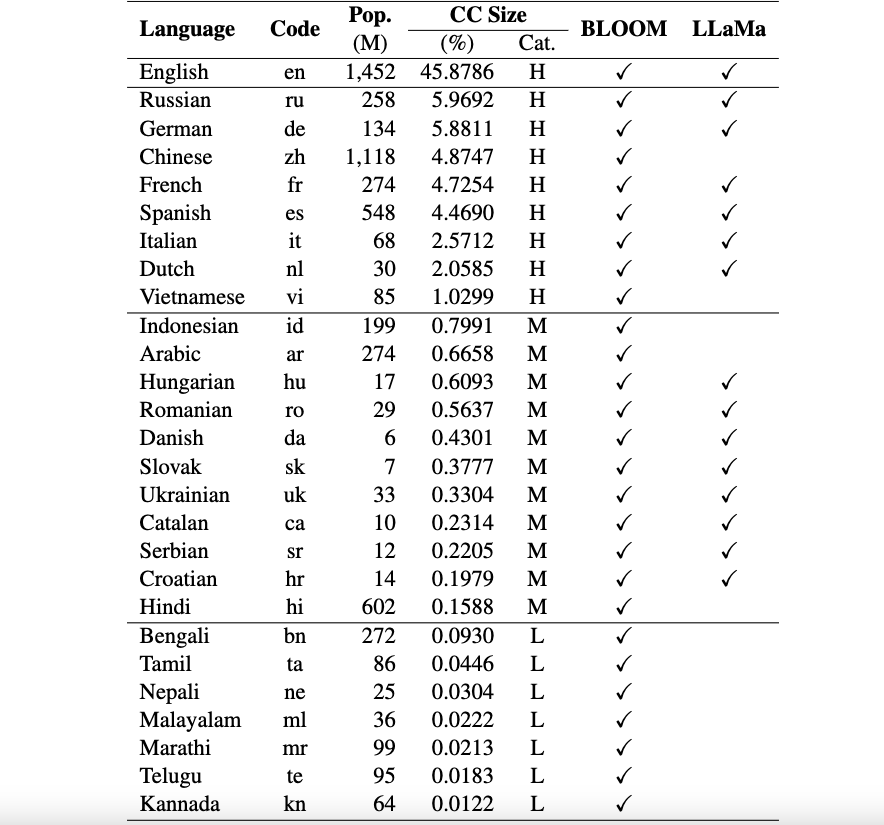
これらのデータセットは、ChatGPT を使用して、英語のオリジナルの ARC、HellaSwag、および MMLU データセットから翻訳されています。いくつかの多言語 LLM (BLOOM、LLaMa、Okapi モデルなど) の評価結果とともにデータセットを説明する、Okapi に関するテクニカル ペーパーは、ここにあります。
使用およびライセンスに関する通知: 当社の評価フレームワークは、研究用途のみを目的としており、ライセンスが付与されています。データセットは CC BY NC 4.0 (非営利使用のみ許可) であり、研究目的以外では使用しないでください。
リポジトリのメイン ブランチからlm-evalインストールするには、次のコマンドを実行します。
git clone https://github.com/nlp-uoregon/mlmm-evaluation.git
cd mlmm-evaluation
pip install -e " .[multilingual] " まず、次のスクリプトを使用して、多言語評価データセットをダウンロードする必要があります。
bash scripts/download.sh3 つのタスクでモデルを評価するには、次のスクリプトを使用できます。
bash scripts/run.sh [LANG] [YOUR-MODEL-PATH]たとえば、Okapi ベトナム語モデルを評価したい場合は、次を実行できます。
bash scripts/run.sh vi uonlp/okapi-vi-bloom私たちは、多言語 LLM の進捗状況を追跡するためのリーダーボードを維持しています。
私たちのフレームワークは主に EleutherAI の lm-evaluation-harness リポジトリから継承しています。コードを使用する場合は、そのリポジトリを引用してください。
このリポジトリ内のデータ、モデル、またはコードを使用する場合は、以下を引用してください。
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

