Grounding_LLMs_with_online_RL
1.0.0
このリポジトリには、論文「オンライン強化学習による大規模言語モデルのグラウンディング」で使用したコードが含まれています。
詳細については、当社の Web サイトをご覧ください。
GLAMメソッドを使用して、BabyAI-Text における LLM の知識の機能的基礎付けを実行します。 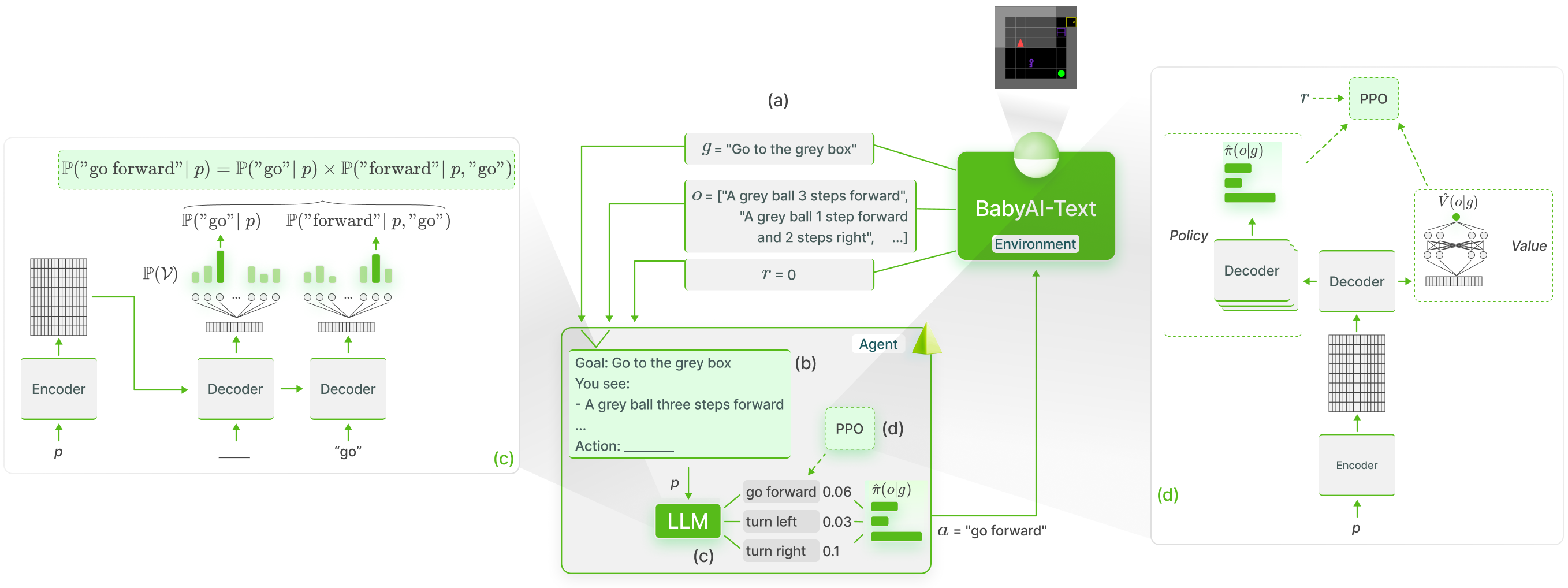
私たちは、実験 (エージェントのトレーニングとそのパフォーマンスの評価の両方) を実行するためのコードとともに、BabyAI-Text 環境をリリースします。 LLM の使用には Lamorel ライブラリを利用しています。
私たちのリポジトリは次のように構造化されています。
? Grounding_LLMs_with_online_RL
⭐ babyai-text --私たちの BabyAI-Text 環境
_____ experiments --実験用のコード
┃ ⁄ agents --すべてのエージェントの実装
┃ ┃ ⁄ bot -- BabyAI のボットを活用したボットエージェント
┃ ┃ ⁄ random_agent --均一にランダムにプレイするエージェント
┃ ┃ ┣ drrn -- DRRN エージェントはここから
┃ ┃ ⁄ ppo -- PPO を使用するエージェント
┃ │ │ `` symbolic_ppo_agent.py -- BabyAI の PPO を基にした SymbolicPPO
llm_ppo_agent.py -- PPO を使用して停止された LLM エージェント
┃ ⁄ configs --実験用の Lamorel 設定
┃ ⁄ slurm -- SLURM クラスター上で実験を開始するための utils スクリプト
┃ ⁄ campaign --実験の開始に使用される SLURM スクリプト
┃ ⁄ train_language_agent.py -- BabyAI-Text (LLM および DRRN) を使用してエージェントをトレーニングします -> LLM の PPO 損失の実装と、LLM 上の追加のヘッドが含まれています
┃ ⁄ train_symbolic_ppo.py -- BabyAI 上で SymbolicPPO をトレーニングします (BabyAI-Text のタスクを使用)
┃ ⁄ post-training_tests.py --訓練されたエージェントの汎化テスト
┃ ⁄ test_results.py --結果をフォーマットするためのユーティリティ
┃ ┗ clm_behavioral-cloning.py --軌跡を使用して LLM 上で Behavioral Cloning を実行するコード
conda create -n dlp python=3.10.8; conda activate dlp
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
BabyAI-Text をインストールする: babyai-textパッケージのインストールの詳細を参照してください。
ラモレルをインストールする
git clone https://github.com/flowersteam/lamorel.git; cd lamorel/lamorel; pip install -e .; cd ../..
Lamorel を構成とともに使用してください。キャンペーンでトレーニング スクリプトの例を見つけることができます。
BabyAI-Text 環境で言語モデルをトレーニングするには、 train_language_agent.pyファイルを使用する必要があります。このスクリプト (Lamorel で起動) は、次の構成エントリを使用します。
rl_script_args :
seed : 1
number_envs : 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
num_steps : 1000 # Total number of training steps
max_episode_steps : 3 # Maximum number of steps in a single episode
frames_per_proc : 40 # The number of collected transitions to perform a PPO update will be frames_per_proc*number_envs
discount : 0.99 # Discount factor used in PPO
lr : 1e-6 # Learning rate used to finetune the LLM
beta1 : 0.9 # PPO's hyperparameter
beta2 : 0.999 # PPO's hyperparameter
gae_lambda : 0.99 # PPO's hyperparameter
entropy_coef : 0.01 # PPO's hyperparameter
value_loss_coef : 0.5 # PPO's hyperparameter
max_grad_norm : 0.5 # Maximum grad norm when updating the LLM's parameters
adam_eps : 1e-5 # Adam's hyperparameter
clip_eps : 0.2 # Epsilon used in PPO's losses clipping
epochs : 4 # Number of PPO epochs performed on each set of collected trajectories
batch_size : 16 # Minibatch size
action_space : ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs : ??? # Where to store logs
name_experiment : ' llm_mtrl ' # Useful for logging
name_model : ' T5small ' # Useful for logging
saving_path_model : ??? # Where to store the finetuned model
name_environment : ' BabyAI-MixedTestLocal-v0 ' # BabiAI-Text's environment
load_embedding : true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads : false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
template_test : 1 # Which prompt template to use to log evolution of action's probability (Section C of our paper). Choices or [1, 2].
nbr_obs : 3 # Number of past observation used in the prompt言語モデル自体に関連する構成エントリについては、Lamorel を参照してください。
テスト タスクでエージェント (トレーニング済み LLM、BabyAI のボットなど) のパフォーマンスを評価するには、 post-training_tests.pyを使用し、次の構成エントリを設定します。
rl_script_args :
seed : 1
number_envs : 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
max_episode_steps : 3 # Maximum number of steps in a single episode
action_space : ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs : ??? # Where to store logs
name_experiment : ' llm_mtrl ' # Useful for logging
name_model : ' T5small ' # Useful for logging
saving_path_model : ??? # Where to store the finetuned model
name_environment : ' BabyAI-MixedTestLocal-v0 ' # BabiAI-Text's environment
load_embedding : true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads : false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
nbr_obs : 3 # Number of past observation used in the prompt
number_episodes : 10 # Number of test episodes
language : ' english ' # Useful to perform the French experiment (Section H4)
zero_shot : true # Whether the zero-shot LLM (i.e. without finetuning should be used)
modified_action_space : false # Whether a modified action space (e.g. different from the one seen during training) should be used
new_action_space : # ["rotate_left","rotate_right","move_ahead","take","release","switch"] # Modified action space
im_learning : false # Whether a LLM produced with Behavioral Cloning should be used
im_path : " " # Path to the LLM learned with Behavioral Cloning
bot : false # Whether the BabyAI's bot agent should be used

