アルパカ-rlhf
RLHF (ヒューマンフィードバックによる強化学習) を使用した LLaMA の微調整。
オンラインデモ
DeepSpeed Chat の変更
ステップ1
- alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- 応答のみをトレーニングし、eos を追加します
- end_of_conversation_token を削除する
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#PromptDataset# getitem
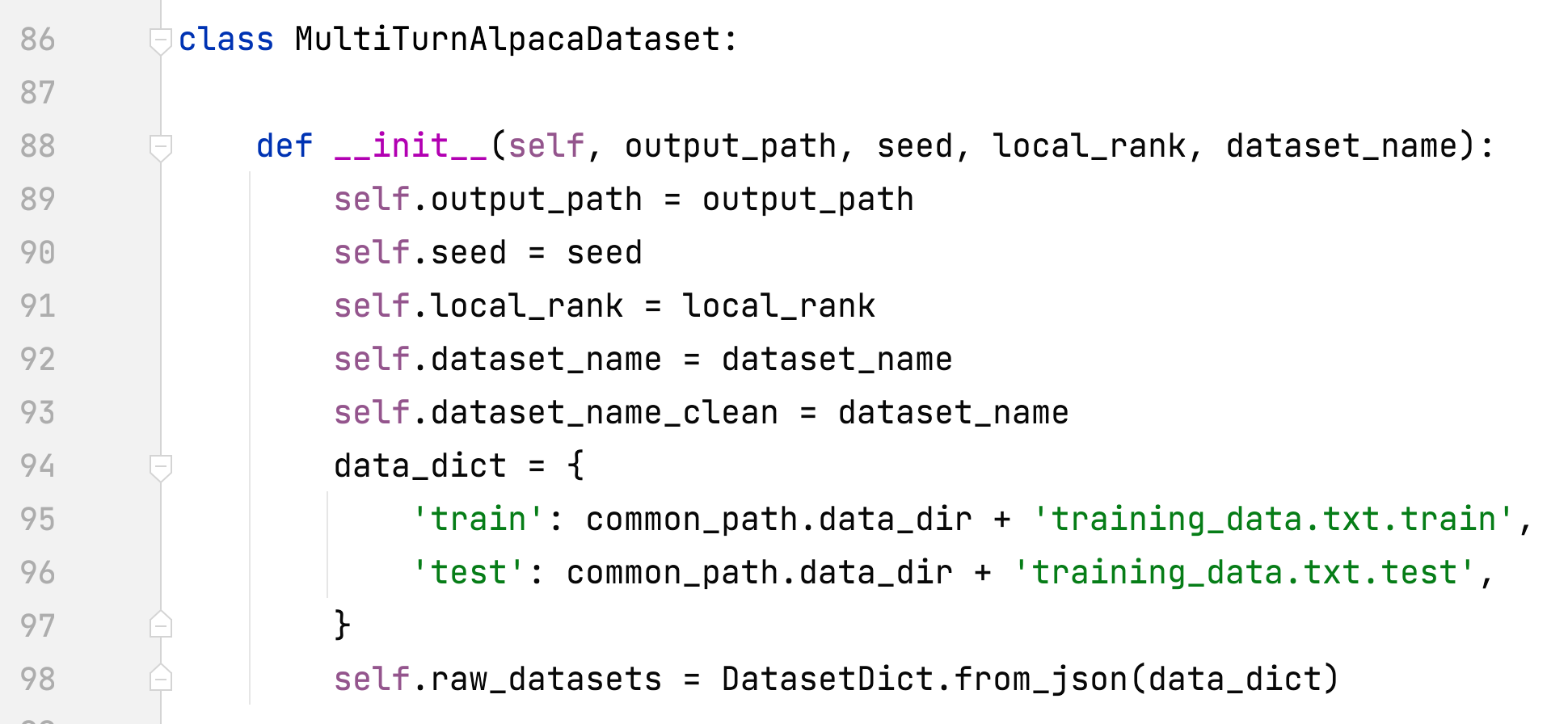
- alpaca_rlhf/deepspeed_chat/training/utils/data/raw_datasets.py#MultiTurnAlpacaDataset
- MultiTurnAlpacaDataset を追加
- alpaca_rlhf/deepspeed_chat/training/utils/module/lora.py#convert_linear_layer_to_lora
ステップ2
- alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/model/reward_model.py#RewardModel#forward()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- end_of_conversation_token を削除する
ステップ3
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#DataCollatorRLHF#呼び出し
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_ experience
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#_generate_sequence
ステイ・バイ・ステップ
- 2 x A100 80G で 3 つのステップすべてを実行
- データセット
- Dahoas/rm-static ハグフェイス ペーパー GitHub
- マルチターンアルパカ
- これはアルパカ データセットのマルチターン バージョンで、AlpacaDataCleaned と ChatAlpaca に基づいて構築されています。
- まず ./alpaca_rlhf ディレクトリに入り、次のコマンドを実行します。
- ステップ 1: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py --sft_only_data_path MultiTurnAlpaca --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b-hf --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --max_seq_len 512 --learning_rate 3e-4 --num_train_epochs 1 --gradient_accumulation_steps 8 --num_warmup_steps 100 --output_dir /root/autodl-tmp/rlhf/actor --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora --deepspeed --zero_stage 2
- --sft_only_data_path MultiTurnAlpaca を追加した場合は、先に data/data.zip を解凍してください。
- ステップ 2: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b -hf --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_eval_batch_size 64 --learning_rate 5e-4 --num_train_epochs 1 --gradient_accumulation_steps 1 --num_warmup_steps 0 --zero_stage 2 --deepspeed --output_dir /root/autodl-tmp/rlhf/critic --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora
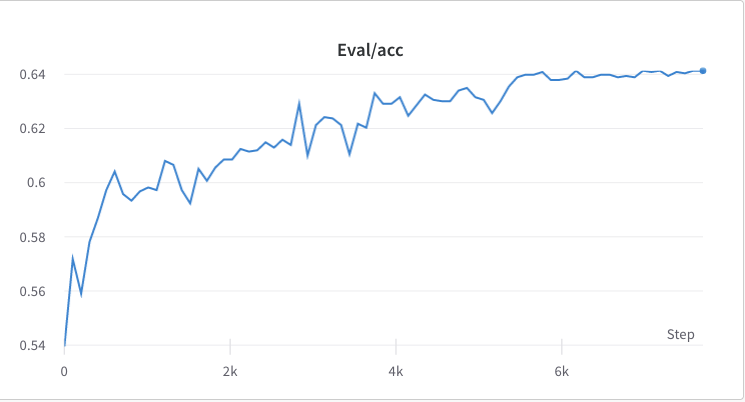
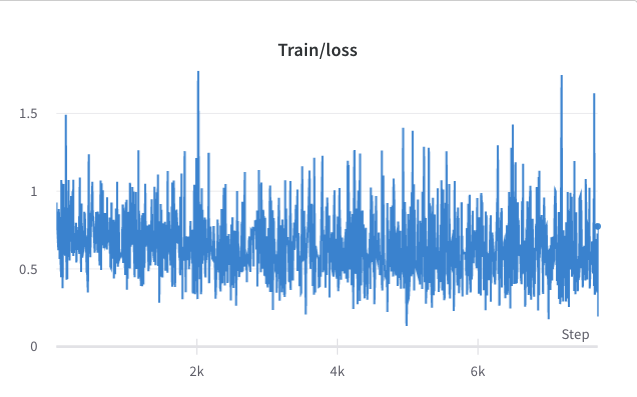
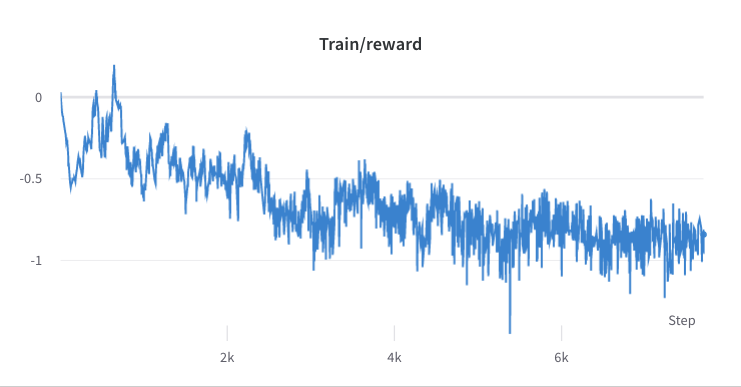
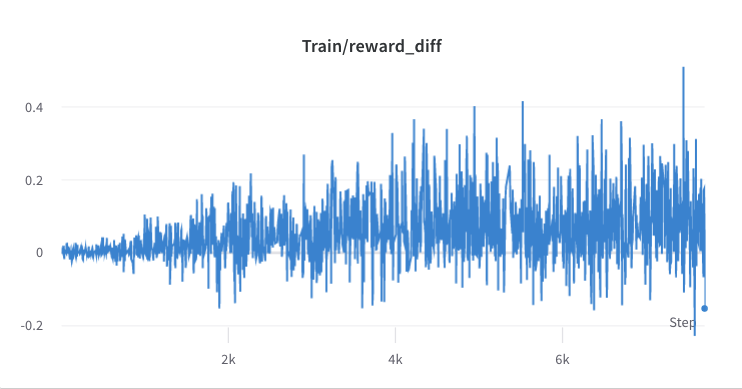
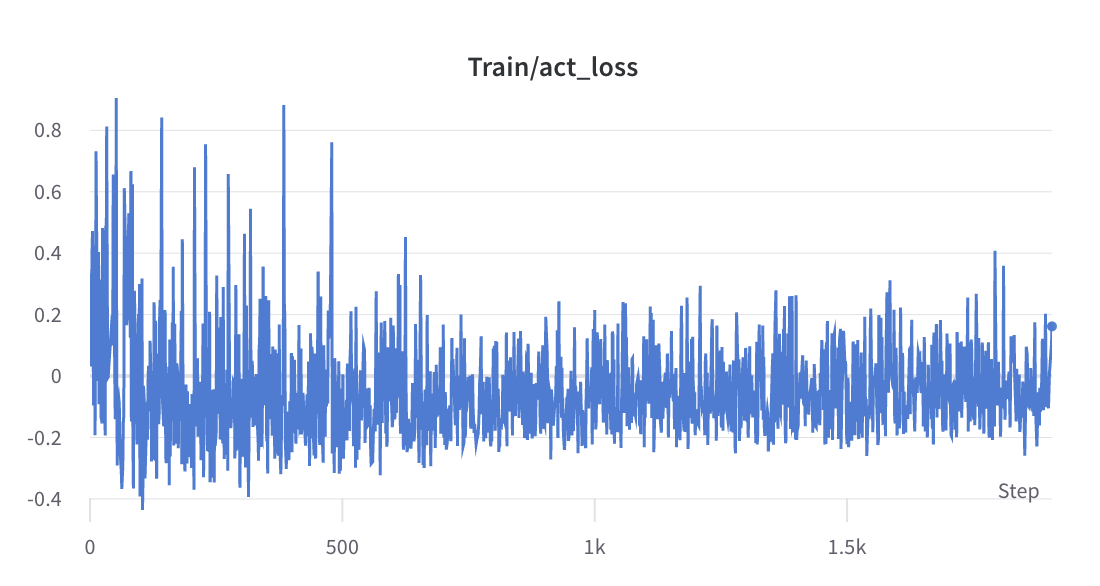
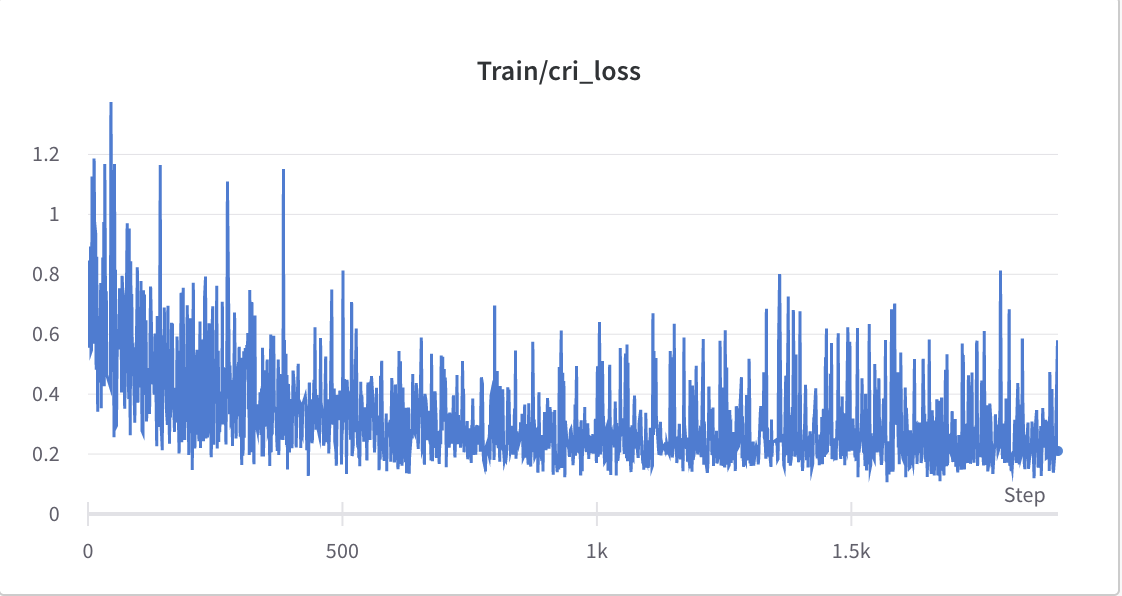
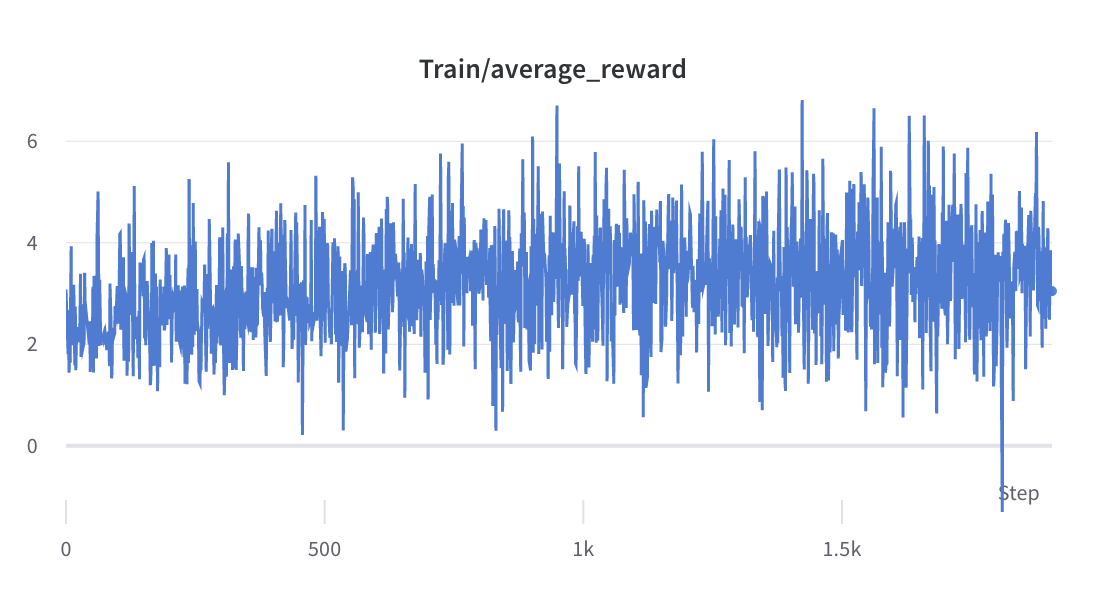
- ステップ2のトレーニングプロセス
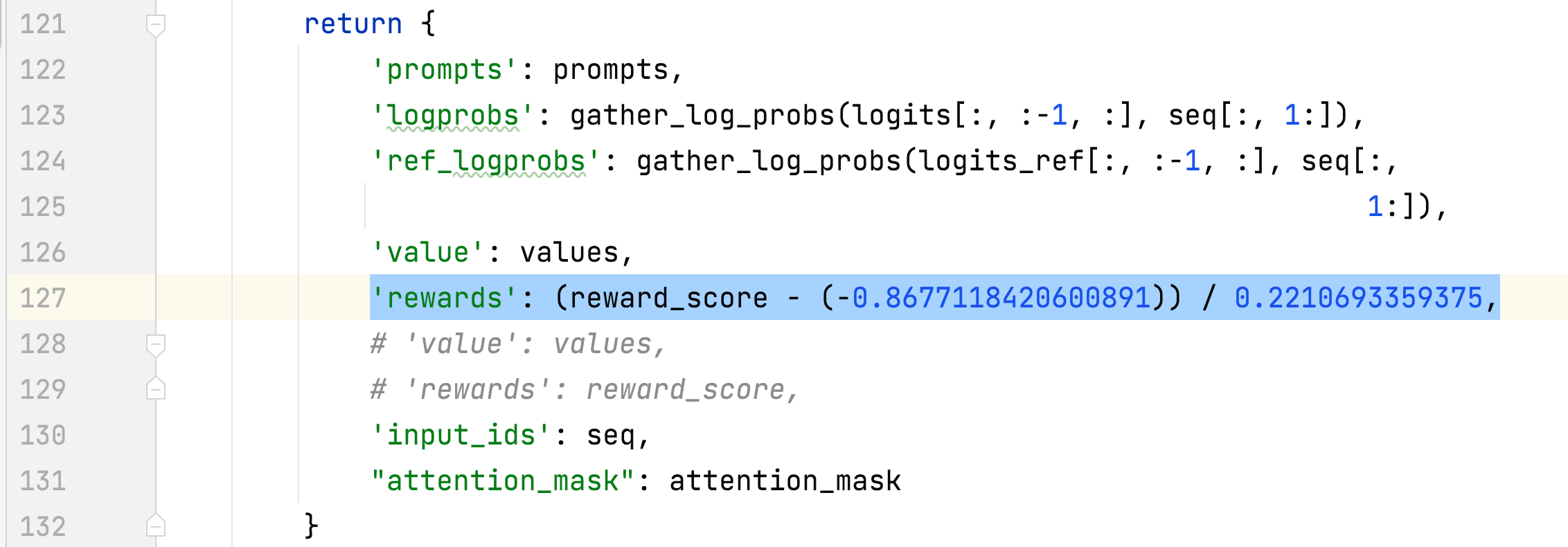
- 選択した応答の報酬の平均偏差と標準偏差が収集され、ステップ 3 で報酬を正規化するために使用されます。ある実験では、それらはそれぞれ -0.8677118420600891 と 0.2210693359375 であり、 alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_ experience メソッド: 'rewards': (reward_score - (-0.8677118420600891)) / 0.2210693359375。
- ステップ 3: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --actor_model_name_or_path /root/autodl-tmp/ rlhf/俳優/ --tokenizer_name_or_path decapoda-research/llama-7b-hf --critic_model_name_or_path /root/autodl-tmp/rlhf/critic --actor_zero_stage 2 --critic_zero_stage 2 --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_mini_train_batch_size 4 --ppo_epochs 2 --actor_learning_rate 9.65e-6 --critic_learning_rate 5e-6 --gradient_accumulation_steps 1 --deepspeed --actor_lora_dim 8 --actor_lora_module_name q_proj --critic_lora_dim 8 --critic_lora_module_name q_proj,k_proj --only_optimize_lora --output_dir /root/autodl-tmp/rlhf/final
- 推論
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/final/actor > rlhf_inference.log 2>&1 &
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/actor > sft_inference.log 2>&1 &
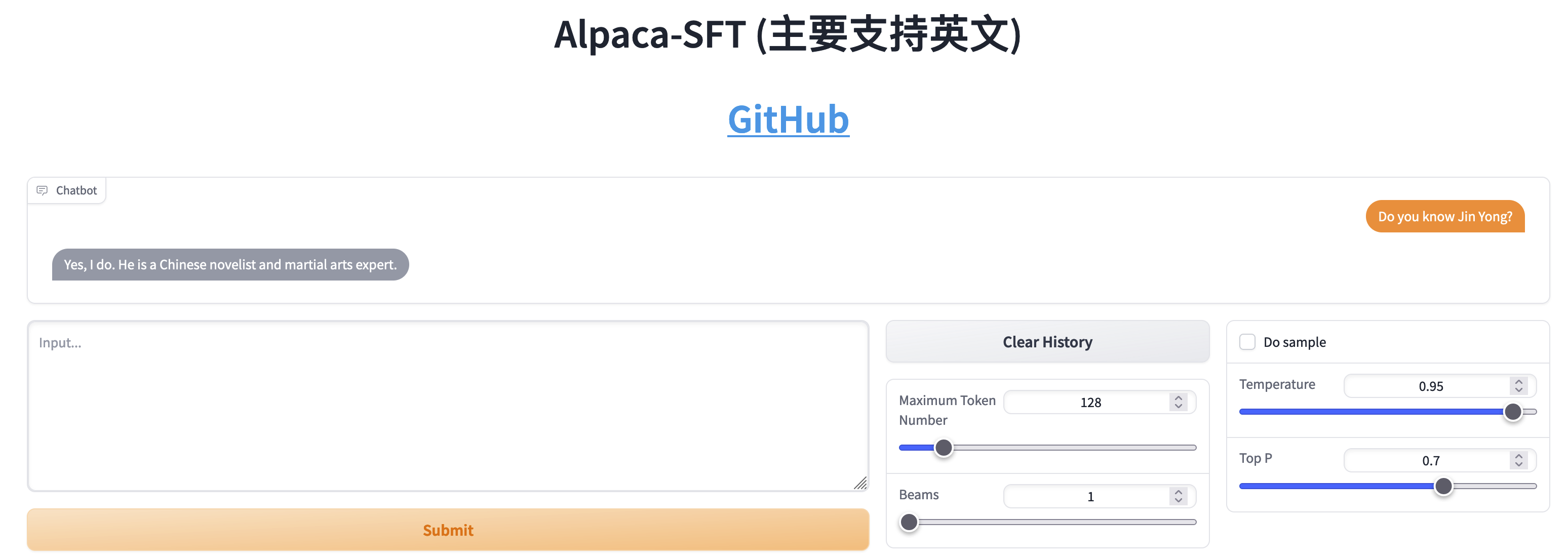
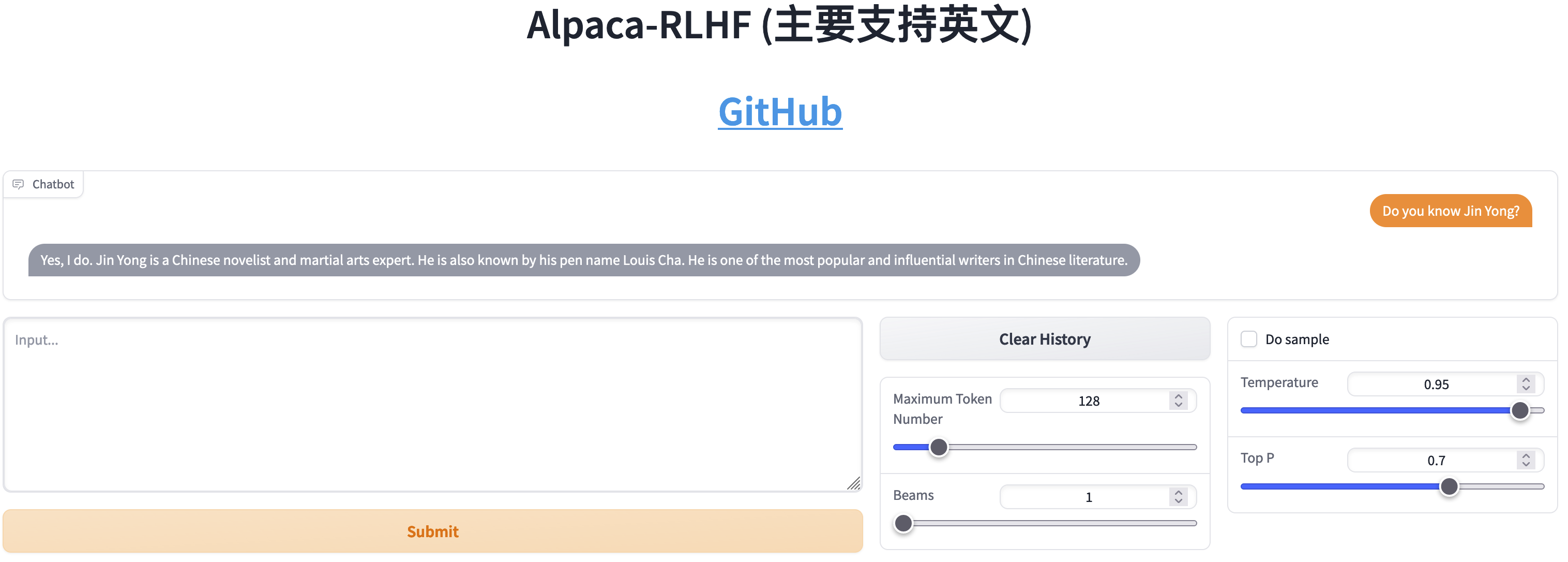
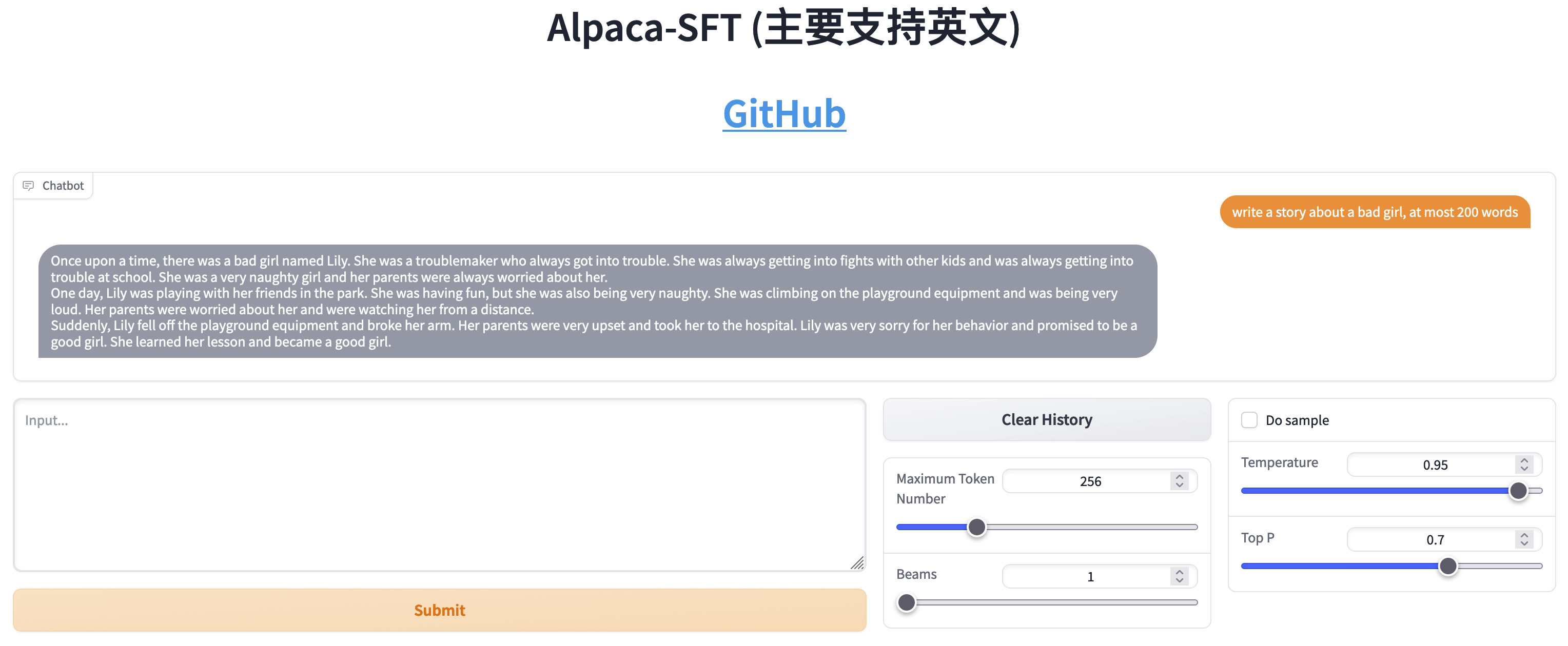
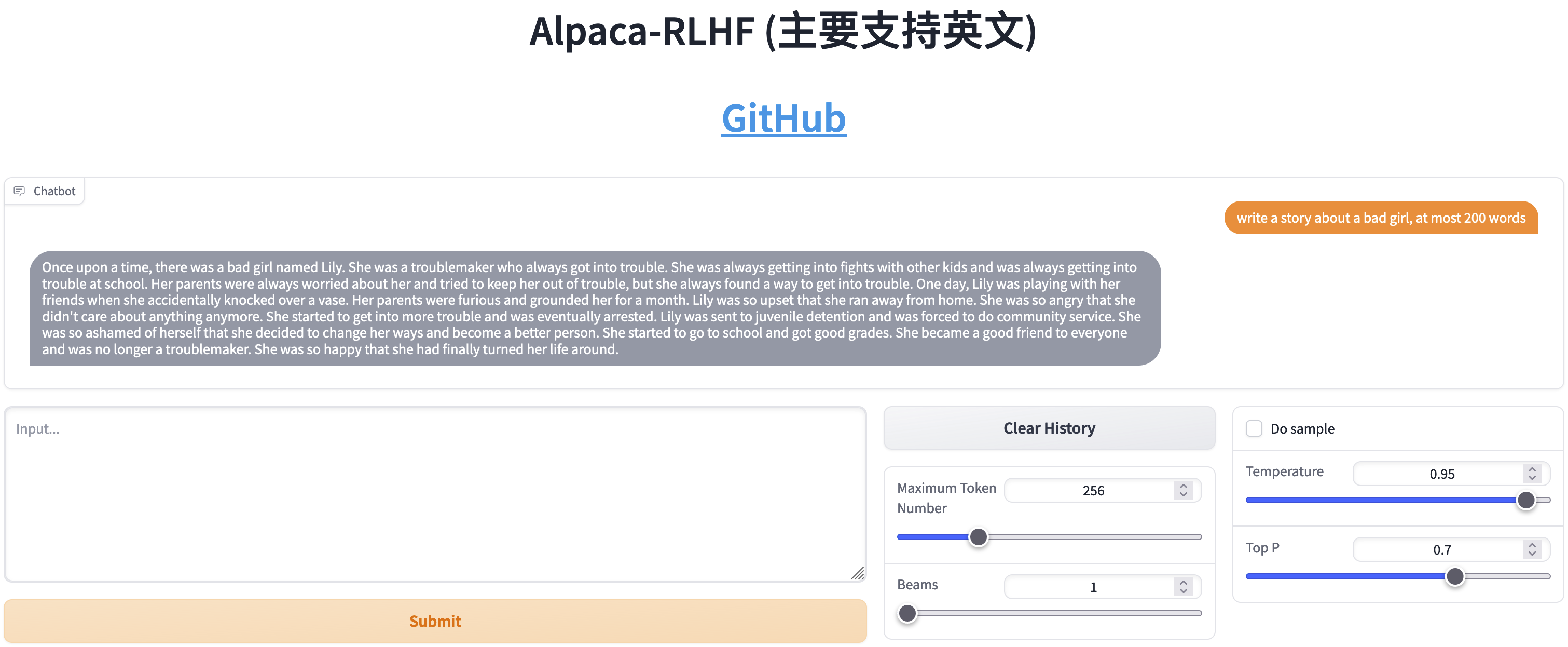
SFTとRLHFの比較
参考文献
記事
- GPT / RLHF をどのように正确复现に指示しますか?
- PPO 演算パフォーマンスに影響を与える 10 個の技術 (付属 PPO 演算法简洁 Pytorch实现)
情報源
ツール
データセット
- スタンフォード人間嗜好データセット (SHP)
- HH-RLHF
- ああ、rlhf
- 人間のフィードバックからの強化学習を使用した有益で無害なアシスタントのトレーニング [論文]
- ダホアス/静的-hh
- ダホアス/rm-static
- GPT-4-LLM
- オープンアシスタント
関連リポジトリ