icl selective annotation
1.0.0
紙のコード 選択的アノテーションにより言語モデルがより良くなる 少数回の学習者
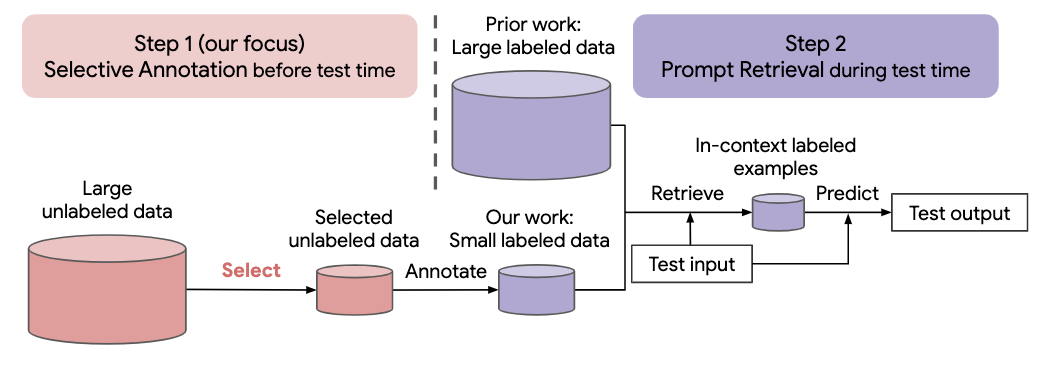
自然言語タスクに対する最近のアプローチの多くは、大規模な言語モデルの優れた能力に基づいて構築されています。大規模な言語モデルは、パラメーターを更新せずに、いくつかのタスクのデモンストレーションから新しいタスクを学習する、コンテキスト内学習を実行できます。この研究では、新しい自然言語タスク用のデータセットの作成に対するコンテキスト内学習の影響を調査します。最近のコンテキスト内学習方法から脱却し、アノテーション効率の高い 2 段階のフレームワークを定式化します。つまり、事前にラベルのないデータからアノテーションを付けるサンプルのプールを選択する選択的アノテーションと、それに続くアノテーション付きプールからタスクのサンプルを取得するプロンプト取得です。テスト時間。このフレームワークに基づいて、注釈を付ける多様な代表的な例を選択するための、教師なしのグラフベースの選択的注釈手法vote-k を提案します。 10 個のデータセットに対する広範な実験 (分類、常識的推論、対話、テキスト/コード生成をカバー) により、選択的アノテーション手法がタスクのパフォーマンスを大幅に向上させることが実証されました。平均して、vote-k は、注釈を付けるサンプルをランダムに選択する場合と比較して、18/100 の注釈予算の下で12.9%/11.4% の相対的な利益を達成します。最先端の教師あり微調整アプローチと比較して、10 個のタスク全体でアノテーション コストが 10 ~ 100 分の 1 に抑えられ、同様のパフォーマンスが得られます。さらに、さまざまなサイズの言語モデル、代替の選択的アノテーション方法、テスト データ ドメインのシフトがあるケースなど、さまざまなシナリオにおけるフレームワークの有効性を分析します。大規模な言語モデルが新しいタスクに適用されることが増えているため、私たちの研究がデータ注釈の基礎として役立つことを願っています。
次のコマンドを実行してこのリポジトリのクローンを作成します
git clone https://github.com/HKUNLP/icl-selective-annotation
環境を確立するには、シェルで次のコードを実行します。
conda env create -f selective_annotation.yml
conda activate selective_annotation
cd transformers
pip install -e .
これにより、使用した環境 selective_annotation が作成されます。
実行して環境をアクティブ化します。
conda activate selective_annotation
インコンテキスト学習モデルとして GPT-J、タスクとして DBpedia、選択的アノテーション方法として vote-k (1 GPU、40 GB メモリ)
python main.py --task_name dbpedia_14 --selective_annotation_method votek --model_cache_dir models --data_cache_dir datasets --output_dir outputs
私たちの仕事が役に立ったと思われる場合は、引用してください
@article{Selective_Annotation,
title={Selective Annotation Makes Language Models Better Few-Shot Learners},
author={Hongjin Su and Jungo Kasai and Chen Henry Wu and Weijia Shi and Tianlu Wang and Jiayi Xin and Rui Zhang and Mari Ostendorf and Luke Zettlemoyer and Noah A. Smith and Tao Yu},
journal={ArXiv},
year={2022},
}


