Phi2 mini Chinese
1.0.0
このプロジェクトは実験的なプロジェクトであり、オープン ソース コードとモデルの重みがあり、より少ない事前トレーニング データが必要な場合は、ChatLM-mini- Chinese プロジェクトを参照してください。
注意
このプロジェクトは実験的なプロジェクトであり、トレーニング データ、モデル構造、ファイル ディレクトリ構造などをいつでも大幅に変更する可能性があります。 モデルの最初のバージョンとtag v1.0を確認してください
たとえば、文末にピリオドを追加する、繁体字中国語を簡体字中国語に変換する、繰り返される句読点を削除する(たとえば、対話資料によっては"。。。。。"が多く含まれる)、NFKC Unicode 標準化(主に完全な中国語の問題)などです。幅を半角に変換、Webページデータu3000 xa0)など。
特定のデータ クリーニング プロセスについては、プロジェクト ChatLM-mini- Chinese を参照してください。
このプロジェクトでは、 byte level BPEトークナイザーを使用します。ワード セグメンタ用に提供されるトレーニング コードには、 char levelとbyte levelの 2 種類があります。
トレーニング後、トークナイザーは、語彙内にt 、 nなどの一般的な特殊記号があるかどうかを忘れずにチェックします。特殊文字を含むテキストのencodeとdecode試して、復元できるかどうかを確認できます。これらの特殊文字が含まれていない場合は、 add_tokens関数を使用して追加します。 len(tokenizer)を使用して語彙サイズを取得します。 tokenizer.vocab_size add_tokens関数によって追加された文字をカウントしません。
トークナイザーのトレーニングは大量のメモリを消費します。
byte level 1 億文字をトレーニングするには、少なくとも32Gのメモリが必要です (実際には、 32Gでは不十分で、スワップが頻繁にトリガーされます)。13600k 13600kトレーニングには約 1 時間かかります。
6 億 5,000 万文字のchar levelトレーニングには少なくとも 32G のメモリが必要です。スワップが複数回トリガーされるため、実際の使用量は 32G をはるかに超えます。13600K 13600Kトレーニングには約半分の時間がかかります。時間。
したがって、データ セットが大きい場合 (GB レベル)、 tokenizerトレーニングするときにデータ セットからサンプリングすることをお勧めします。
教師なし事前トレーニングには大量のテキストを使用します。主に、 bell open sourceのデータ セット BELLE を使用します。
データセット形式: 1 つのサンプルに対して 1 つの文。長すぎる場合は、切り詰めて複数のサンプルに分割することができます。
CLM の事前トレーニング プロセス中、モデルの入力と出力は同じであり、クロスエントロピー損失を計算するときは 1 ビット ( shift ) シフトする必要があります。
百科事典コーパスを処理する場合、各エントリの末尾に'[EOS]'マークを追加することをお勧めします。他のコーパス処理も同様です。 docの終わり (記事の終わりまたは段落の終わり) には'[EOS]'のマークを付ける必要があります。スタートマーク'[BOS]'の有無は選択可能です。
主にbell open sourceのデータセットを使用します。ベル社長、ありがとう。
SFT トレーニングのデータ形式は次のとおりです。
text = f"##提问: n { example [ 'instruction' ] } n ##回答: n { example [ 'output' ][ EOS ]"モデルが損失を計算するとき、 "##回答:"の末尾から始まるマーク"##回答:"より前の部分は無視されます ( "##回答:"も無視されます)。
EOSセンテンス終了特別マークを忘れずに追加してください。そうしないと、モデルをdecodeときにいつ停止するかわかりません。 BOS文の開始マークは、入力することも空白のままにすることもできます。
よりシンプルでメモリを節約する DPO 設定の最適化方法を採用します。
個人の好みに応じて SFT モデルを微調整します。データ セットは、 prompt 、 chosen 、およびrejected 3 つの列を構築する必要があります。 rejected列には、sft ステージのプライマリ モデルからのデータが含まれています (たとえば、 sft は 4 epochをトレーニングし、 0.5 epochチェックポイント モデル) を生成します。生成されたrejectedとchosen類似性が 0.9 を超える場合、このデータは必要ありません。
DPO プロセスには 2 つのモデルがあり、1 つはトレーニング対象のモデル、もう 1 つは参照モデルです。ロード時には、実際には同じモデルですが、参照モデルはパラメーターの更新には関与しません。
モデル ウェイトhuggingfaceリポジトリ: Phi2- Chinese-0.2B
from transformers import AutoTokenizer , AutoModelForCausalLM , GenerationConfig
import torch
device = torch . device ( "cuda" ) if torch . cuda . is_available () else torch . device ( "cpu" )
tokenizer = AutoTokenizer . from_pretrained ( 'charent/Phi2-Chinese-0.2B' )
model = AutoModelForCausalLM . from_pretrained ( 'charent/Phi2-Chinese-0.2B' ). to ( device )
txt = '感冒了要怎么办?'
prompt = f"##提问: n { txt } n ##回答: n "
# greedy search
gen_conf = GenerationConfig (
num_beams = 1 ,
do_sample = False ,
max_length = 320 ,
max_new_tokens = 256 ,
no_repeat_ngram_size = 4 ,
eos_token_id = tokenizer . eos_token_id ,
pad_token_id = tokenizer . pad_token_id ,
)
tokend = tokenizer . encode_plus ( text = prompt )
input_ids , attention_mask = torch . LongTensor ([ tokend . input_ids ]). to ( device ),
torch . LongTensor ([ tokend . attention_mask ]). to ( device )
outputs = model . generate (
inputs = input_ids ,
attention_mask = attention_mask ,
generation_config = gen_conf ,
)
outs = tokenizer . decode ( outputs [ 0 ]. cpu (). numpy (), clean_up_tokenization_spaces = True , skip_special_tokens = True ,)
print ( outs ) ##提问:
感冒了要怎么办?
##回答:
感冒是由病毒引起的,感冒一般由病毒引起,以下是一些常见感冒的方法:
- 洗手,特别是在接触其他人或物品后。
- 咳嗽或打喷嚏时用纸巾或手肘遮住口鼻。
- 用手触摸口鼻,特别是喉咙和鼻子。
- 如果咳嗽或打喷嚏,可以用纸巾或手绢来遮住口鼻,但要远离其他人。
- 如果你感冒了,最好不要触摸自己的眼睛、鼻子和嘴巴。
- 在感冒期间,最好保持充足的水分和休息,以缓解身体的疲劳。
- 如果您已经感冒了,可以喝一些温水或盐水来补充体液。
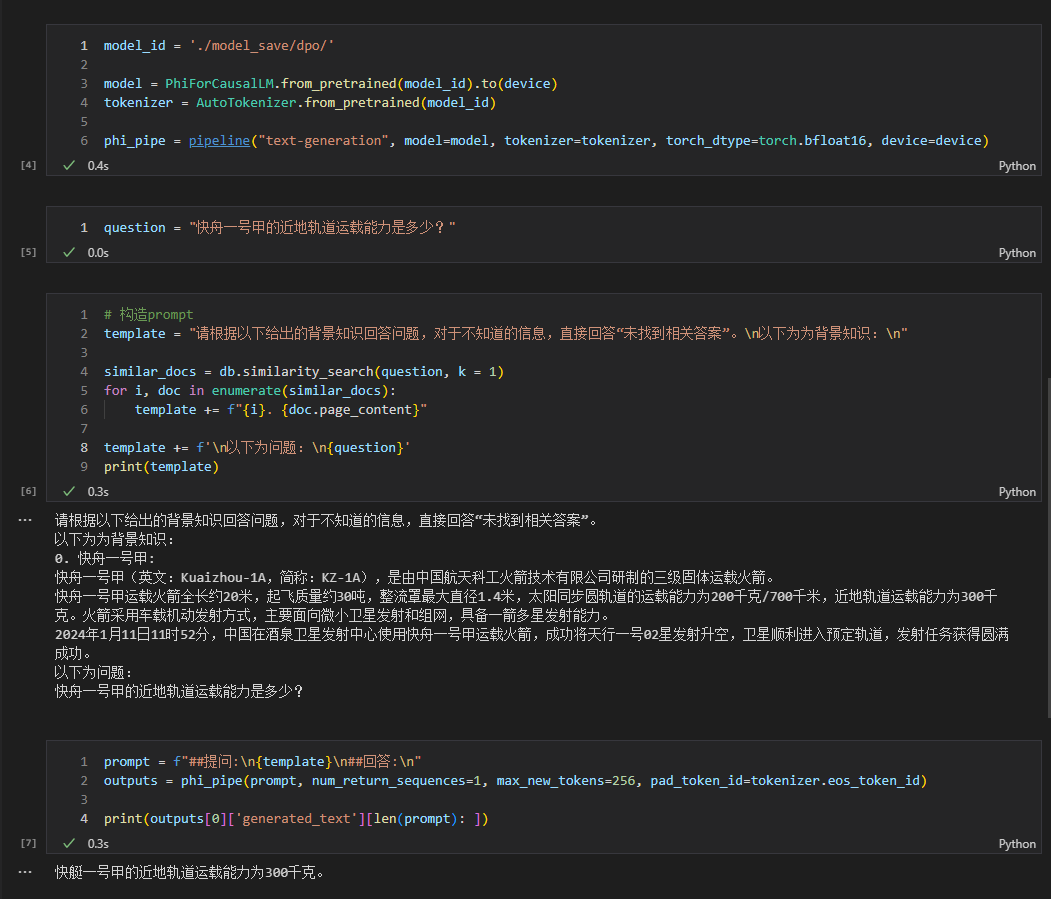
- 另外,如果感冒了,建议及时就医。特定のコードについては、 rag_with_langchain.ipynbを参照してください。
このプロジェクトが役立つと思われる場合は、引用してください。
@misc{Charent2023,
author={Charent Chen},
title={A small Chinese causal language model with 0.2B parameters base on Phi2},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/Phi2-mini-Chinese}},
}
このプロジェクトは、オープンソースのモデルとコードによって引き起こされるデータ セキュリティと世論リスクのリスクと責任、またはモデルが誤解されたり、悪用されたり、広められたり、不適切に利用されたりすることから生じるリスクと責任を負いません。


