aug pe
1.0.0
?論文 • データ (Yelp/OpenReview/PubMed) • プロジェクト ページ
このリポジトリは、Augmented Private Evolution (Aug-PE) アルゴリズムを実装しており、大規模言語モデル (LLM) への推論 API アクセスを利用して、モデルのトレーニングを必要とせずに差分プライベート (DP) 合成テキストを生成します。 DP-SGD 微調整と Aug-PE を比較します。

下
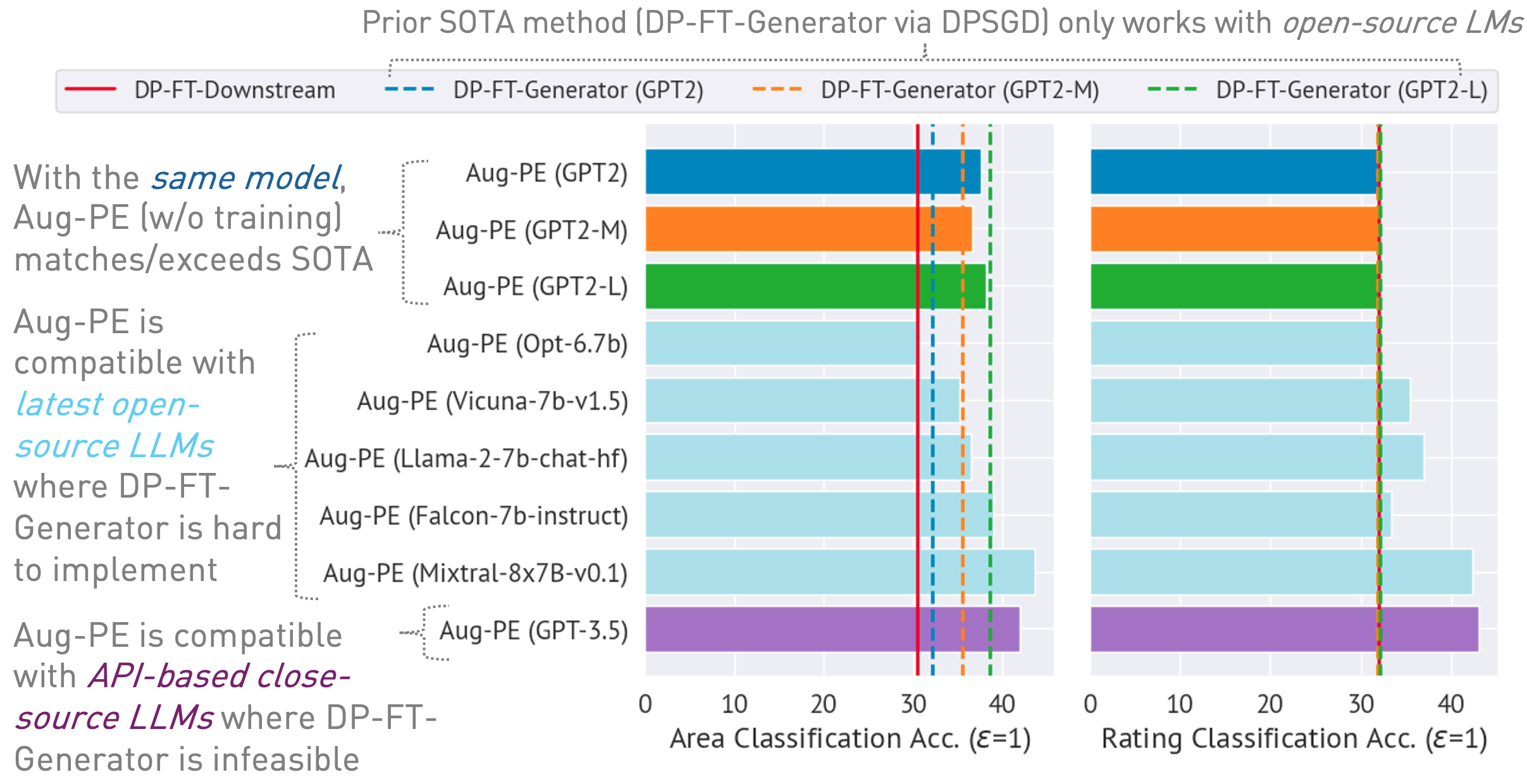
03/13/2024 : アルゴリズムとその結果の概要を説明するプロジェクト ページが利用可能になりました。03/11/2024 : コードと ArXiv 論文が利用可能になりました。 conda env create -f environment.yml
conda activate augpe
データセットはdata/{dataset}にあります。ここで、 datasetはyelp 、 openreview 、およびpubmedです。
このリンクから Yelp train.csv (1.21G) および PubMed train.csv (117MB) をダウンロードするか、次のコマンドを実行します。
bash scripts/download_data.sh # download yelp train.csv and pubmed train.csvデータセットの説明:
プライベート データの埋め込みを事前計算します (Aug-PE アルゴリズムの 1 行目):
bash scripts/embeddings.sh --openreview # Compute private embeddings
bash scripts/embeddings.sh --pubmed
bash scripts/embeddings.sh --yelp 注: OpenReview と PubMed の埋め込みの計算は比較的高速です。ただし、Yelp のデータセット サイズ (190 万のトレーニング サンプル) が大きいため、プロセスには約 40 分かかる場合があります。
プライバシー予算を考慮して、 notebook/dp_budget.ipynb内のデータセットの DP ノイズ レベルを計算します。
Wandb を使用して視覚化するには、 dpsda/arg_utils.pyでキーとプロジェクト名を使用して--wandb_keyと--projectを構成します。
Hugging Face のオープンソース LLM を利用して合成データを生成します。
export CUDA_VISIBLE_DEVICES=0
bash scripts/hf/{dataset}/generate.sh # Replace `{dataset}` with yelp, openreview, or pubmedいくつかの重要なハイパーパラメータ:
noise : DP ノイズ。epoch : DP 設定には 10 エポックを使用します。非 DP 設定の場合、Yelp には 20 エポックを使用し、他のデータセットには 10 エポックを使用します。model_type : ハグフェイスのモデル (["gpt2"、"gpt2-medium"、"gpt2-large"、"meta-llama/Llama-2-7b-chat-hf"、"tiiuae/falcon-7b-instruct" など) 、「facebook/opt-6.7b」、「lmsys/vicuna-7b-v1.5」、 「mistralai/Mixtral-8x7B-Instruct-v0.1」]。num_seed_samples : 合成サンプルの数。lookahead_degree : 合成サンプル埋め込み推定のバリエーションの数 (Aug-PE アルゴリズムの 5 行目)。デフォルトは 0 (自己埋め込み) です。L : 候補合成サンプルを生成するためのバリエーションの数に関連します (Aug-PE アルゴリズムの 18 行目)feat_ext : ハグフェイス文変換の埋め込みモデル。select_syn_mode : ヒストグラムの投票または確率に従って合成サンプルを選択します。デフォルトはrankです (Aug-PE アルゴリズムの 19 行目)temperature : LLM 生成用の温度。DP 合成テキストを使用してダウンストリーム モデルを微調整し、実際のテスト データでモデルの精度を評価します。
bash scripts/hf/{dataset}/downstream.sh # Finetune downstream model and evaluate performance 埋め込み分布距離を測定します。
bash scripts/hf/{dataset}/metric.sh # Calculate distribution distanceすべての生成ステップと評価ステップを組み合わせた合理化されたプロセスの場合:
bash scripts/hf/template/{dataset}.sh # Complete workflow for each dataset Azure OpenAI API 経由でクローズドソース モデルを使用します。 apis/azure_api.pyにキーとエンドポイントを設定してください。
MODEL_CONFIG = {
'gpt-3.5-turbo' :{ "openai_api_key" : "YOUR_AZURE_OPENAI_API_KEY" ,
"openai_api_base" : "YOUR_AZURE_OPENAI_ENDPOINT" ,
"engine" : 'YOUR_DEPLOYMENT_NAME' ,
},
}ここでのengine Azure のgpt-35-turboである可能性があります。
次のスクリプトを実行して合成データを生成し、それをダウンストリーム タスクで評価し、実際のデータと合成データの間の埋め込み分布距離を計算します。
bash scripts/gpt-3.5-turbo/{dataset}.shGPT-3.5 のテキスト長関連のプロンプトを使用して、生成されるテキストの長さを制御します。ここでは、いくつかの追加のハイパーパラメータを紹介します。
dynamic_len動的な長さのメカニズムを有効にするために使用されます。word_var_scale : target_word を決定するために使用されるガウス ノイズ分散。max_token_word_scale : 単語ごとのトークンの最大数。 target_word (プロンプトで指定) と max_token_word_scale に基づいて、LLM 生成の max_token を設定します。ノートブックを使用して、実際のデータと合成データの間のテキストの長さの分布の差を計算します: notebook/text_lens_distribution.ipynb
私たちの研究が役立つと思われる場合は、次のように引用することを検討してください。
@inproceedings {
xie2024differentially,
title = { Differentially Private Synthetic Data via Foundation Model {API}s 2: Text } ,
author = { Chulin Xie and Zinan Lin and Arturs Backurs and Sivakanth Gopi and Da Yu and Huseyin A Inan and Harsha Nori and Haotian Jiang and Huishuai Zhang and Yin Tat Lee and Bo Li and Sergey Yekhanin } ,
booktitle = { Forty-first International Conference on Machine Learning } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=LWD7upg1ob }
}コードまたは論文に関する質問がある場合は、Chulin ([email protected]) に電子メールを送信するか、問題を開いてください。


