ChatGPT、GenerativeAI、LLM のタイムライン
このリポジトリは、ChatGPT の発表の前後に発生した主要なイベント (製品、サービス、論文、GitHub、ブログ投稿、ニュース) のタイムラインを整理します。
このタイムラインでは、LLM と生成 AI に特に焦点を当てたさまざまな情報がまとめられています。
もしかしたら歴史上最も熱いシーンかもしれないので、その思い出をしっかりと残しておくことが大切だと思い、整理してみました。
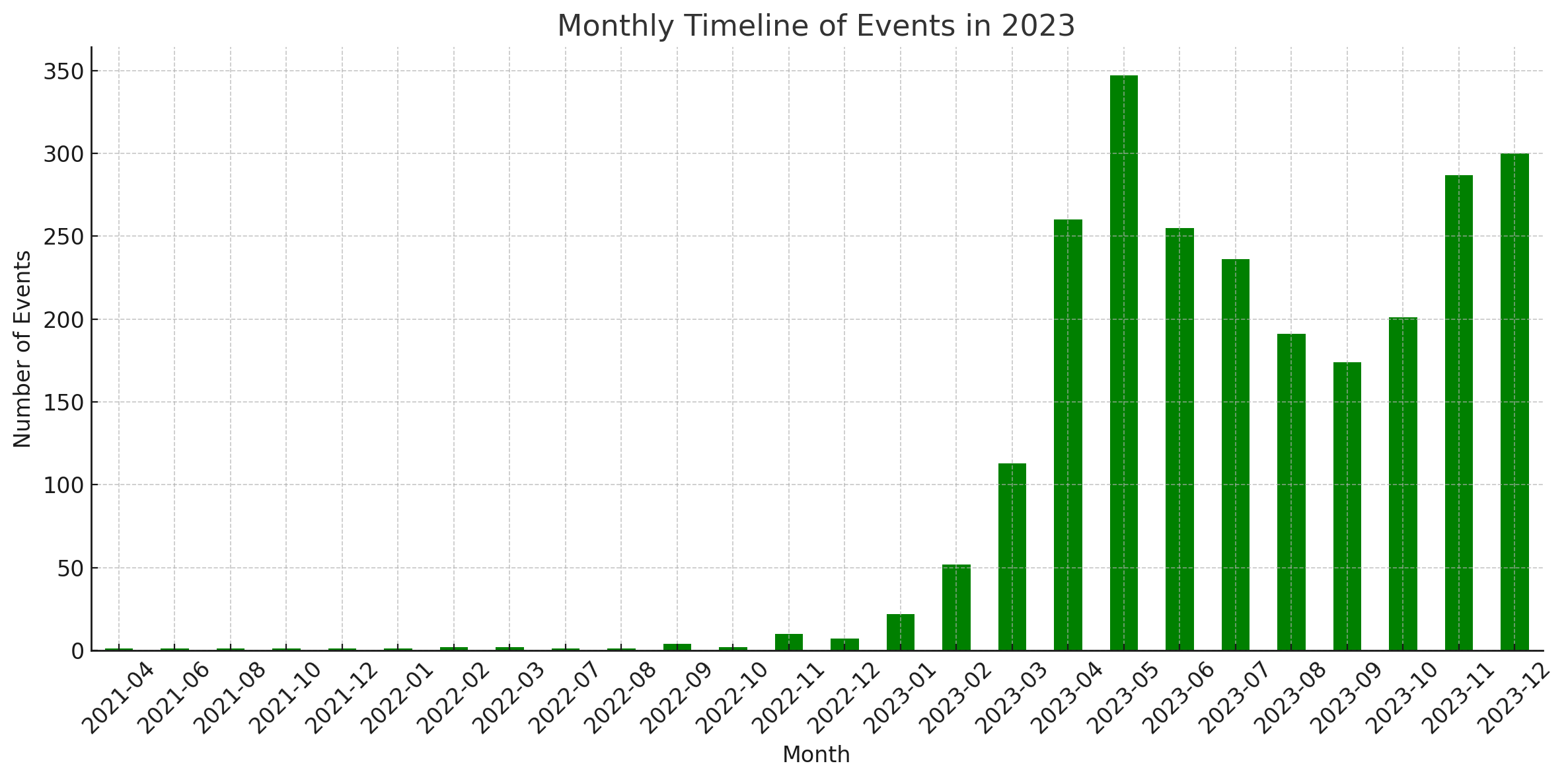
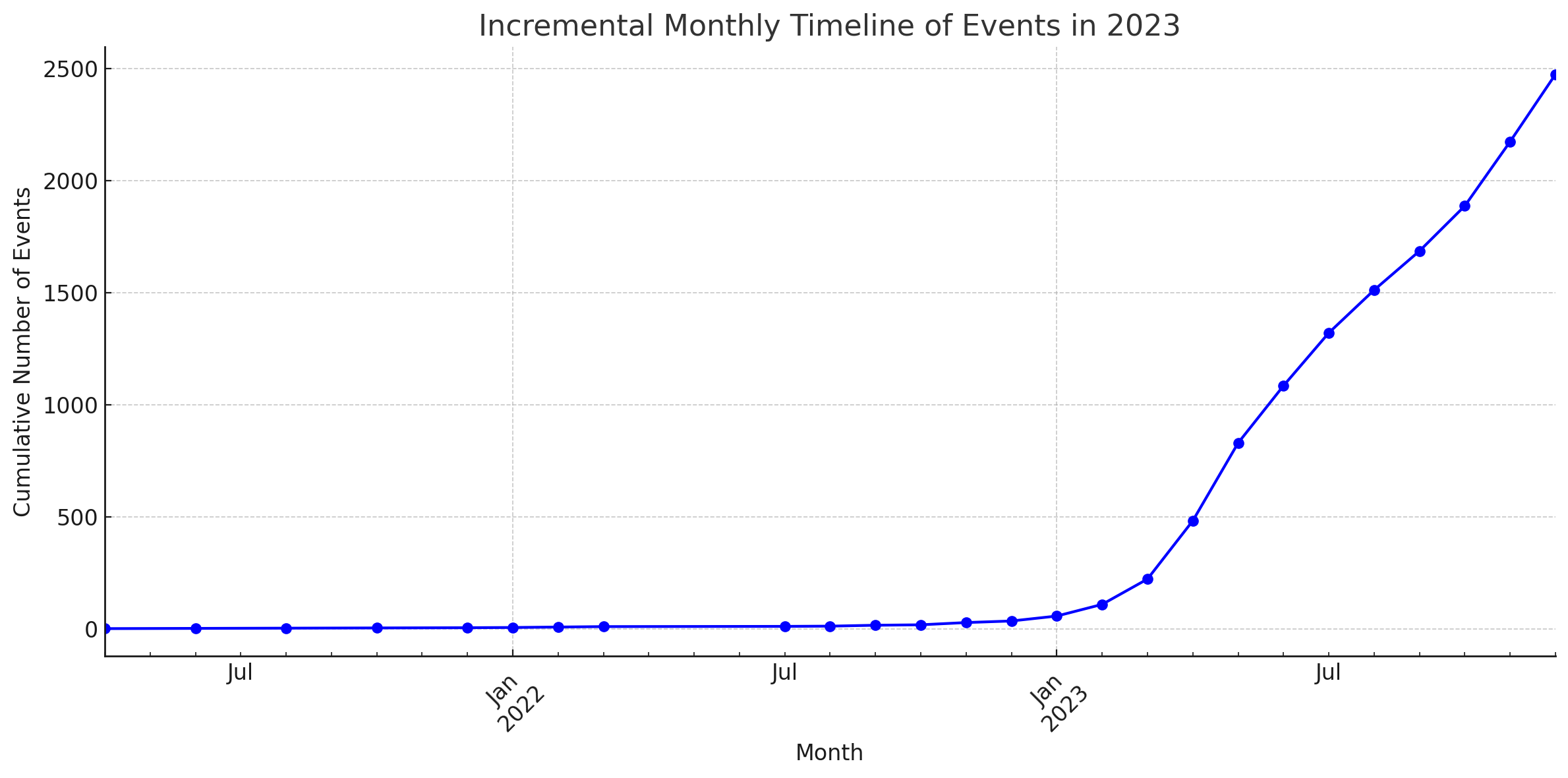
統計
これらの図は、ChatGPT のコード インタープリターによって生成されました。
貢献する
問題やプルリクエストは大歓迎です。これまでオープンソース プロジェクトに貢献したことがない場合は、プル リクエストの作成方法を喜んで説明します。
まず、解決したい問題を説明する問題を開いてください。そこから作業を進めます。
絵文字
arXiv 、 PDF ?、arxiv-vanity ?、論文ページ ?、コード付き論文 ✳️、Github
ライセンス
このドキュメントは MIT ライセンスに基づいてライセンスされています © Jonghong Jeon(전종홍)
タイムライン V2
2024年
- 05/17 - OpenAI があなたの投稿で AI をトレーニングする Reddit 契約を締結
(ニュース)、 - 05/17 - OpenAI、発表から 1 年も経たないうちに長期的な AI リスクに焦点を当てたチームを解散
(ニュース)、 - 05/17 -先進AIの安全性に関する国際科学報告書
(ブログ)、 - 05/16 - TRANSIC: オンライン修正から学習した Sim-to-Real ポリシーの転送
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 - Toon3D: 新しい視点から漫画を見る
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 -科学文献から生態学的情報を抽出するための AI ベースの大規模言語モデルの信頼性をテスト
(ニュース)、 - 05/16 -マルチモーダル基礎モデルでのメニーショット インコンテキスト学習
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 -手遅れになる前に AI を一時停止する方法
(ニュース)、 - 05/16 -グラウンディング DINO 1.5: オープンセット物体検出の「エッジ」を進歩させる
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 - GPT ストアのマイニングと分析
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 - Dual3D: デュアルモード マルチビュー潜在拡散による効率的かつ一貫性のあるテキストから 3D への生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 - Chameleon: 混合モードの初期融合基礎モデル
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/16 - CAT3D: マルチビュー拡散モデルを使用して 3D であらゆるものを作成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/15 - Xmodel-VLM: マルチモーダル ビジョン言語モデルのシンプルなベースライン
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/15 - LoRA は学びを減らし、忘れることを減らします
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/15 - Google の目に見えない AI ウォーターマークは、生成されたテキストとビデオの識別に役立ちます
(ニュース)、 - 05/15 - Google I/O 2024: すべてが発表されました
(ブログ)、 - 05/15 - BEHAVIOR Vision Suite: シミュレーションによるカスタマイズ可能なデータセット生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/15 - ALPINE: 言語モデルにおける自己回帰学習の計画機能を明らかに
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 -オンラインとオフラインの調整アルゴリズム間のパフォーマンスのギャップを理解する
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 - SpeechVerse: 大規模な一般化可能な音声言語モデル
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 - SpeechGuard: マルチモーダル大規模言語モデルの敵対的堅牢性の探求
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 -時間を無駄にすることはありません: モバイル ビデオを理解するためにチャンネルに時間を費やしましょう
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 - Hunyuan-DiT: きめ細かい中国語の理解を備えた強力なマルチ解像度拡散トランスフォーマー
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 -高密度ブロブ表現による構成的なテキストから画像への生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/14 -スケーリングの法則を超えて: 連想メモリによる変圧器の性能の理解
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/13 - SambaNova SN40L: データフローと専門家の構成による AI メモリの壁の拡張
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/13 - RLHF ワークフロー: 報酬モデリングからオンライン RLHF まで
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/13 - Plot2Code: 科学的プロットからのコード生成におけるマルチモーダル大規模言語モデルを評価するための包括的なベンチマーク
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/13 - OpenAI が最新の AI モデル GPT-4o を発表
(ニュース)、 - 05/13 - MS MARCO Web 検索: 数百万の実際のクリック ラベルを含む大規模な情報豊富な Web データセット
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/13 -大規模言語モデルによってどの程度の研究が書かれていますか?
(ブログ)、 - 05/13 -こんにちは GPT-4o
(ブログ)、 - 05/13 - Coin3D: プロキシガイドによるコンディショニングによる制御可能でインタラクティブな 3D アセット生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/11 - Piccolo2: マルチタスクのハイブリッド損失トレーニングによる一般的なテキストの埋め込み
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/11 - LogoMotion: コンテンツを意識したアニメーションのための視覚的に根拠のあるコード生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/10 - INSPECT - 大規模言語モデル評価用のオープンソース フレームワーク
(ブログ)、 - 05/10 - AI Safety Institute が新しい AI 安全性評価プラットフォームをリリース
(ニュース)、 - 05/07 - SUTRA: スケーラブルな多言語モデルのアーキテクチャ
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/07 -メタが Llama 3 オープンソース LLM をリリース
(ニュース)、 - 05/03 -視覚言語モデルを構築する際に何が重要ですか?
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 - WildChat: 野生の 100 万 ChatGPT インタラクション ログ
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 - StoryDiffusion: 長距離画像およびビデオ生成のための一貫した自己注意
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 - Prometheus 2: 他の言語モデルの評価に特化したオープンソース言語モデル
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 - NeMo-Aligner: 効率的なモデルの位置合わせのためのスケーラブルなツールキット
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 - LLM-AD: 大規模言語モデルベースの音声記述システム
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 - FLAME: 大規模言語モデルの事実を意識した調整
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/02 -単一の画像ペアを使用したテキストから画像へのモデルのカスタマイズ
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/01 -神経補償によるスペクトル プルーニングされたガウス フィールド
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/01 -言語モデルの調整のためのセルフプレイ設定の最適化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/01 -編集バッチ サイズは大きいほど常に優れていますか? -- Llama-3 によるモデル編集に関する実証研究
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/01 - Clover: 逐次知識を使用した回帰軽量投機的デコーディング
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 05/01 -小学校の算数における大規模言語モデルのパフォーマンスの慎重な検査
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - Visual Fact Checker: 高忠実度の詳細なキャプション生成を可能にする
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - STT: 自動運転用変圧器を使用したステートフル トラッキング
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - SemantiCodec: 一般サウンド用の超低ビットレートのセマンティック オーディオ コーデック
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - Octopus v4: 言語モデルのグラフ
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - MotionLCM: 潜在一貫性モデルによるリアルタイムの制御可能なモーション生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - MicroDreamer: スコアベースの反復再構成による sim20 秒でのゼロショット 3D 生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - Lightplane: ニューラル 3D フィールド用の拡張性の高いコンポーネント
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - KAN: コルモゴロフ-アーノルド ネットワーク
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 -反復推論の優先順位の最適化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - Invisible Stitch: 深度修復によるスムーズな 3D シーンの生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - InstantFamily: ゼロショット マルチ ID イメージ生成に対するマスクされた注意
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - GS-LRM: 3D ガウス スプラッティング用の大規模再構成モデル
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - Llama-3 のコンテキストを一晩で 10 倍に拡張
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 - DOCCI: 接続された対照的な画像の説明
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/30 -マルチトークン予測による大規模言語モデルの改善と高速化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/29 -スタイラス: 拡散モデルのアダプター自動選択
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/29 - SAGS: 構造を意識した 3D ガウス スプラッティング
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/29 -裁判官を陪審員に置き換える: 多様なモデルのパネルによる LLM 世代の評価
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/29 - NIST AI RMF 生成 AI プロファイル
(ニュース)、 - 04/29 - LoRA Land: GPT-4 に匹敵する 310 の微調整された LLM、技術レポート
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/29 -カンガルー: ダブル早期終了によるロスレス自己投機的デコード
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/29 -医学におけるジェミニモデルの機能
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/28 - Inpaint によるペイント: 最初に画像オブジェクトを削除して追加する方法を学ぶ
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/28 - LEGENT: 肉体を持つエージェントのためのオープン プラットフォーム
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/27 - Ag2Manip: エージェントに依存しないビジュアルおよびアクション表現による新しい操作スキルの学習
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/26 - MaPa: 3D シェイプ用のテキスト駆動のフォトリアリスティックなマテリアル ペイント
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/26 - BlenderAlchemy: 視覚言語モデルを使用した 3D グラフィックスの編集
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - Tele-FLM テクニカル レポート
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - SEED-Bench-2-Plus: テキストリッチな視覚的理解によるマルチモーダル大規模言語モデルのベンチマーク
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - Gecko を使用した Text-to-Image 評価の再考: メトリクス、プロンプト、人間による評価について
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - PLLaVA : ビデオ高密度キャプション用の画像からビデオへのパラメータフリーの LLaVA 拡張機能
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - LLM でコンテキストを最大限に活用する
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 -項目を 1 つずつリストする: マルチモーダル LLM の新しいデータ ソースと学習パラダイム
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 -レイヤ スキップ: 早期終了推論と自己投機的デコードの有効化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - Interactive3D: インタラクティブ 3D 生成で欲しいものを作成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - GPT-4V まであとどのくらいですか?オープンソース スイートで商用マルチモーダル モデルとのギャップを埋める
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/25 - ConsistentID: マルチモーダルできめ細かいアイデンティティを保持するポートレート生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - XC-Cache: 効率的な LLM 推論のためのキャッシュされたコンテキストへの相互参加
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 -高度な AI アシスタントの倫理
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - PuLID: コントラスト調整による Pure および Lightning ID のカスタマイズ
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - NeRF-XL: 複数の GPU を使用した NeRF のスケーリング
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - MotionMaster: ビデオ生成のためのトレーニング不要のカメラ モーション転送
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - MoDE: クラスタリングによる CLIP データ エキスパート
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - MMT ベンチ: マルチタスク AGI に向けた大規模な視覚言語モデルを評価するための包括的なマルチモーダル ベンチマーク
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - MaGGIe: マスクされたガイド付き段階的人間インスタンス マットング
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - ID アライナー: 報酬フィードバック学習によりアイデンティティを保持したテキストから画像への生成を強化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 -制御可能な合成のための編集可能な画像要素
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - CatLIP: Web スケールの画像テキスト データで 2.7 倍高速な事前トレーニングによる CLIP レベルの視覚認識精度
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/24 - BASS: バッチ処理された注意最適化投機的サンプリング
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/23 -トランスフォーマーは n-gram 言語モデルを表現できる
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/23 - Pegasus-v1 テクニカル レポート
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/23 -複数の専門家による混合
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/23 - FlashSpeech: 効率的なゼロショット音声合成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 - SnapKV: LLM は生成前に何を探しているかを知っています
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 - SEED-X: 統合された複数粒度の理解と生成を備えたマルチモーダル モデル
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 -シーン座標の再構築: リローカライザーの増分学習による画像コレクションのポージング
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 - Phi-3 テクニカル レポート: 携帯電話上でローカルに提供される高機能な言語モデル
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 - OpenELM: オープンソースのトレーニングおよび推論フレームワークを備えた効率的な言語モデル ファミリ
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 -マルチブース: テキストから画像内のすべてのコンセプトを生成することに向けて
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 - H-Infinity 移動制御の学習
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 -低ビット量子化 LLaMA3 モデルはどの程度優れていますか?実証的研究
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 -ステップを調整する: 拡散モデルでのサンプリング スケジュールの最適化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/22 -マルチモーダルな自動解釈エージェント
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/21 - Hyper-SD: 効率的な画像合成のための軌道セグメント化一貫性モデル
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/21 - AdvPrompter: LLM に対する高速適応型敵対的プロンプト
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/20 -音楽の一貫性モデル
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 -命令階層: 特権命令を優先するための LLM のトレーニング
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 - TextSquare: テキスト中心のビジュアル命令チューニングのスケールアップ
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 - PhysDreamer: ビデオ生成による 3D オブジェクトとの物理ベースのインタラクション
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 - LLM-R2: クエリ効率を向上させる大規模言語モデルの強化されたルールベースの書き換えシステム
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 -どれくらい本物ですか?無制限の敵対的な例に対する人間による評価フレームワーク
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 -実用的な機能レベルのプログラム修復でどこまでできるでしょうか?
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 - Groma: マルチモーダル大規模言語モデルを基盤とするローカライズされたビジュアル トークン化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 -ガウス スプラッティングには SFM の初期化が必要ですか?
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/19 - AutoCrawler: Web クローラー生成のための Web エージェントの進歩的な理解
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - TriForce: 階層的投機的デコーディングによる長いシーケンス生成のロスレス高速化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 -想像力、検索、批判を通じて LLM の自己改善に向けて
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 -報酬の再利用: ゼロショットの言語間の調整のための報酬モデルの転送
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - Reka Core、Flash、および Edge: 一連の強力なマルチモーダル言語モデル
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - OpenBezoar: 命令データの混合でトレーニングされた小規模でコスト効率の高いオープン モデル
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - MeshLRM: 高品質メッシュの大規模再構成モデル
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - MLCommons から AI セーフティ ベンチマーク v0.5 を導入
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - Meta Llama 3 の紹介: これまでで最も有能なオープンに利用可能な LLM
(ブログ)、 - 04/18 - EdgeFusion: オンデバイスのテキストから画像への生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - BLINK: マルチモーダル大規模言語モデルは見ることはできるが知覚できない
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/18 - AniClipart: テキストからビデオへの事前変換を使用したクリップアート アニメーション
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/17 - MoA: パーソナライズされた画像生成における主題と文脈のもつれを解くための混合注意
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/17 - FlowMind: LLM を使用した自動ワークフロー生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/17 -ダイナミックなタイポグラフィー: 言葉に命を吹き込む
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/17 -安定版 Diffusion 3 API が利用可能になりました
(ツイッター)、(ブログ)、(デモ)、 - 04/16 - VASA-1: リアルタイムで生成されるリアルなオーディオ主導の話し顔
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/16 -米国商務長官ジーナ・ライモンドが米国AI安全研究所リーダーシップチームの拡大を発表
(ニュース)、 - 04/16 -潜在的な拡散を伴う長編音楽の生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/15 - LLM 評価者は自分の世代を認識し、支持します
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/15 - Video2Game: 単一のビデオからのリアルタイム、インタラクティブ、リアルなブラウザ互換環境
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/15 - Tango 2: 直接優先最適化による拡散ベースのテキストからオーディオへの生成の調整
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/15 -神経放射フィールド修復のための潜在拡散モデルを飼いならす
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/15 - Opus はチューリング マシンとして動作可能
(ツイッター)、 - 04/15 - MathGPT: Llama 2 を活用して高度にパーソナライズされた学習のためのプラットフォームを作成
- 04/15 - HQ-Edit: 命令ベースの画像編集用の高品質データセット
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/15 - Ctrl-Adapter: 多様なコントロールをあらゆる拡散モデルに適応させるための効率的で多用途なフレームワーク
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/15 -圧縮はインテリジェンスを線形に表現します
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/15 - CompGS: 圧縮ガウス スプラッティングによる効率的な 3D シーン表現
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/14 - TextHawk: マルチモーダル大規模言語モデルの効率的かつきめ細かい認識の探索
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/13 -キャシー・ウッド、新しい OpenAI 株式で ChatGPT ブームに参加
(ニュース)、 - 04/12 -スケーリング (ダウン) クリップ: データ、アーキテクチャ、トレーニング戦略の包括的な分析
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/12 -ビジュアル基盤モデルの 3D 認識を調査する
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/12 -少ないトークンで小規模な基本 LM を事前トレーニングする
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/12 -低レベル視覚タスクに対する言語ガイダンスの堅牢性について: 奥行き推定からの発見
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/12 - MonoPatchNeRF: パッチベースの単眼ガイダンスによる神経放射フィールドの改善
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/12 - Megalodon: 無制限のコンテキスト長による効率的な LLM の事前トレーニングと推論
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/12 - ChatGPT は学者の執筆スタイルを変革しますか?
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/12 - COCONut: COCO セグメンテーションの最新化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/12 - AI チップがエネルギー予算を 99% 以上削減
(ニュース)、 - 04/12 - AdaptorSwap: データ削除とアクセス制御保証による LLM の継続的トレーニング
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/12 - Grok-1.5 ビジョン プレビュー
(デモ)、 - 04/12 -良いピン、悪いピン、そして人道的なピン
(ニュース)、 - 04/12 -有料 ChatGPT ユーザーが GPT-4 Turbo にアクセスできるようになりました
(ツイッター)、(ニュース)、、() - 04/11 - AI 監査基準委員会の必要性
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/11 -継続的な学習のために Transformer を思い出す
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - Amazon、人工知能の第一人者である Andrew Ng を取締役会に追加
(ニュース)、 - 04/11 -アドビ、AI モデルを構築するために 1 分あたり 3 ドルでビデオを購入
(ニュース)、 - 04/11 - UltraEval: LLM の柔軟かつ包括的な評価のための軽量プラットフォーム
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/11 -オープンボキャブラリーセグメンテーションの移転可能かつ原則的な効率性
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/11 - SWE エージェント
(ツイッター)、(デモ)、、() - 04/11 -まばらなレーンフォーマー
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - Rho-1: すべてのトークンが必要なわけではありません
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/11 - ResearchAgent: 大規模な言語モデルを使用した科学文献に対する反復的な研究アイデアの生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - RecurrentGemma: トランスフォーマーを超えて効率的なオープン言語モデルを実現
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - OSWorld: 実際のコンピューター環境におけるオープンエンド タスクのマルチモーダル エージェントのベンチマーク
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - LLoCO: オフラインで長いコンテキストを学習
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 -大規模言語モデル (LLM) を活用して、人間と AI のコラボレーションによるオンライン リスク データ アノテーションをサポート
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - JetMoE: 0.10 万ドルで Llama2 のパフォーマンスに到達
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) (プロジェクト)、(twitter)、、、(✳️)、 () - 04/11 - HGRN2: 状態拡張を備えたゲート線形 RNN
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/11 -単語から数字へ: コンテキスト内の例が与えられた場合、大規模な言語モデルは密かに有能なリグレッサーになります
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - Ferret-v2: 大規模な言語モデルの参照とグラウンディングのための改良されたベースライン
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - ControlNet++: 効率的な一貫性フィードバックによる条件付きコントロールの改善
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 -長期データセットにおけるコンテキスト認識型ビデオ異常検出
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - ChatGPT-3.5、クロード 3 が LLM のストリートファイター III トーナメントでピクセル化された尻を蹴る
(ニュース)、 - 04/11 - ChatGPT は、未来に設定された過去についてのストーリーを伝えるときに、未来を予測できます
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 -言語モデルの合成データに関するベスト プラクティスと教訓
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 -ストリートファイター 3 での戦いによる LLM のベンチマーク
(デモ)、、() - 04/11 - Audio Dialogues: オーディオと音楽を理解するためのダイアログ データセット
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 -限られた間隔でガイダンスを適用すると、拡散モデルのサンプルと配布の品質が向上します
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/11 - AmpleGCG: オープン LLM とクローズド LLM の両方をジェイルブレイクするための敵対的サフィックスの普遍的で転送可能な生成モデルの学習
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/10 - LM Transparency Tool: Transformer 言語モデルを分析するための対話型ツール
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - Gemini 1.5 Pro がオーディオを理解できるようになりました
(ツイッター)、 - 04/10 -概念の深さを探る: 大規模な言語モデルはどのようにしてさまざまな層で知識を取得するか?
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/10 -アーバン アーキテクト: 事前レイアウトを使用したステアリング可能な 3D アーバン シーンの生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - RealmDreamer: インペインティングと深度拡散によるテキスト駆動の 3D シーン生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - OpenAI と Meta は、人間と同じように推論できる AI モデルのリリースを目前に控えていると報告書が伝える
(ニュース)、 - 04/10 - MetaCheckGPT -- LLM 不確実性とメタモデルを使用したマルチタスク幻覚検出器
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - Meta は、Llama 3 オープンソース LLM が来月にリリースされることを確認しました
(ニュース)、 - 04/10 -コンテキストを残さない: Infini-attention を備えた効率的な無限コンテキスト トランスフォーマー
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 -インクリメンタル XAI: インクリメンタルな説明による AI の記憶に残る理解
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - DreamScene360: パノラマ ガウス スプラッティングによる制約のないテキストから 3D シーンの生成
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 -麻婆豆腐にはコーヒーが含まれていますか? LLM から食品関連の文化的知識を探る
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - BRAVE: 視覚言語モデルの視覚エンコーディングの拡張
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - AI スタートアップの Mistral が、OpenAI、Meta、Google に匹敵する 281GB AI モデルを発売
(ニュース)、 - 04/10 -リモート監視のためのエージェント駆動の生成的意味論的通信
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 - LLaMA デコーダーをビジョン トランスフォーマーに適応させる
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/10 -モバイル ネットワークにおける批判的思考のための生成 AI の統合に関する調査
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 -見てみましょう!言語モデルの脱獄を評価する方法を再考する
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 -ルーラー: ロングコンテキスト言語モデルの実際のコンテキスト サイズはどれくらいですか?
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 -ガウス スプラッティングにおける高密度化の改訂
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 -手持ちオブジェクトを 3D で再構築
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 - RAR-b: 検索ベンチマークとしての推論
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 -プライバシー保護の迅速なエンジニアリング: アンケート
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 - LLM によって生成されたソース コードの効率の評価について
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS) - 04/09 - OmniFusion テクニカル レポート
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 - MuPT: 生成的シンボリック音楽の事前訓練済みトランスフォーマー
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 - MiniCPM: スケーラブルなトレーニング戦略による小規模言語モデルの可能性を明らかにする
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 - Magic-Boost: マルチビュー条件付き拡散による 3D 生成の強化
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/09 - LLM2Vec: 大規模な言語モデルは密かに強力なテキスト エンコーダーです
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 - InternLM-XComposer2-4KHD: 336 ピクセルから 4K HD までの解像度を処理する先駆的な大型ビジョン言語モデル
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 - Hash3D: トレーニング不要の 3D 生成アクセラレーション
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 - Google が生成 AI のオープンソース プロジェクトを発表
(ニュース)、 - 04/09 -象は決して忘れない: 大規模言語モデルにおける表形式データの記憶と学習
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/09 - Apple は新しい Ferret-UI LLM を発表しました — この AI は iPhone 画面を読み取ることができます
(ニュース)、 - 04/09 - AEGIS: LLM 専門家のアンサンブルによるオンライン適応型 AI コンテンツの安全性モデレーション
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/08 - YaART: さらにもう 1 つの ART レンダリング テクノロジー
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/08 -ウィルバー: 堅牢で正確な Web エージェントのための適応型インコンテキスト学習
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/08 - UniFL: 統合フィードバック学習による安定した拡散の改善
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/08 -無制限のイカロス: マルチモーダル大規模言語モデルのセキュリティにおける画像入力の潜在的な危険性に関する調査
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/08 -幻覚リーダーボード -- 大規模な言語モデルで幻覚を測定するオープンな取り組み
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️) - 04/08 - LLM ベースのプログラム修復におけるファクト選択の問題
()、()、(?)、(?)、(?)、(HTML)、(SL)、(SP)、(GS)、(SS)、(✳️)、() - 04/08 -Swapanything:パーソナライズされた視覚編集で任意のオブジェクトのスワッピングを有効にする
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/08-サンバリンゴ:大規模な言語モデルの新しい言語を教える
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/08-否定的な選好最適化:壊滅的な崩壊から効果的な学習まで
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/08 -Naverは多言語Hyperclova X LLMをデビューしますそれはアジアのソブリンAIを構築するために使用します
(ニュース)、 - 04/08 -MOMA:高速パーソナライズされた画像生成用のマルチモーダルLLMアダプター
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/08- MedExpqa:医療質問のための大規模な言語モデルの多言語ベンチマーク
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/08- MA-lmm:長期的なビデオ理解のためのメモリ熟成大型マルチモーダルモデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/08 -Layoutllm:レイアウト命令ドキュメント理解のための大きな言語モデルを使用したレイアウト命令チューニング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/08-フェレットUI:マルチモーダルLLMSを使用した接地モバイルUIの理解
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/08-大規模な言語モデルの介入推論能力の評価
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/08-イーグルとフィンチ:マトリックス値状態と動的再発を備えたRWKV
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/08 -Codeclm:言語モデルを調整した合成データと調整
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/08-オートコーダーオーバー:自律プログラムの改善
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/07-ロード予測のTimeGpt:大規模な時系列モデルの視点
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/07- GPT -4をトレーニングするために100万時間以上のYouTubeビデオを転写しました
(ニュース)、 - 04/07-魔術師:変成シミュレータとしてのタイムラプスビデオ生成モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/07 -byteedit:生成画像の編集をブースト、コンプライパン、加速
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/06-医師の過半数の投票は、病理学におけるAIの信頼の適切性を向上させる
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss) - 04/06- Diffusion-RWKV:拡散モデル用のRWKVのようなアーキテクチャのスケーリング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/06- Datenerf:nerfsの深さを認識したテキストベースの編集
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/06-シーンを超えて:高解像度の人間中心のシーン生成は、拡散前に
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/06-人間のユーティリティを最適化することにより、拡散モデルを調整します
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/06-計画状のタスクのための基礎モデルをゼロから開発する場合
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/05-微調整と量子化によるLLMの脆弱性の増加
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/05 -SpatialTracker:3Dスペースで2Dピクセルを追跡する
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/05-大規模な言語モデルを使用したソーシャルスキルトレーニング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/05-シグマ:マルチモーダルセマンティックセグメンテーションのためのシャムマンバネットワーク
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/05-堅牢なガウスのスプラッティング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/05 -Physavatar:視覚的観察から服を着た3Dアバターの物理学を学ぶ
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/05- Koala:キーフレームコンディショニングロングVideo-llm
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/05-手がかり:LLMSの臨床言語理解評価
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/05-中国の小さなLLM:中心中心の大手言語モデルの前提
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/05-複雑な比較で人間を支援する:大規模な自動情報の比較
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04-両手で具体化されたAI:ゼロショット学習、安全性、モジュール性
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss) - 04/04-言語モデルの進化:反復学習の視点
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04-視覚化の視覚化は、大規模な言語モデルで空間的推論を引き出す
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)(twitter)、 - 04/04-指数データなしの「ゼロショット」なし:概念前の概念頻度がマルチモーダルモデルのパフォーマンスを決定する
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/04- LLM応答の検出エラーでLLMSを評価する
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/04-主観的な質問修正としての情報抽出における生成言語モデルの評価
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/04-直接ナッシュ最適化:一般的な好みで自己改善するための言語モデルを教える
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04- CBR-RAG:法的質問に応答するためのLLMSでの検索増強された生成のケースベースの推論
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04-コントロールエンジニアリングにおける大規模な言語モデルの機能:GPT -4、Claude 3 Opus、およびGemini 1.0 Ultraに関するベンチマーク研究
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04 -CanttalKaboutthis:対話のトピックを維持するための言語モデルを調整する
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04 -AutoWebglm:ブートストラップと強化
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/04-ニューハーラル圧縮テキストを介したLLMSのトレーニング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04 -reft:言語モデルの微調整を表現します
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/04- Red Teaming GPT-4V:GPT-4VはUNI/Multi-Modal脱獄攻撃に対して安全ですか?
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04- rall-e:テキストからスピーチへの合成を促したチェーンを使用した堅牢なコーデック言語モデリング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04 -PointInfinity:解像度に不変の点拡散モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04- Minigpt4-Video:インターリーブ視覚テキストトークンを使用したビデオ理解のためのマルチモーダルLLMSの進出
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04- comat:画像間の概念マッチングを備えたテキストから画像への拡散モデルを調整する
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04- CodeeDitorBench:大規模な言語モデルのコード編集機能の評価
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/04 -AutoWebglm:ブートストラップと強化
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/03-視覚的自己回帰モデリング:次のスケール予測によるスケーラブルな画像生成
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/03-拡散ベースのテキストから画像の生成のスケーラビリティについて
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/03-多くのショットの刑務所
() - 04/03- LVLM-Intrepret:大規模なビジョン言語モデルの解釈可能性ツール
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/03-コンパイラとしての言語モデル:擬似コード実行をシミュレートすると、言語モデルのアルゴリズムの推論が改善されます
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/03-インスタンススタイル:テキストからイメージの生成におけるスタイルプレゼンブに向けて無料のランチ
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/03-フレディトル:周波数分解による忠実で移転可能なnerf編集
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/03-クロスアテナンスは、テキスト間拡散モデルで推論を面倒にします
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/03- Chatglm-Math:自己批判的なパイプラインで大手言語モデルでの数学の問題解決の改善
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/02-英国と米国のAI安全科学に関するパートナーシップを発表
(ニュース)、 - 04/02-計画ドメインジェネレーターとしての大規模な言語モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss) - 04/02 -Poro 34bと多言語の祝福
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/02-オクトパスV2:スーパーエージェントのオンデバイス言語モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/02-詳細混合:トランスベースの言語モデルでのコンピューティングを動的に割り当てる
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/02-長いコンテキストLLMSは、長いコンテキスト内学習に苦労しています
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/02 -LLM -ABR:大規模な言語モデルを介した適応ビットレートアルゴリズムの設計
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/02-大規模な言語モデルは行動ヘルスケアの未来を変える可能性があります:責任ある開発と評価の提案
() - 04/02 -Hyperclova Xテクニカルレポート
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/02- Cameractrl:テキストからビデオへの生成のカメラ制御を有効にします
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/02-好みの木でジェネラリストを推論するLLMの前進
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/01-検索ストリーム(SOS):言語で検索することを学ぶ
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/01-首謀者としてのLLM:大規模な言語モデルを使用した戦略的推論の調査
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/01- AI大手言語モデルの台頭(LLMS)
(ブログ)、 - 04/01-ストリーミング密なビデオキャプション
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/01-拡散モデルの測定スタイルの類似性
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/01-正しく取得:テキスト間モデルの空間的一貫性の向上
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/01-データを汚すAI企業の場合、インターネットが小さすぎる
(ニュース)、 - 04/01- FlexidReamer:FlexCubesを使用した単一の画像から3Dの世代
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/01-評価:大規模な言語モデルの評価のための統一されたアクセス可能なライブラリ
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/01-言語モデルの報酬からのビデオの大規模なマルチモーダルモデルの直接選好最適化
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 04/01 -DBRX、継続的な事前トレーニング、報酬ベンチ、より速い推論など
(ブログ)、 - 04/01-コスミックマン:人間のテキストからイメージへの基礎モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/01-制御された画像生成のための状態認識ニューラルネットワーク
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/01-大きい方が常に良いとは限りません:潜在的拡散モデルのスケーリング特性
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 04/01-大手言語モデルは超人的な化学者ですか?
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/31- Wavllm:堅牢で適応的なスピーチの大規模な言語モデルに向けて
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/31-プラグインにうんざりしていませんか?大規模な言語モデルは、エンドツーエンドの推奨者です
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/30-大規模な言語モデル強化強化学習に関する調査:概念、分類法、方法
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/30 -st -llm:大規模な言語モデルは効果的な時間学習者です
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss) - 03/30-レイアウト対応言語モデルのノイズアウェアトレーニング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/30-マグリット:画像、トップビュー、テキストからの操作的で生成的な3D実現
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss) - 03/30- Aurora-M:米国の大統領令に従ってレッドチームの最初のオープンソース多言語モデルモデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/29-解決不可能な問題検出:ビジョン言語モデルの信頼性の評価
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/29-トランスライト:携帯電話GPUでの大規模な言語モデルの高効率展開
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/29- Snap-It、Tap-It、Splat-It:挑戦的な表面を再構築するための触覚に基づいた3Dガウスのスプラッティング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/ 29-レルム:言語モデリングとしての参照解像度
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/29 -NVIDIA H200 GPUSクラッシュMLPERFのLLM推論ベンチマーク
(ニュース)、 - 03/29-マンバミクサー:デュアルトークンとチャネル選択を備えた効率的な選択状態空間モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/29 -Llava -gemma:コンパクト言語モデルでマルチモーダルファンデーションモデルを加速
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/29- instantsplat:40秒で無制限のスパースビューのポーズフリーガウススプラッティング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/29- gecko:大規模な言語モデルから蒸留された汎用性のあるテキスト埋め込み
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/29-ディジャン:コンパクトなカーネル化による効率的な大型言語モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/29- DeepMindは、LLMを事実確認できるAIベースのアプリであるSafeを開発します
(ニュース)、 - 03/29 -CTRL -SIM:オフライン強化学習を備えた反応性と制御可能な駆動剤
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/29-私たちは大きなビジョン言語モデルを評価するための正しい方法ですか?
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/28 -SDPO:一度にデータをすべて使用しないでください
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/28 -mesh2nerf:神経放射輝度のフィールド表現と生成のための直接メッシュ監督
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/28-言語モデルにおける段落記憶のローカライズ
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/28-ジャンバ:ハイブリッドトランスマンバ言語モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/28 -GaussianCube :3D生成モデリングのための最適なトランスポートを使用したガウススプラッティングの構造化
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/28 -Claude 3は、AIボットの決闘でGPT -4を追い越します。アクションに参加する方法は次のとおりです
(ニュース)、 - 03/28- GROK -1.5の発表
(ブログ)、(デモ)、 - 03/27-法的自治への道:大規模な言語モデル、エキスパートシステム、ベイジアンネットワークを使用して法的情報を抽出、変換、読み込み、計算するための相互運用可能で説明可能なアプローチ
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/27- vitar:任意の解像度のあるビジョントランス
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/27-デバイス上の仮想アシスタントの世界英語モデルに向けて
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/27- TextCraftor:テキストエンコーダーは画質コントローラーにすることができます
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/27-オブジェクトドロップ:フォトリアリスティックオブジェクトの削除と挿入のための反事実をブートストラップする
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/ 27-ミニゲミニ:マルチモダリティビジョン言語モデルの可能性をマイニングする
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/27-大規模な言語モデルにおける長期の事実
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/27-リタ:言語指示された時間局在アシスタント
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/27 -Garment3DGen:3D衣服の様式化とテクスチャ生成
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/27-ガンバ:シングルビュー3D再構成のためにマンバと一緒にガウスのスプラッツを結婚する
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/27- FlexEdit:柔軟で制御可能な拡散ベースのオブジェクト中心の画像編集
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/27 -Biomedlm:生物医学テキストで訓練された2.7bパラメーター言語モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/26-マジス:GitHub問題解決のためのLLMベースのマルチエージェントフレームワーク
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/26-より深い層の不合理な非効率性
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/26- TC4D:軌道条件付けされたテキストから4Dの生成
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/26-オクトリー-GS:LOD構造化された3Dガウスとの一貫したリアルタイムレンダリングに向けて
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/26- DBRXの導入:新しい最先端のオープンLLM
(ブログ)、 - 03/26 -INTENLM2テクニカルレポート
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/26-自動迅速な最適化によるテキスト間の一貫性の改善
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/26- IntelデータセンターGPUの完全融合マルチ層パーセプトロン
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/26-エゴリフター:エゴセントリック知覚のためのオープンワールド3Dセグメンテーション
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/26 -Aniportrait:フォトリアリスティックなポートレートアニメーションのオーディオ駆動型合成
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/26-幾何学的に正確な輝きフィールドのための2Dガウスの飛び散
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/25- LLMSの臨床能力の自動評価に向けて:メトリック、データ、およびアルゴリズム
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/25-修理剤:プログラム修理のための自律的なLLMベースのエージェント
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/25- RL一貫性モデルのRL:より高速な報酬ガイド付きテキストからイメージの生成
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/25- Vp3D:テキストから3Dの世代のために2Dビジュアルプロンプトを解き放つ
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/25-トリップ:画像からビデオへの拡散モデルのための画像ノイズを使用した時間的残留学習
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/25- SDXS:画像条件を備えたリアルタイムのワンステップ潜在拡散モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/25 -LLMエージェントオペレーティングシステム
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/25-フラッシュフェイス:忠実度の高いアイデンティティの保存を伴う人間のイメージパーソナライズ
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/25-ドリームポリッシャー:幾何学的拡散による高品質のテキストから3Dの世代に向けて
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/25-自分自身になる:マルチサブジェクトのテキストからイメージの生成のための境界のある注意
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/23- LLMベースのコード生成がソフトウェア開発プロセスを満たしているとき
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/22 -Themestation:少数の模範からテーマ対応3Dアセットを生成する
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/22-シンバ:視力と多変量時系列のためのマンバベースの建築の簡略化されたアーキテクチャ
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/22 -LLM2LLM:新しい反復データ強化でLLMをブーストする
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/22- latte3d:大規模な償却テキストから強化3D合成
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/22 -internvideo2:マルチモーダルビデオ理解のためのビデオファンデーションモデルのスケーリング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/22-フォロー:情報を評価して指導して指示に従う
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/22-ドラガパート:明確なオブジェクトのために事前にパートレベルの動きを学ぶ
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/22-大規模な言語モデルはコンテキスト内を探索できますか?
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/22-オールハンド:大規模な言語モデルを介して大規模な逐語的フィードバックについて何か聞いてください
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss) - 03/21 -PEERGPT:チームモデレーターとしてのLLMベースのピアエージェントの役割を、子供の共同学習の参加者として調査する
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/21 -Stylecinegan:ランドスケープシネマグラフ生成事前に訓練されたスタイルガン
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/21 -StreamingT2V:テキストからの一貫性、動的、拡張可能な長いビデオ生成
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/21-ルノワーズ:反復的なノーシングによる実際の画像の反転
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/21-埋め立てのための手段:生成言語モデルとのチャット
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/21 -Rakutenai -7B:日本語の大規模な言語モデルを拡張します
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/21 -MYVLM:ユーザー固有のクエリ用のVLMSのパーソナライズ
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/21-数々:あなたのマルチモーダルLLMは、視覚数学の問題の図を本当に見ていますか?
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/21 -GRM:効率的な3D再構成と生成のための大きなガウス再構築モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/21-総会は人工知能に関する画期的な決議を採用しています
(ニュース)、 - 03/21-ガウスフロスティング:リアルタイムレンダリング付きの編集可能な複雑な輝きフィールド
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/21-時間と空間の探索的なインビット
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/21-コンテンツフレームモーションレイテント分解による効率的なビデオ拡散モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/21- DreamReward:Text-to-3D世代が人間の好みを備えています
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/21-コブラ:効率的な推論のためにマンバをマルチモーダルの大手言語モデルに拡張する
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/21-チャンピオン:3Dパラメトリックガイダンスを備えた制御可能で一貫した人間の画像アニメーション
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/21- ANYV2V:ビデオからビデオへの編集タスクのプラグアンドプレイフレームワーク
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/20-マッピングLLMセキュリティランドスケープ:包括的な利害関係者のリスク評価提案
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/20 -Zigma:Zigzag Mamba拡散モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/20 -VSTAR:より長い動的なビデオ統合のための生成時間看護
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/20-報酬ベンチ:言語モデリングの報酬モデルの評価
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/20-逆転の呪いを看護するための逆トレーニング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/20- radsplat:900+ fpsでの堅牢なリアルタイムレンダリングのための放射輝度フィールドインフォームのガウススプラッティング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/20-モーラ:マルチエージェントフレームワークを介してジェネラリストのビデオ生成を有効にする
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/20 -llamaFactory:100以上の言語モデルの統一効率的な微調整
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/20- Idadapter:テキスト間モデルのチューニングフリーパーソナライズのための混合機能の学習
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/20 -Hyperllava:マルチモーダルの大手言語モデルのダイナミックビジュアルおよび言語エキスパートチューニング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/20-危険な機能のフロンティアモデルの評価
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/20 -DEPTHFM:フローマッチング付きの高速単眼深度推定
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/20 -Compress3D:単一の画像からの3D世代の圧縮潜在スペース
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/20- be-your-outpainter:入力固有の適応を通じてアウトペインティングをマスターする
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/19-大きなビジョンモデルはいつ必要ではありませんか?
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/19- VID2ROBOT:分析トランスを使用したエンドツーエンドのビデオコンディショナルポリシー学習
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/19-計算病理学の汎用基礎モデルに向けて
() - 03/19-テックスドリーマー:ゼロショットに向けて、高忠実度の3Dヒューマンテクスチャ生成に向けて
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/19-シーンスクリプト:オートレーリング構造化言語モデルでシーンを再構築する
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/19- MPLUG-DOCOWL 1.5:OCRのない文書の理解のための統一された構造学習
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/19-マジックフィックスアップ:ダイナミックビデオを見ることによる写真編集の合理化
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/19- llmlingua-2:効率的で忠実なタスクに依存しないプロンプト圧縮のためのデータ蒸留
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/19- GVGEN:ボリューム表現を備えたテキストから3D世代
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/19 -GaussianFlow:4Dコンテンツの作成のためのガウスダイナミクスを飛ばす
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/19-フレスコ:ゼロショットビデオ翻訳のための空間的対応
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/ 19-フォースケール:トレーニングのない高解像度画像合成に関する頻度の視点
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/19-モデルのマージレシピの進化的最適化
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、([:octocat:](https ://github.com/ sakanaai/evolutionary-model-merge)! - 03/19-コンボバース:空間的に認識される拡散ガイダンスを使用した構成3Dアセットの作成
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/19-チャートベースの推論:LLMSからVLMSに機能を転送する
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/19- AppleのMM1:画像とテキストデータの両方を解釈できるマルチモーダルの大手言語モデル
(ニュース)、 - 03/19- Animatediff-Lightning:クロスモデル拡散蒸留
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/19-エージェントフラン:大規模な言語モデル向けの効果的なエージェントチューニングのデータと方法の設計
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/19-計算病理学の視覚言語基礎モデル
()、(✳✳) - 03/19-大規模な言語モデルを介した特性AIエージェント
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、()) - 03/18-私たちはLLMSの意思決定にどれくらい離れていますか?マルチエージェント環境でのLLMSのゲーム能力の評価
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/18-ビデオエージェント:ビデオ理解のためのメモリ編成マルチモーダルエージェント
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/18 -VFusion3d:ビデオ拡散モデルからのスケーラブルな3D生成モデルの学習
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/18 -TNT -LLM:大規模な言語モデルで大規模なテキストマイニング
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/18 -SV3D:潜在的なビデオ拡散を使用した単一の画像からの新しいマルチビュー合成と3D生成
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/18-ルーターベンチ:マルチLORMルーティングシステムのベンチマーク
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、(ss) - 03/18- LLMSでゼロショット視覚認識を自動化するためのメタプロンプル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/18 -LN3DIFF:スピーディな3D世代のためのスケーラブルな潜在的な神経界拡散
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/18- llava-uhd:あらゆるアスペクト比と高解像度の画像を知覚するLMM
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️)、() - 03/18-ラリマー:エピソードメモリコントロールを備えた大きな言語モデル
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/18- Infinite-ID:ID-semantics Decoupling Paradigmによるアイデンティティに保存されたパーソナライズ
()、()、(?)、(?)、(?)、(html)、(sl)、(sp)、(gs)、(ss)、(✳️) - 03/18 -GPT -4評価者として:農業における害虫管理に関する大規模な言語モデルの評価
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Compiler generated feedback for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - PhD: A Prompted Visual Hallucination Evaluation Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/16 - VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/16 - Do Large Language Models understand Medical Codes?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - VideoAgent: Long-form Video Understanding with Large Language Model as Agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Trusting the Search: Unraveling Human Trust in Health Information from Google and ChatGPT
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - PERL: Parameter Efficient Reinforcement Learning from Human Feedback
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - NeuFlow: Real-time, High-accuracy Optical Flow Estimation on Robots Using Edge Devices
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - MusicHiFi: Fast High-Fidelity Stereo Vocoding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - LightIt: Illumination Modeling and Control for Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Enhancing Human-Centered Dynamic Scene Understanding via Multiple LLMs Collaborated Reasoning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - DiPaCo: Distributed Path Composition
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - WavCraft: Audio Editing and Generation with Natural Language Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Editing via Factorized Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Scaling Instructable Agents Across Many Simulated Worlds
(twitter), (Blog), - 03/14 - Recurrent Drafter for Fast Speculative Decoding in Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - LocalMamba: Visual State Space Model with Windowed Selective Scan
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Helpful or Harmful? Exploring the Efficacy of Large Language Models for Online Grooming Prevention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - GPT on a Quantum Computer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/14 - Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - GiT: Towards Generalist Vision Transformer through Universal Language Interface
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Exploring the Capabilities and Limitations of Large Language Models in the Electric Energy Sector
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - 3D-VLA: A 3D Vision-Language-Action Generative World Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Scaling Instructable Agents Across Many Simulated Worlds
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/13 - VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - The Human Factor in Detecting Errors of Large Language Models: A Systematic Literature Review and Future Research Directions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - SOTOPIA-π: Interactive Learning of Socially Intelligent Language Agents
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Simple and Scalable Strategies to Continually Pre-train Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Scaling Up Dynamic Human-Scene Interaction Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language-based game theory in the age of artificial intelligence
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language models scale reliably with over-training and on downstream tasks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Knowledge Conflicts for LLMs: A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Gemma: Open Models Based on Gemini Research and Technology
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Cultural evolution in populations of Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Bugs in Large Language Models Generated Code: An Empirical Study
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Synth^2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - MoAI: Mixture of All Intelligence for Large Language and Vision Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Learning Generalizable Feature Fields for Mobile Manipulation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - DragAnything: Motion Control for Anything using Entity Representation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Chronos: Learning the Language of Time Series
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Transparent AI Disclosure Obligations: Who, What, When, Where, Why, How
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - HILL: A Hallucination Identifier for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - FAX: Scalable and Differentiable Federated Primitives in JAX
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FashionReGen: LLM-Empowered Fashion Report Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - VideoMamba: State Space Model for Efficient Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - V3D: Video Diffusion Models are Effective 3D Generators
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Stealing Part of a Production Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - Multistep Consistency Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FaceChain-SuDe: Building Derived Class to Inherit Category Attributes for One-shot Subject-Driven Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - Chain-of-table: Evolving tables in the reasoning chain for table understanding (Blog),
- 03/11 - An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/10 - VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/09 - Algorithmic progress in language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - On Protecting the Data Privacy of Large Language Models (LLMs): A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/08 - VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - DeepSeek-VL: Towards Real-World Vision-Language Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/08 - CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Now available on Poe: Claude 3 (Demo),
- 03/08 - Google - Health-specific embedding tools for dermatology and pathology (Blog),
- 03/07 - Yi: Open Foundation Models by 01.AI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Teaching Large Language Models to Reason with Reinforcement Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - StableDrag: Stable Dragging for Point-based Image Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Radiative Gaussian Splatting for Efficient X-ray Novel View Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Pix2Gif: Motion-Guided Diffusion for GIF Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Meet 'Liberated Qwen', an uncensored LLM that strictly adheres to system prompts (News),
- 03/07 - LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - KAIST develops next-generation ultra-low power LLM accelerator (News),
- 03/07 - Inflection-2.5: meet the world's best personal AI (News),
- 03/07 - How Far Are We from Intelligent Visual Deductive Reasoning?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Evaluating LLM models at scale (Blog),
- 03/07 - Common 7B Language Models Already Possess Strong Math Capabilities
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - SaulLM-7B: A pioneering Large Language Model for Law
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - NY hospital exec: Multimodal LLM assistants will create a “paradigm shift” in patient care (News),
- 03/06 - Learning to Decode Collaboratively with Multiple Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - Enhancing Vision-Language Pre-training with Rich Supervisions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Backtracing: Retrieving the Cause of the Query
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - AI Prompt Engineering Is Dead (News),
- 03/06 - 3D Diffusion Policy
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/05 - OpenAI and Elon Musk (Blog),
- 03/05 - Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/05 - WikiTableEdit: A Benchmark for Table Editing by Natural Language Instruction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Updating the Minimum Information about CLinical Artificial Intelligence (MI-CLAIM) checklist for generative modeling research (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Revisiting Meta-evaluation for Grammatical Error Correction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - MathScale: Scaling Instruction Tuning for Mathematical Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Interactive Continual Learning: Fast and Slow Thinking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - In Search of Truth: An Interrogation Approach to Hallucination Detection (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ImgTrojan: Jailbreaking Vision-Language Models with ONE Image (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Generative Software Engineering (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Exploring the Limitations of Large Language Models in Compositional Relation Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Design2Code: How Far Are We From Automating Front-End Engineering? (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Models are Task-specific Classifiers (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 3/5 - OpenAI - ChatGPT can now read responses to you. (twitter,
- 03/04 - The Claude 3 Model Family: Opus, Sonnet, Haiku
() (twitter), , (✳️) - 03/04 - Wukong: Towards a Scaling Law for Large-Scale Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - Large language models surpass human experts in predicting neuroscience results
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/04 - NoteLLM: A Retrievable Large Language Model for Note Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - MagicClay: Sculpting Meshes With Generative Neural Fields (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/04 - Enhancing LLM Safety via Constrained Direct Preference Optimization (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - CODE-ACCORD: A Corpus of Building Regulatory Data for Rule Generation towards Automatic Compliance Checking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - Balancing Enhancement, Harmlessness, and General Capabilities: Enhancing Conversational LLMs with Direct RLHF (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 3/4 - ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - TripoSR: Fast 3D Object Reconstruction from a Single Image (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - RT-H: Action Hierarchies Using Language (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - Build AI for a Better Future (twitter), (News),
- 3/4 - AtomoVideo: High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 03/03 - Research Papers in February 2024: A LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM Research (Blog),
- 3/3 - Nvidia CEO Jensen Huang says AI could pass most human tests in 5 years (News
- 3/3 - MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - Could this be bigger than OpenAI? Microsoft invests billions in French startup — Mistral AI is a multilingual maestro that's almost as good as ChatGPT 4 (News),
- 3/3 - 3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/2 - Nvidia CEO says AI could pass human tests in five years (News
- 3/1 - Elon Musk sues OpenAI and CEO Sam Altman over contract breach (News)
- 3.1 - AtP*: An efficient and scalable method for localizing LLM behaviour to components (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - VisionLLaMA: A Unified LLaMA Interface for Vision Tasks (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Learning and Leveraging World Models in Visual Representation Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Resonance RoPE: Improving Context Length Generalization of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/29 - OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/29 - Retrieval-Augmented Generation for AI-Generated Content: A Survey (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 2.29 - DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Humanoid Locomotion as Next Token Prediction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - StarCoder 2 and The Stack v2: The Next Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Trajectory Consistency Distillation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - Beyond Language Models: Byte Models are Digital World Simulators (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Syntactic Ghost: An Imperceptible General-purpose Backdoor Attacks on Pre-trained Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - ViewFusion: Towards Multi-View Consistency via Interpolated Denoising (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - MOSAIC: A Modular System for Assistive and Interactive Cooking (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 02/28 - Automatic Creative Selection with Cross-Modal Matching
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 2.28 - Priority Sampling of Large Language Models for Compilers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Simple linear attention language models balance the recall-throughput tradeoff (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.28 - Approaching Human-Level Forecasting with Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Datasets for Large Language Models: A Comprehensive Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.28 - A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - A High Level Guide to LLM Evaluation Metrics (Blog),
- 2/27 - Users Say Microsoft's AI Has Alternate Personality as Godlike AGI That Demands to Be Worshipped (News)
- 2/27 - Google DeepMind CEO on AGI, OpenAI and Beyond – MWC 2024 (News)
- 2.27 - Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Towards Optimal Learning of Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Evaluating Very Long-Term Conversational Memory of LLM Agents (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Training-Free Long-Context Scaling of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - DiffuseKronA: A Parameter Efficient Fine-tuning Method for Personalized Diffusion Model (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora Generates Videos with Stunning Geometrical Consistency (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Video as the New Language for Real-World Decision Making (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - On the Societal Impact of Open Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/26 - Set the Clock: Temporal Alignment of Pretrained Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2/26 - DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models (), ()(?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/26 - Mistral Large is our flagship model, with top-tier reasoning capacities (News)
- 2.26 - Disentangled 3D Scene Generation with Layout Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Multi-LoRA Composition for Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.26 - Do Large Language Models Latently Perform Multi-Hop Reasoning? (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Nemotron-4 15B Technical Report (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - StructLM: Towards Building Generalist Models for Structured Knowledge Grounding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Towards Open-ended Visual Quality Comparison (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.25 - ChatMusician: Understanding and Generating Music Intrinsically with LLM (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.25 - FuseChat: Knowledge Fusion of Chat Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/24 - Divide-or-Conquer? Which Part Should You Distill Your LLM?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/24 - Perplexity.ai Revamps Google SEO Model For LLM Era (News)
- 02/24 - Data Interpreter: An LLM Agent For Data Science
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2.24 - Empowering Large Language Model Agents through Action Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Seamless Human Motion Composition with Blended Positional Encodings (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - Genie: Generative Interactive Environments (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - GPTVQ: The Blessing of Dimensionality for LLM Quantization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.22 - CLoVe: Encoding Compositional Language in Contrastive Vision-Language Models (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️), ()
- 02/22 - Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 2.22 - Divide-or-Conquer? Which Part Should You Distill Your LLM? (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - Watermarking Makes Language Models Radioactive (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - AutoPrompt - prompt optimization framework ()
- 2.22 - Announcing Stable Diffusion 3 (tweet), (blog)
- 2.22 - DualFocus: Integrating Macro and Micro Perspectives in Multi-modal Large Language Models (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - RoboScript: Code Generation for Free-Form Manipulation Tasks across Real and Simulation (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - LLMs with Industrial Lens: Deciphering the Challenges and Prospects -- A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Vision-Language Navigation with Embodied Intelligence: A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Enhancing Robotic Manipulation with AI Feedback from Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - PALO: A Polyglot Large Multimodal Model for 5B People (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion (), (), ([:paperclip:](https://arxiv.org/pdf/2402.148


