meena chatbot
1.0.0
ここでは、Google Research によって開発され、論文「人間らしいオープンドメイン チャットボットに向けて」で説明されている最先端のチャットボットである Meena を再作成するという私の試みを示します。
この実装では、論文で説明されている進化したトランスフォーマー モデルを使用して、tensor2tensor 深層学習ライブラリを使用しました。
使用されるトレーニング セットは、イタリア語の OpenSubtitles コーパスです。他の多くの言語もここで利用できます。
論文で行われた研究と同様に、このモデルは 1 つのエンコーダー ブロックと 12 のデコーダー ブロック、合計 108M のパラメーターで構成されています。使用されるオプティマイザーは、論文で説明されているものと同じトレーニング レート スケジュールを持つ Adafactor です。
イタリア語の OpenSubtitles データセットの 4,000 万文でモデルをトレーニングした後の結果は次のとおりです。学習率は 0.01 から始まり、10k ステップの間は一定のままで、その後ステップ数の逆平方根に応じて減衰します。
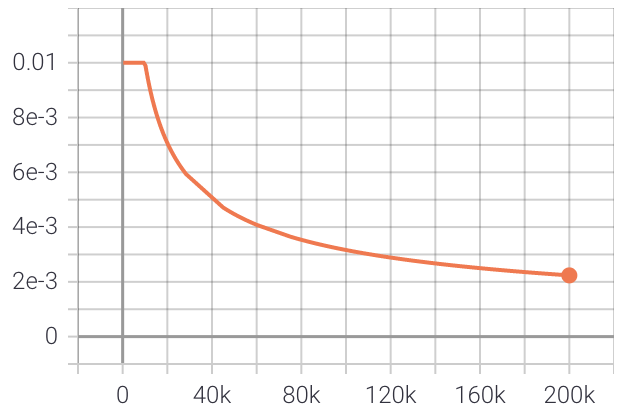
以下は、トレーニング中の評価損失のプロットです。 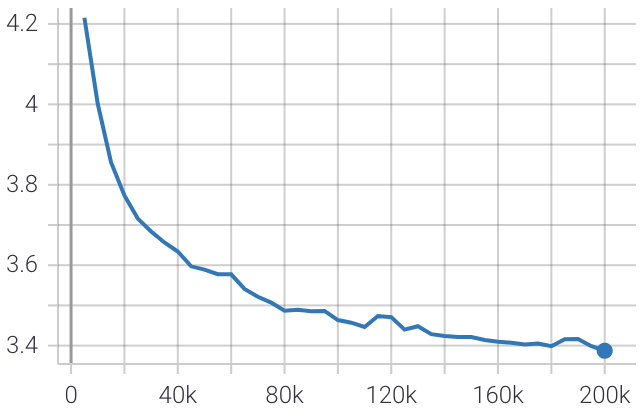
最終的な困惑度スコアは 10.4 で、これは Google のmeena chatbot 10.2 によって達成される困惑度スコアに非常に近いです。
この論文では、混乱スコアと、チャットボットの「人間らしさ」と相関する感度および特異性の平均との相関関係を示しています。私たちの困惑スコアは、私たちのボットが Cleverbot や DialoGPT などの他のチャットボットよりも優れていることを示しています。 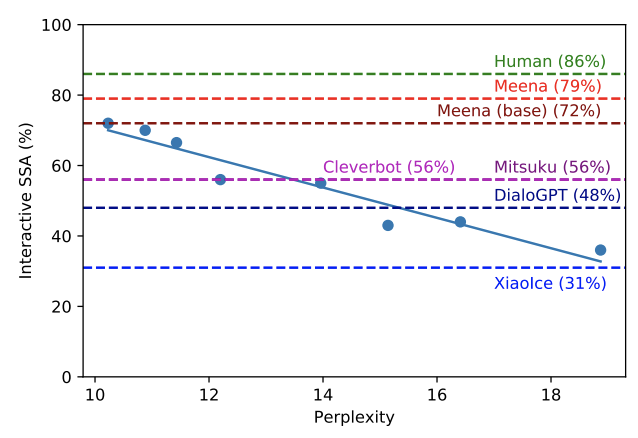
ただし、使用されたデータセットは人間間の通常の会話をあまり表していません。ただし、Opensubtitles は、多くの言語で非常に大規模なデータセットを提供します。
ノートブックmeena_chatbot_inference.ipynbを実行するだけです。
それ以外の場合は、次のモデルをダウンロードして解凍します。適切なMODEL_DIRとCHECKPOINT_NAMEをpredict.pyに設定し、 main.pyを実行します。
トレーニングするには、Google Colab で ipython ノートブックを実行するだけです。モデルは Google ドライブに保存されます。実行の最後に、チャットボットと対話できるようになります。
モデルは、フォルダー内の次のファイルをコピーすることでエクスポートできます。
適切なモデル ディレクトリを設定した後、 main.py実行します。
server.pyチャットボットを提供するための単純な HTTP API を提供します。


