prometeo
1.0.0

これは、組み込みハイパフォーマンス コンピューティングのための実験的なモデリング ツールである prometeo です。 prometeo は、Python 言語のサブセットに基づくドメイン固有言語 (DSL) を提供します。これにより、高性能の自己完結型 C コードに簡単にトランスパイルできる高級言語 (Python 自体) で科学計算プログラムを簡単に作成できます。組み込みデバイスに展開可能。
prometeo のドキュメントは、https://prometeo.readthedocs.io/en/latest/index.html の Read the Docs でご覧いただけます。
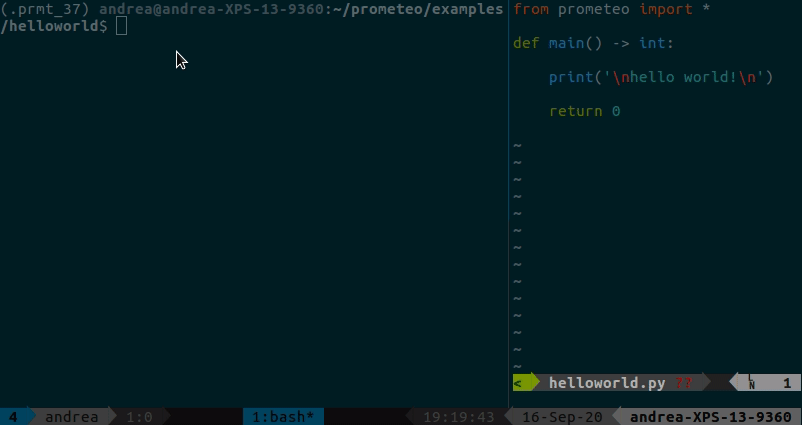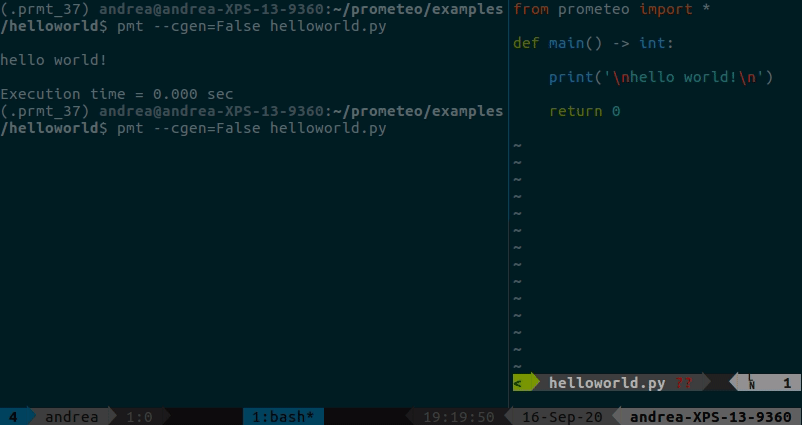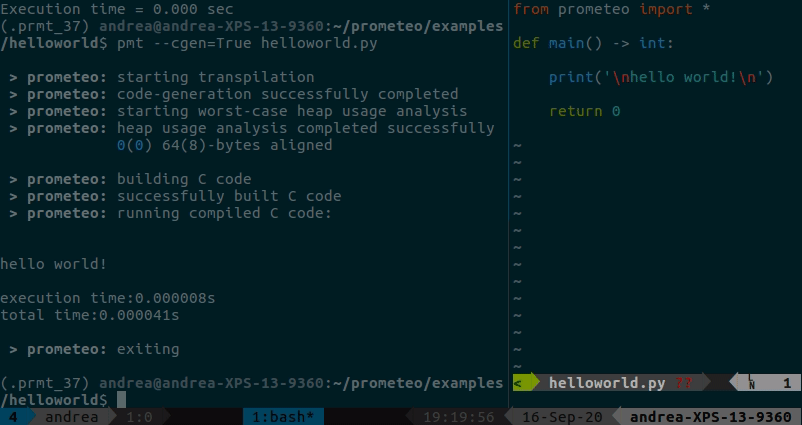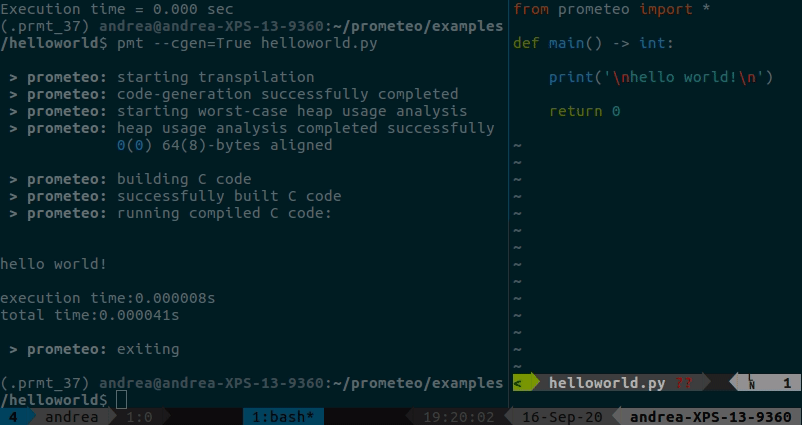
Python から簡単な prometeo プログラムを実行する方法、またはそれを C にトランスパイルしてビルドして実行する方法を示す簡単な hello world の例は、ここにあります。出力には、ヒープ使用量分析の結果と実行時間が表示されます (この場合、表示される内容はあまりありません:p)。
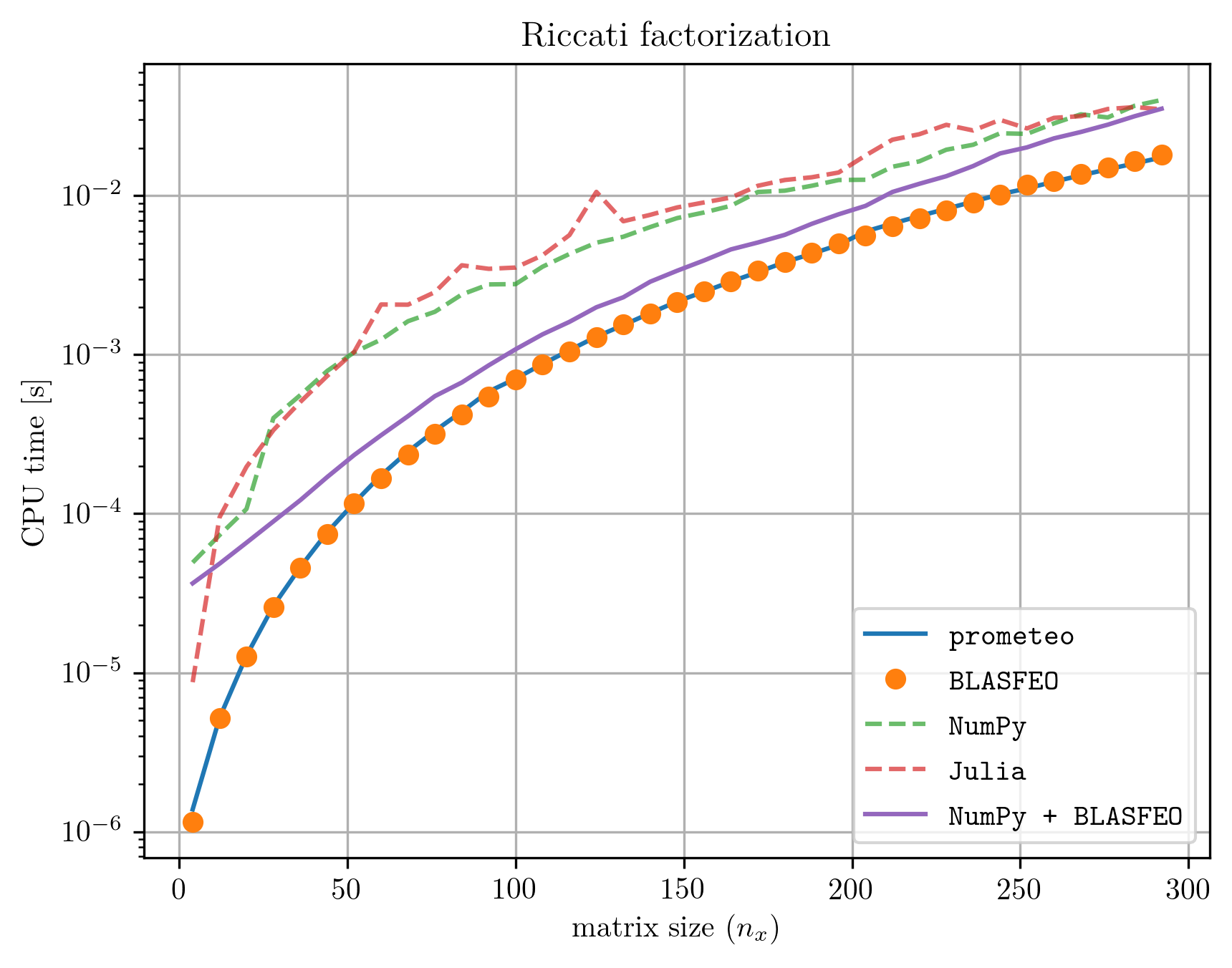
prometeo プログラムは、高性能線形代数ライブラリ BLASFEO (出版物: https://arxiv.org/abs/1704.02457、コード: https://github.com/giaf/blasfeo) を呼び出す純粋な C コードにトランスパイルされるため、実行時間は手書きの高性能コードに匹敵します。以下の図は、BLASFEO を呼び出して高度に最適化された手書きの C コードを使用して Riccati 分解を実行するのに必要な CPU 時間と、この例の prometeo トランスパイルされたコードで取得された CPU 時間の比較を示しています。 NumPy と Julia で得られた計算時間も比較のために追加されています。ただし、Riccati 因数分解のこれらの最後の 2 つの実装は、prometeo によって生成された C コードやハンドコーディングされた C 実装ほど簡単に埋め込み可能ではないことに注意してください。すべてのベンチマークは、2.30 GHz で動作する i7-7560U CPU を搭載した Dell XPS-9360 で実行されました (サーマル スロットルによる周波数変動を避けるため)。
さらに、prometeo は、Nuitka などの最先端の Python コンパイラーを大幅に上回るパフォーマンスを発揮します。以下の表は、フィボナッチ ベンチマークで取得された CPU 時間を示しています。
| パーサー/コンパイラー | CPU時間[秒] |
|---|---|
| Python 3.7 (CPython) | 11.787 |
| ヌイツカ | 10.039 |
| ピピ | 1.78 |
| プロメテオ | 0.657 |
prometeo はpip install prometeo-dslを使用して PyPI 経由でインストールできます。 prometeo は Python コードに静的型付け情報を提供するために型ヒントを広範囲に使用するため、必要な Python の最小バージョンは 3.6 であることに注意してください。
ローカルマシン上にソースを構築して prometeo をインストールする場合は、次のように進めることができます。
git submodule update --init実行してサブモジュールのクローンを作成します。<prometeo_root>/prometeo/cpmtからmake install_shared実行して、C バックエンドに関連付けられた共有ライブラリをコンパイルしてインストールします。デフォルトのインストール パスは<prometeo_root>/prometeo/cpmt/installであることに注意してください。virtualenv --python=<path_to_python3.6> <path_to_new_virtualenv>を使用して仮想環境をセットアップできます。pip install -e . <prometeo_root>から Python パッケージをインストールします。最後に、 pmt <example_name>.py --cgen=<True/False>を使用して<root>/examplesの例を実行できます。 --cgenフラグは、コードが Python インタープリタによって実行されるか、C コードによって実行されるかを決定します。生成され、コンパイルされて実行されます。
Python コード ( examples/simple_example/simple_example.py )
from prometeo import *
n : dims = 10
def main () -> int :
A : pmat = pmat ( n , n )
for i in range ( 10 ):
for j in range ( 10 ):
A [ i , j ] = 1.0
B : pmat = pmat ( n , n )
for i in range ( 10 ):
B [ 0 , i ] = 2.0
C : pmat = pmat ( n , n )
C = A * B
pmat_print ( C )
return 0標準の Python インタプリタ (バージョン 3.6 以上が必要) で実行でき、コマンドpmt simple_example.py --cgen=False使用して、説明された線形代数演算を実行します。同時に、コードは prometeo によって解析され、その抽象構文ツリー (AST) が分析されて、次の高性能 C コードが生成されます。
#include "stdlib.h"
#include "simple_example.h"
void * ___c_pmt_8_heap ;
void * ___c_pmt_64_heap ;
void * ___c_pmt_8_heap_head ;
void * ___c_pmt_64_heap_head ;
#include "prometeo.h"
int main () {
___c_pmt_8_heap = malloc ( 10000 );
___c_pmt_8_heap_head = ___c_pmt_8_heap ;
char * pmem_ptr = ( char * ) ___c_pmt_8_heap ;
align_char_to ( 8 , & pmem_ptr );
___c_pmt_8_heap = pmem_ptr ;
___c_pmt_64_heap = malloc ( 1000000 );
___c_pmt_64_heap_head = ___c_pmt_64_heap ;
pmem_ptr = ( char * ) ___c_pmt_64_heap ;
align_char_to ( 64 , & pmem_ptr );
___c_pmt_64_heap = pmem_ptr ;
void * callee_pmt_8_heap = ___c_pmt_8_heap ;
void * callee_pmt_64_heap = ___c_pmt_64_heap ;
struct pmat * A = c_pmt_create_pmat ( n , n );
for ( int i = 0 ; i < 10 ; i ++ ) {
for ( int j = 0 ; j < 10 ; j ++ ) {
c_pmt_pmat_set_el ( A , i , j , 1.0 );
}
}
struct pmat * B = c_pmt_create_pmat ( n , n );
for ( int i = 0 ; i < 10 ; i ++ ) {
c_pmt_pmat_set_el ( B , 0 , i , 2.0 );
}
struct pmat * C = c_pmt_create_pmat ( n , n );
c_pmt_pmat_fill ( C , 0.0 );
c_pmt_gemm_nn ( A , B , C , C );
c_pmt_pmat_print ( C );
___c_pmt_8_heap = callee_pmt_8_heap ;
___c_pmt_64_heap = callee_pmt_64_heap ;
free ( ___c_pmt_8_heap_head );
free ( ___c_pmt_64_heap_head );
return 0 ;
}これは、高性能線形代数パッケージ BLASFEO に依存しています。生成されたコードはpmt simple_example.py --cgen=Trueの実行時にすぐにコンパイルされ、実行されます。
ある言語で書かれたプログラムを、同等の抽象化レベルを持つ別の言語に翻訳することは、非常に異なる抽象化レベルを持つ言語に翻訳するよりもはるかに簡単ですが (特にターゲット言語のレベルがはるかに低い場合)、Python プログラムを C プログラムに翻訳する場合は、まだかなりの抽象化ギャップが存在しますが、一般的には簡単な作業ではありません。大まかに言えば、課題は、ソース言語でネイティブにサポートされている機能をターゲット言語で再実装する必要があることにあります。特に、Python を C に翻訳する場合、この 2 つの言語の抽象化レベルの違いと、ソース言語とターゲット言語が 2 つの非常に異なるタイプであるという事実の両方から困難が生じます。つまり、Python はインタプリタ型、ダックタイプ、ガベージです。 -収集された言語であり、C はコンパイルされ静的に型付けされた言語です。
生成された C コードが (小規模から中規模の計算であっても) 効率的で、組み込みハードウェアに展開可能でなければならないという制約を追加すると、Python を C にトランスパイルするタスクはさらに困難になります。実際、これら 2 つの要件は、生成されたコードが次のものを利用できないことを直接暗示しています。 i)高度なランタイム ライブラリ (Python ランタイム ライブラリなど)。これは一般に組み込みハードウェアでは利用できません。 ii)実行が遅く信頼性が低くなる動的メモリ割り当て。 (例外は、セットアップフェーズで割り当てられ、サイズが事前にわかっているメモリに対して行われます)。
ソースからソースへのコード変換、つまりトランスパイル、特に Python コードから C コードへのトランスパイルは未踏の領域ではないため、以下では、これに対処する既存のプロジェクトをいくつか取り上げます。そうすることで、上で概説した 2 つの要件、つまり (小規模) 効率と組み込み性のうちの 1 つをどこでどのように満たしていないのかを強調します。
さまざまな形式で Python から C への変換に対応するソフトウェア パッケージがいくつか存在します。
ハイパフォーマンス コンピューティングのコンテキストでは、 Numba はPython で記述された数値関数のジャストインタイム コンパイラーです。そのため、その目的は、プログラム全体ではなく、適切にアノテーションが付けられた Python 関数を、実行を高速化できるように高性能 LLVM コードに変換することです。 Numba は、変換されるコードの内部表現を使用し、Python または C/C++ から呼び出すことができる LLVM コードを生成するために、関係する変数に対して (場合によっては部分的な) 型推論を実行します。場合によっては、つまり完全な型推論が正常に実行できる場合、C API に依存しないコードを ( nopythonフラグを使用して) 生成できます。ただし、発行された LLVM コードは、依然として BLAS および LAPACK 操作のためにNumpyに依存します。
Nuitkaは、あらゆる Python 構造をlibpythonライブラリにリンクする C コードに変換できるソースツーソース コンパイラーであり、そのため大規模なクラスの Python プログラムをトランスパイルできます。これを行うには、Python 言語の最もよく使用される実装の 1 つであるCPythonが C で記述されているという事実に依存します。実際、 Nuitka は、通常は によって実行されるCPythonへの呼び出しを含む C コードを生成します。 Python パーサー。魅力的で一般的なトランスパイル手法にもかかわらず、 libpythonへの本質的な依存関係により、組み込みハードウェアに簡単にデプロイすることはできません。同時に、Python 構造をCPython実装にかなり厳密にマッピングするため、小規模から中規模のハイパフォーマンス コンピューティングに関しては、多くのパフォーマンスの問題が発生することが予想されます。これは特に、実行速度を低下させる可能性がある型チェック、メモリ割り当て、ガベージ コレクションなどに関連する操作が、トランスパイルされたプログラムによっても実行されるという事実によるものです。
Cython は、 Python 言語の C 拡張機能の作成を容易にすることを目的としたプログラミング言語です。特に、(オプションで) 静的に型付けされた Python のようなコードをCPythonに依存する C コードに変換できます。 Nuitkaについての考慮事項と同様に、これはlibpythonに依存できる場合 (およびそのオーバーヘッドが無視できる場合、つまり十分に大規模な計算を扱う場合) には強力なツールになりますが、ここで関心のあるコンテキストではそうではありません。
最後に、ソース言語として Python を使用していませんが、 Juliaもジャストインタイム (および部分的に事前に) コンパイルされて LLVM コードになっていることに言及する必要があります。ただし、発行された LLVM コードはJuliaランタイム ライブラリに依存しているため、 CythonおよびNuitkaに対して行われたのと同様の考慮事項が適用されます。
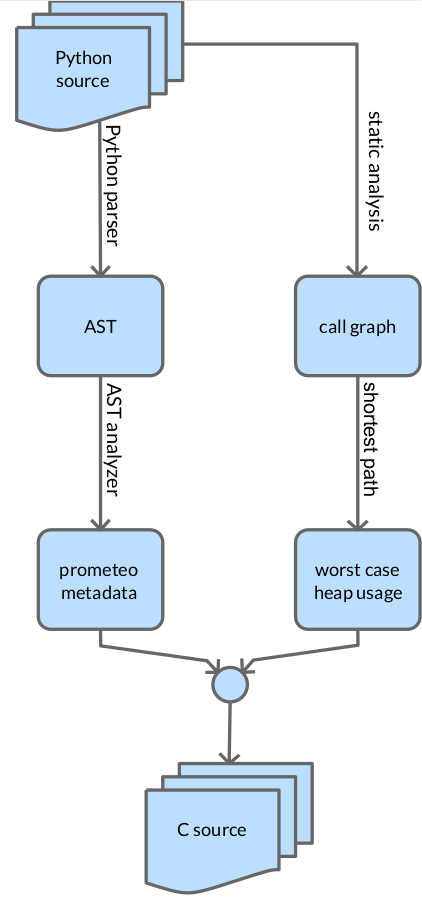
Python 言語の制限されたサブセットを使用して書かれたプログラムの C プログラムへのトランスパイルは、 prometeoのトランスパイラーを使用して実行されます。このソース間変換ツールは、高性能で埋め込み可能な C コードを出力するために、トランスパイルされるソース ファイルに関連付けられた抽象構文ツリー (AST) を分析します。これを行うには、Python コードに特別なルールを適用する必要があります。これにより、解釈された高レベルのダック型言語をコンパイルされた低レベルの静的型付けされた言語にトランスパイルするという非常に困難なタスクが可能になります。その際、結果として得られる言語がホスト言語 (Python 自体) の構文を使用し、 prometeoの場合、標準の Python インタプリタによっても実行できるという意味で、埋め込みDSL と呼ばれることがあるものを定義します。 。
from prometeo import *
nx : dims = 2
nu : dims = 2
nxu : dims = nx + nu
N : dims = 5
def main () -> int :
# number of repetitions for timing
nrep : int = 10000
A : pmat = pmat ( nx , nx )
A [ 0 , 0 ] = 0.8
A [ 0 , 1 ] = 0.1
A [ 1 , 0 ] = 0.3
A [ 1 , 1 ] = 0.8
B : pmat = pmat ( nx , nu )
B [ 0 , 0 ] = 1.0
B [ 1 , 1 ] = 1.0
Q : pmat = pmat ( nx , nx )
Q [ 0 , 0 ] = 1.0
Q [ 1 , 1 ] = 1.0
R : pmat = pmat ( nu , nu )
R [ 0 , 0 ] = 1.0
R [ 1 , 1 ] = 1.0
A : pmat = pmat ( nx , nx )
B : pmat = pmat ( nx , nu )
Q : pmat = pmat ( nx , nx )
R : pmat = pmat ( nu , nu )
RSQ : pmat = pmat ( nxu , nxu )
Lxx : pmat = pmat ( nx , nx )
M : pmat = pmat ( nxu , nxu )
w_nxu_nx : pmat = pmat ( nxu , nx )
BAt : pmat = pmat ( nxu , nx )
BA : pmat = pmat ( nx , nxu )
pmat_hcat ( B , A , BA )
pmat_tran ( BA , BAt )
RSQ [ 0 : nu , 0 : nu ] = R
RSQ [ nu : nu + nx , nu : nu + nx ] = Q
# array-type Riccati factorization
for i in range ( nrep ):
pmt_potrf ( Q , Lxx )
M [ nu : nu + nx , nu : nu + nx ] = Lxx
for i in range ( 1 , N ):
pmt_trmm_rlnn ( Lxx , BAt , w_nxu_nx )
pmt_syrk_ln ( w_nxu_nx , w_nxu_nx , RSQ , M )
pmt_potrf ( M , M )
Lxx [ 0 : nx , 0 : nx ] = M [ nu : nu + nx , nu : nu + nx ]
return 0同様に、上記のコード ( example/riccati/riccati_array.py ) は、コマンドpmt riccati_array.py --cgen=Falseを使用して標準の Python インタプリタで実行でき、prometeo は代わりにpmt riccati_array.py --cgen=Trueを使用して C コードを生成、コンパイル、実行できます。 pmt riccati_array.py --cgen=True 。
C にトランスパイルできるようにするために、Python 言語のサブセットのみがサポートされています。ただし、関数オーバーロードやクラスなどの C に似ていない機能は、prometeo のトランスパイラーによってサポートされています。以下の適応された Riccati の例 ( examples/riccati/riccati_mass_spring_2.py ) は、クラスの作成方法と使用方法を示しています。
from prometeo import *
nm : dims = 4
nx : dims = 2 * nm
sizes : dimv = [[ 8 , 8 ], [ 8 , 8 ], [ 8 , 8 ], [ 8 , 8 ], [ 8 , 8 ]]
nu : dims = nm
nxu : dims = nx + nu
N : dims = 5
class qp_data :
A : List = plist ( pmat , sizes )
B : List = plist ( pmat , sizes )
Q : List = plist ( pmat , sizes )
R : List = plist ( pmat , sizes )
P : List = plist ( pmat , sizes )
fact : List = plist ( pmat , sizes )
def factorize ( self ) -> None :
M : pmat = pmat ( nxu , nxu )
Mxx : pmat = pmat ( nx , nx )
L : pmat = pmat ( nxu , nxu )
Q : pmat = pmat ( nx , nx )
R : pmat = pmat ( nu , nu )
BA : pmat = pmat ( nx , nxu )
BAtP : pmat = pmat ( nxu , nx )
pmat_copy ( self . Q [ N - 1 ], self . P [ N - 1 ])
pmat_hcat ( self . B [ N - 1 ], self . A [ N - 1 ], BA )
pmat_copy ( self . Q [ N - 1 ], Q )
pmat_copy ( self . R [ N - 1 ], R )
for i in range ( 1 , N ):
pmat_fill ( BAtP , 0.0 )
pmt_gemm_tn ( BA , self . P [ N - i ], BAtP , BAtP )
pmat_fill ( M , 0.0 )
M [ 0 : nu , 0 : nu ] = R
M [ nu : nu + nx , nu : nu + nx ] = Q
pmt_gemm_nn ( BAtP , BA , M , M )
pmat_fill ( L , 0.0 )
pmt_potrf ( M , L )
Mxx [ 0 : nx , 0 : nx ] = L [ nu : nu + nx , nu : nu + nx ]
# pmat_fill(self.P[N-i-1], 0.0)
pmt_gemm_nt ( Mxx , Mxx , self . P [ N - i - 1 ], self . P [ N - i - 1 ])
# pmat_print(self.P[N-i-1])
return
def main () -> int :
A : pmat = pmat ( nx , nx )
Ac11 : pmat = pmat ( nm , nm )
Ac12 : pmat = pmat ( nm , nm )
for i in range ( nm ):
Ac12 [ i , i ] = 1.0
Ac21 : pmat = pmat ( nm , nm )
for i in range ( nm ):
Ac21 [ i , i ] = - 2.0
for i in range ( nm - 1 ):
Ac21 [ i + 1 , i ] = 1.0
Ac21 [ i , i + 1 ] = 1.0
Ac22 : pmat = pmat ( nm , nm )
for i in range ( nm ):
for j in range ( nm ):
A [ i , j ] = Ac11 [ i , j ]
for i in range ( nm ):
for j in range ( nm ):
A [ i , nm + j ] = Ac12 [ i , j ]
for i in range ( nm ):
for j in range ( nm ):
A [ nm + i , j ] = Ac21 [ i , j ]
for i in range ( nm ):
for j in range ( nm ):
A [ nm + i , nm + j ] = Ac22 [ i , j ]
tmp : float = 0.0
for i in range ( nx ):
tmp = A [ i , i ]
tmp = tmp + 1.0
A [ i , i ] = tmp
B : pmat = pmat ( nx , nu )
for i in range ( nu ):
B [ nm + i , i ] = 1.0
Q : pmat = pmat ( nx , nx )
for i in range ( nx ):
Q [ i , i ] = 1.0
R : pmat = pmat ( nu , nu )
for i in range ( nu ):
R [ i , i ] = 1.0
qp : qp_data = qp_data ()
for i in range ( N ):
qp . A [ i ] = A
for i in range ( N ):
qp . B [ i ] = B
for i in range ( N ):
qp . Q [ i ] = Q
for i in range ( N ):
qp . R [ i ] = R
qp . factorize ()
return 0免責事項: prometeo はまだ非常に準備段階にあり、現時点ではいくつかの線形代数演算と Python 構造のみがサポートされています。


