Dropout NeuralNetworks
1.0.0
この研究プロジェクトでは、中退率の変化が MNIST データセットに及ぼす影響に焦点を当てます。私の目標は、研究論文で使用されたデータを使用して以下の図を再現することです。このプロジェクトの目的は、機械学習図がどのように作成されたかを学ぶことです。具体的には、脱落確率を変更した場合と変更しない場合の分類誤差への影響を学習します。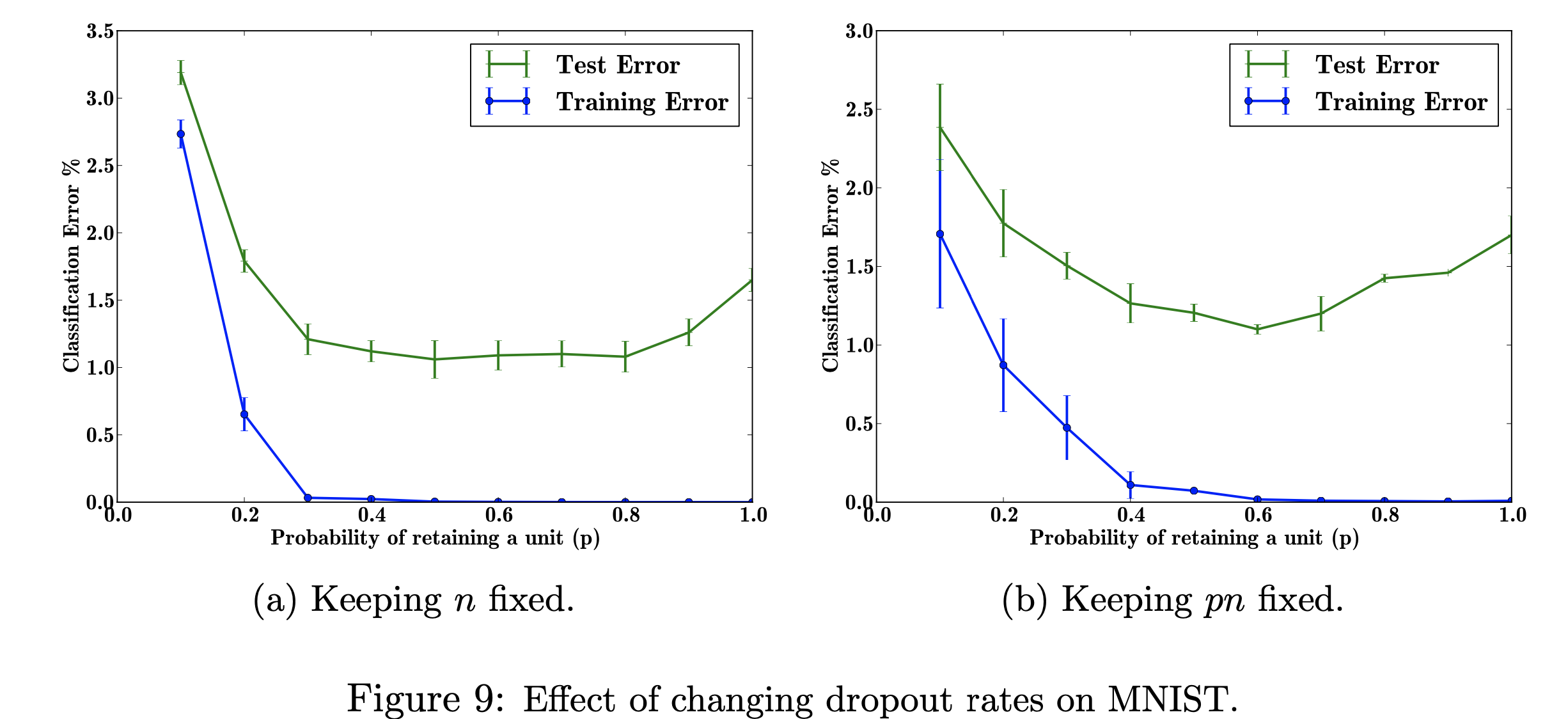 図の参照元: Srivastava, N.、Hinton, G.、Krizhevsky, A.、Krizhevsky, I.、Salakhutdinov, R.、Dropout: A Simple Way to Prevent Neural Networks from Overfitting、図 9
図の参照元: Srivastava, N.、Hinton, G.、Krizhevsky, A.、Krizhevsky, I.、Salakhutdinov, R.、Dropout: A Simple Way to Prevent Neural Networks from Overfitting、図 9
TensorFlow を使用して MNIST データセットでドロップアウトを実行し、Matplotlib を使用して論文内の図の再作成を支援しました。また、組み込みの Decimal ライブラリを使用して、0.0 から 1.0 までの p のさまざまな値を計算しました。ライブラリ「csv」は、すでに計算された p の値の計算時間を節約するために、以前に実行したデータを CSV ファイルに追加するためにインポートされました。 Numpy は、プロットの x 軸と y 軸のステップ サイズが同じになるようにインポートされました。最後に、GPU ではなく CPU の使用によるエラーを取り除くために、「os」をインポートしました。
エラー率に影響を与える、調整可能なハイパーパラメーター「p」(ネットワーク内にユニットを保持する確率) と隠れ層の数「n」の値を変えることの影響を調査します。 p と n の積が固定されると、隠れ層の数を一定に保つ場合 (図 9b) に比べて、p の値が小さい場合の誤差の大きさが減少することがわかります (図 9a)。
トレーニング データが限られている場合、サンプリング ノイズの結果、入力/出力間の多くの複雑な関係が生じます。それらはトレーニング セットには存在しますが、同じ分布から抽出されたものであっても実際のテスト データには存在しません。この複雑さは過学習につながります。これは過学習の発生を防ぐアルゴリズムの 1 つです。この図の入力は手書きの数字のデータセットであり、ドロップアウトを追加した後の出力は、ドロップアウト手法を適用した結果を表すさまざまな値です。全体として、ドロップアウトを追加した後の結果はエラーが少なくなります。
これが当てはまる現実の問題は、Google 検索です。誰かが映画のタイトルを検索しているかもしれませんが、彼らは視覚的に学習するため、画像だけを探している可能性があります。したがって、テキスト部分や簡単な説明を省略すると、画像の特徴に焦点を当てることができます。この記事には、データの取得元 (http://yann.lecun.com/exdb/mnist/) が記載されています。各画像は 28x28 桁で表現されます。 y ラベルは画像データ列のようです。
この図を再現する私の目標は、データをテスト/トレーニングし、p の各確率 (ネットワーク内にユニットが保持される確率) の分類誤差を計算することです。私の目標は、実装が有効であることを示すためにエラーが減少するにつれて p を増加させることであり、同じ結果が得られるようにこのハイパー パラメーターを調整します。これを行うには、784-2048-2048-2048-10 アーキテクチャを使用してすべてのトレーニング データとテスト データをループし、n を固定したままにしてから、pn を変更して固定します。次に、データを収集して csv ファイルに書き込みます。この csv ファイルには、図を出力するために必要なすべてのデータが含まれます。このプロジェクトでは、ドロップアウト率がニューラル ネットワークの全体的な誤差にどのように役立つかを学びます。
クリックして表示


