LaTeX OCR
1.0.0
このプロジェクトの目標は、数式の画像を取得し、対応する LaTeX コードを返す学習ベースのシステムを作成することです。
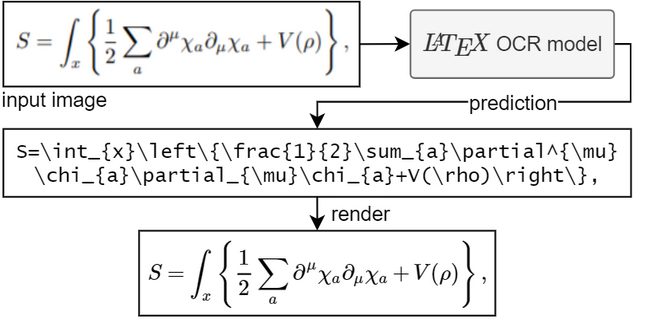
モデルを実行するには Python 3.7 以降が必要です
PyTorch がインストールされていない場合。ここの指示に従ってください。
pix2texパッケージをインストールします。
pip install "pix2tex[gui]"
モデル チェックポイントは自動的にダウンロードされます。
画像から予測を取得するには 3 つの方法があります。
pix2tex呼び出すことでコマンド ライン ツールを使用できます。ここでは、ディスクにある既存の画像やクリップボード内の画像を解析できます。
@katie-lim のおかげで、モデルの予測を簡単に取得する方法として優れたユーザー インターフェイスを使用できます。 latexocrを使用して GUI を呼び出すだけです。ここからスクリーンショットを撮ることができ、予測された Latex コードが MathJax を使用してレンダリングされ、クリップボードにコピーされます。
Linux では、 gnome-screenshot事前にインストールされていれば、 gnome-screenshot (マルチモニターのサポートが付属) で GUI を使用できます。 Wayland の場合、 grimとslurp両方とも使用可能な場合に使用されます。 gnome-screenshot wlroots ベースの Wayland コンポジターと互換性がないことに注意してください。 gnome-screenshot使用可能な場合は優先されるため、この場合は環境変数SCREENSHOT_TOOL grimに設定する必要がある場合があります (他の使用可能な値はgnome-screenshotとpilです)。
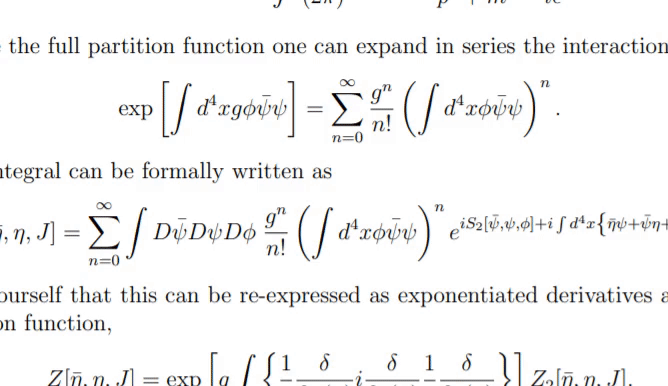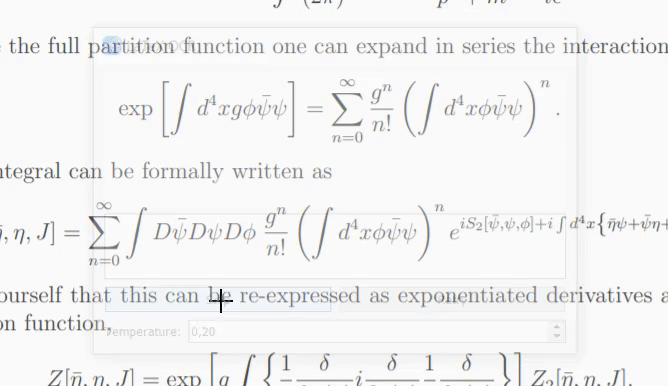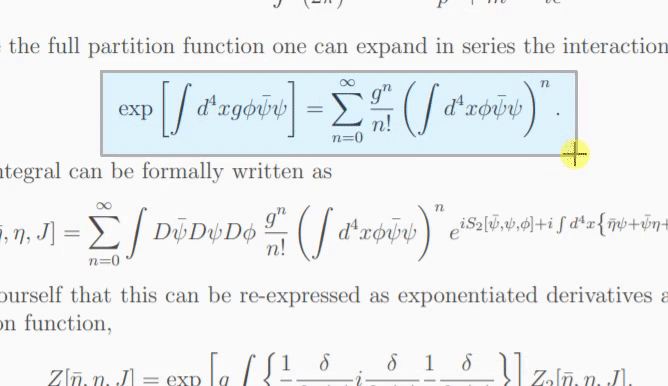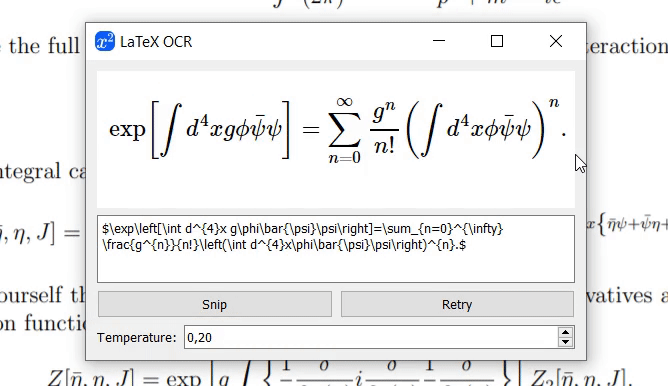
モデルが画像の内容を確信していない場合、[再試行] をクリックするたびに異なる予測が出力される可能性があります。 temperatureパラメータを使用すると、この動作を制御できます (低温でも同じ結果が得られます)。
APIを利用することができます。これには追加の依存関係があります。 pip install -U "pix2tex[api]"経由でインストールし、実行します
python -m pix2tex.api.run
ポート 8502 で API に接続する Streamlit デモを開始します。API で使用できる Docker イメージもあります: https://hub.docker.com/r/lukasblecher/pix2tex
docker pull lukasblecher/pix2tex:api docker run --rm -p 8502:8502 lukasblecher/pix2tex:api
streamlit デモ実行も実行するには
docker run --rm -it -p 8501:8501 --entrypoint python lukasblecher/pix2tex:api pix2tex/api/run.py
http://localhost:8501/ に移動します。
Python 内から使用する
from PIL import Imagefrom pix2tex.cli import LatexOCRimg = Image.open('path/to/image.png')model = LatexOCR()print(model(img))このモデルは、解像度が低い画像で最適に機能します。そのため、別のニューラル ネットワークが入力画像の最適な解像度を予測する前処理ステップを追加しました。このモデルは、トレーニング データに最もよく似るようにカスタム イメージのサイズを自動的に変更するため、実際に存在するイメージのパフォーマンスが向上します。それでも完璧ではなく、巨大な画像を最適に処理できない可能性があるため、写真を撮る前に最大限にズームインしないでください。
常に結果を慎重に再確認してください。答えが間違っていた場合は、別の解像度で予測をやり直すことができます。
パッケージを使用したいですか?
現在ドキュメントを作成中です。
ここにアクセスしてください: https://pix2tex.readthedocs.io/
いくつかの依存関係をインストールしますpip install "pix2tex[train]" 。
まず、画像をグラウンド トゥルース ラベルと組み合わせる必要があります。私は、レンダリングに使用された LaTeX コードを含む画像への相対パスを保存するデータセット クラスを作成しました (これはさらに改善する必要があります)。データセットのピクルス ファイルを生成するには、次のコマンドを実行します。
python -m pix2tex.dataset.dataset --equations path_to_textfile --images path_to_images --out dataset.pkl
独自のトークナイザーを使用するには、 --tokenizer経由で渡します (以下を参照)。
私が生成したトレーニング データは Google ドライブでも見つけることができます (formulae.zip - 画像、math.txt - ラベル)。検証データとテストデータに対してこの手順を繰り返します。すべて同じラベル テキスト ファイルを使用します。
構成ファイル内のdata (およびvaldata ) エントリを、新しく生成された.pklファイルに編集します。必要に応じて、他のハイパーパラメータを変更します。テンプレートについては、 pix2tex/model/settings/config.yaml参照してください。
さあ、実際のトレーニングの実行です
python -m pix2tex.train --config path_to_config_file
独自のデータを使用したい場合は、独自のトークナイザーを作成することに興味があるかもしれません。
python -m pix2tex.dataset.dataset --equations path_to_textfile --vocab-size 8000 --out tokenizer.json
構成ファイル内のトークナイザーへのパスを更新し、 num_tokens語彙サイズに設定することを忘れないでください。
モデルは、ResNet バックボーンを備えた ViT [1] エンコーダーと Transformer [2] デコーダーで構成されます。
| BLEUスコア | 正規化された編集距離 | トークンの精度 |
|---|---|---|
| 0.88 | 0.10 | 0.60 |
ネットワークが学習するにはペアになったデータが必要です。幸いなことに、ウィキペディアや arXiv など、インターネット上には LaTeX コードがたくさんあります。 im2latex-100k [3] データセットの式も使用します。すべてここで見つけることができます
さまざまなフォントで数式をレンダリングするために、XeLaTeX を使用し、PDF を生成し、最後にそれを PNG に変換します。最後のステップでは、いくつかのサードパーティ製ツールを使用する必要があります。
ゼラテックス
Ghostscript を使用した ImageMagick。 (PDFをPNGに変換するため)
KaTeX を実行するための Node.js (Latex コードを正規化するため)
Python 3.7 以降と依存関係 ( setup.pyで指定)
ラテン現代数学、GFSNeohellenicMath.otf、Asana Math、XITS Math、Cambria Math
さらに評価指標を追加する
GUIを作成する
ビームサーチを追加
手書きの数式をサポート (ほぼ完了しました。トレーニング用の colab ノートブックを参照してください)
モデルのサイズを小さくする (蒸留)
最適なハイパーパラメータを見つける
モデル構造を微調整する
データスクレイピングを修正し、より多くのデータをスクレイピング
モデルをトレースする (#2)
あらゆる種類の貢献を歓迎します。
lucidrains、rwightman、im2markup、arxiv_leaks、pkra: Mathjax、harpy: snipping Tool から取得および変更されたコード
[1] 画像は 16x16 ワードに相当します
[2] 必要なのは注意だけです
[3] 粗いものから細かいものまで注意を払った画像からマークアップへの生成


