segment anything
1.0.0
Segment Anything Model 2 (SAM 2)に関する新しいリリースをチェックしてください。
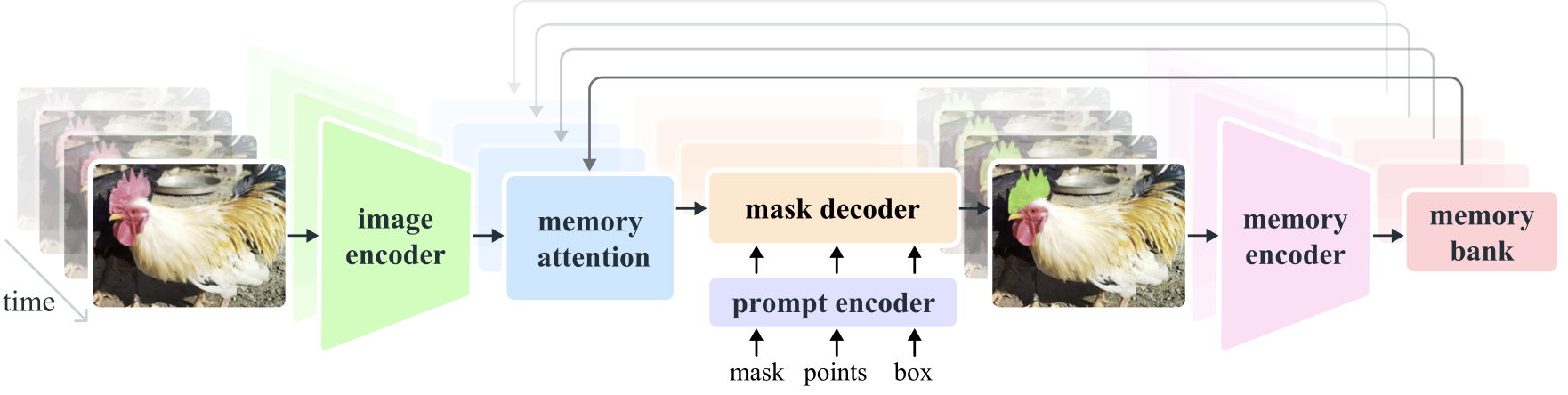
Segment Anything Model 2 (SAM 2) は、画像やビデオのプロンプト表示可能な視覚的セグメンテーションを解決するための基礎モデルです。画像を単一フレームのビデオとみなすことで、SAM をビデオに拡張します。モデルの設計は、リアルタイム ビデオ処理用のストリーミング メモリを備えたシンプルなトランスフォーマー アーキテクチャです。当社は、ユーザー インタラクションを通じてモデルとデータを改善するモデルインザループ データ エンジンを構築し、これまでで最大のビデオ セグメンテーション データセットである SA-V データセットを収集します。当社のデータに基づいてトレーニングされた SAM 2 は、幅広いタスクとビジュアル ドメインにわたって強力なパフォーマンスを提供します。
メタAIリサーチ、FAIR
アレクサンダー・キリロフ、エリック・ミンタン、ニキーラ・ラヴィ、ハンジ・マオ、クロエ・ロランド、ローラ・グスタフソン、テテ・シャオ、スペンサー・ホワイトヘッド、アレックス・バーグ、ワン・イェン・ロー、ピョートル・ダラー、ロス・ガーシック
[ Paper ] [ Project ] [ Demo ] [ Dataset ] [ Blog ] [ BibTeX ]
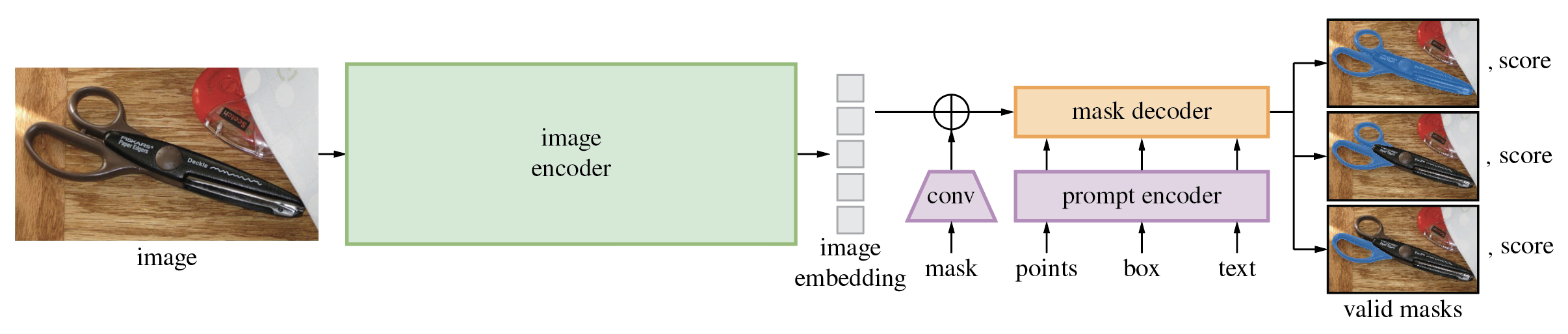
Segment Anything Model (SAM) は、ポイントやボックスなどの入力プロンプトから高品質のオブジェクト マスクを生成し、画像内のすべてのオブジェクトのマスクを生成するために使用できます。 1,100 万枚の画像と 11 億枚のマスクのデータセットでトレーニングされており、さまざまなセグメンテーション タスクで強力なゼロショット パフォーマンスを発揮します。


このコードにはpython>=3.8に加えて、 pytorch>=1.7およびtorchvision>=0.8が必要です。ここの手順に従って、PyTorch と TorchVision の両方の依存関係をインストールしてください。 CUDA サポートを備えた PyTorch と TorchVision の両方をインストールすることを強くお勧めします。
セグメントを何でもインストールします。
pip install git+https://github.com/facebookresearch/segment-anything.git
または、リポジトリのクローンをローカルに作成し、次のようにインストールします。
git clone [email protected]:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .
次のオプションの依存関係は、マスクの後処理、COCO 形式でのマスクの保存、サンプル ノートブック、および ONNX 形式でのモデルのエクスポートに必要です。サンプル ノートブックを実行するにはjupyterも必要です。
pip install opencv-python pycocotools matplotlib onnxruntime onnx
まずモデル チェックポイントをダウンロードします。その後、モデルをわずか数行で使用して、指定されたプロンプトからマスクを取得できます。
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
または画像全体のマスクを生成します。
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
さらに、コマンド ラインから画像のマスクを生成できます。
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
詳細については、プロンプトでの SAM の使用およびマスクの自動生成に関するサンプル ノートブックを参照してください。


SAM の軽量マスク デコーダは ONNX 形式にエクスポートできるため、デモで紹介されているブラウザ内など、ONNX ランタイムをサポートするあらゆる環境で実行できます。モデルをエクスポートする
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
SAM のバックボーンを介した画像前処理と ONNX モデルを使用したマスク予測を組み合わせる方法の詳細については、サンプル ノートブックを参照してください。 ONNX エクスポートには、PyTorch の最新の安定バージョンを使用することをお勧めします。
このdemo/フォルダーには、マルチスレッドを使用して Web ブラウザーでエクスポートされた ONNX モデルを使用してマスク予測を実行する方法を示す、シンプルな 1 ページの React アプリがあります。詳細については、 demo/README.mdを参照してください。
バックボーン サイズの異なる 3 つのモデル バージョンが用意されています。これらのモデルは、次のコマンドを実行することでインスタンス化できます。
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
以下のリンクをクリックして、対応するモデル タイプのチェックポイントをダウンロードします。
defaultまたはvit_h : ViT-H SAM モデル。vit_l : ViT-L SAM モデル。vit_b : ViT-B SAM モデル。 データセットの概要については、こちらをご覧ください。データセットはここからダウンロードできます。データセットをダウンロードすると、SA-1B データセット研究ライセンスの条項を読んで同意したことになります。
画像ごとのマスクを json ファイルとして保存します。以下の形式でPythonで辞書として読み込むことができます。
{
"image" : image_info ,
"annotations" : [ annotation ],
}
image_info {
"image_id" : int , # Image id
"width" : int , # Image width
"height" : int , # Image height
"file_name" : str , # Image filename
}
annotation {
"id" : int , # Annotation id
"segmentation" : dict , # Mask saved in COCO RLE format.
"bbox" : [ x , y , w , h ], # The box around the mask, in XYWH format
"area" : int , # The area in pixels of the mask
"predicted_iou" : float , # The model's own prediction of the mask's quality
"stability_score" : float , # A measure of the mask's quality
"crop_box" : [ x , y , w , h ], # The crop of the image used to generate the mask, in XYWH format
"point_coords" : [[ x , y ]], # The point coordinates input to the model to generate the mask
}画像 ID は sa_images_ids.txt で確認でき、上記のリンクを使用してダウンロードすることもできます。
COCO RLE 形式のマスクをバイナリにデコードするには:
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
RLE 形式で保存されたマスクを操作する手順の詳細については、ここを参照してください。
このモデルは、Apache 2.0 ライセンスに基づいてライセンスされています。
貢献と行動規範をご覧ください。
Segment Anything プロジェクトは、多くの貢献者 (アルファベット順) の協力により可能になりました。
アーロン・アドコック、ヴァイバブ・アガーワル、モルテザ・ベルース、チェンヤン・フー、アシュリー・ガブリエル、アフヴァ・ゴールドスタンド、アレン・グッドマン、スマンス・グラム、ジアボ・フー、ソミャ・ジェイン、デヴァンシュ・ククレジャ、ロバート・クオ、ジョシュア・レーン、ヤンハオ・リー、リリアン・ルオン、ジテンドラ・マリク、マリカ・マルホトラ、ウィリアム・ガン、オムカルパークヒ、ニキル・ライナ、ダーク・ロウ、ニール・セジョール、ヴァネッサ・スターク、バラ・ヴァラダラジャン、ブラム・ワスティ、ザカリー・ウィンストロム
研究で SAM または SA-1B を使用する場合は、次の BibTeX エントリを使用してください。
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}


