obfuscated gradients
v1.0.0
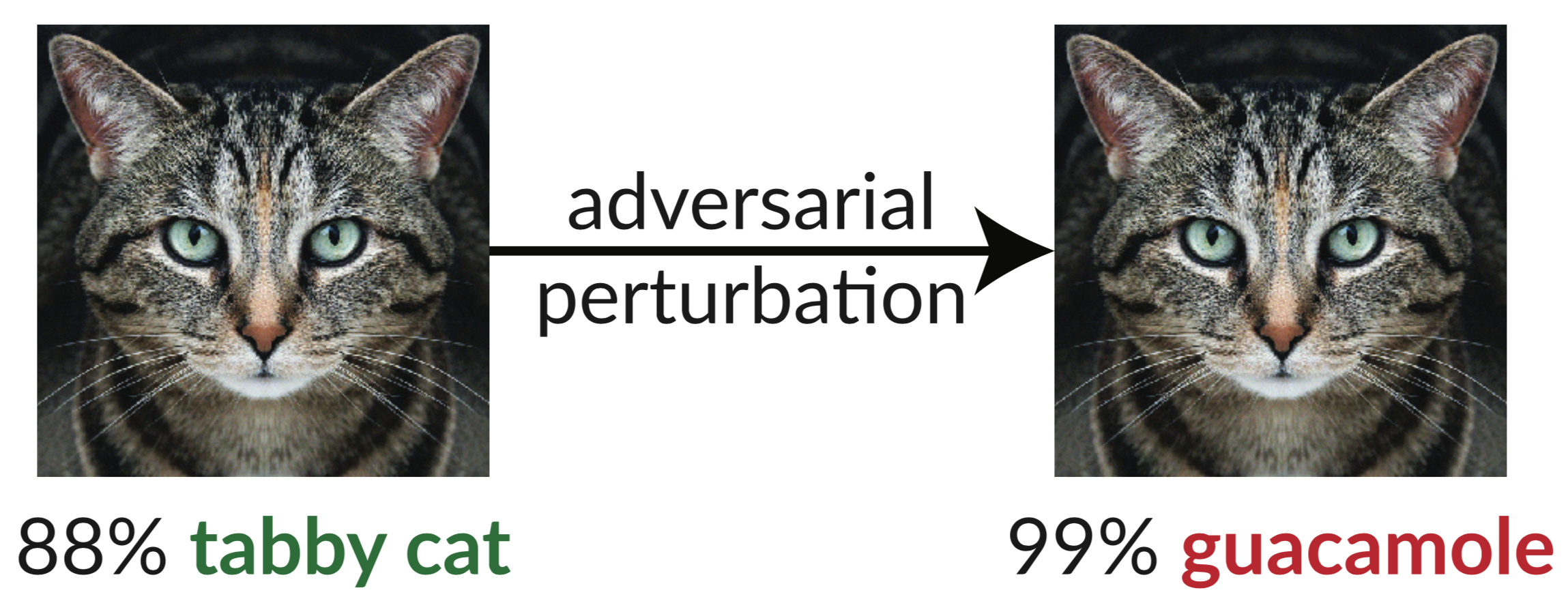
上は敵対的な例です。わずかに動揺した猫の画像は、InceptionV3 分類子を騙して「ワカモレ」として分類します。このような「だまし画像」は、勾配降下法を使用して簡単に合成できます (Szegedy et al. 2013)。
私たちの最近の論文では、敵対的な例に対する非認定のホワイトボックスセキュア防御として ICLR 2018 に受理された 9 つの論文の堅牢性を評価しています。 9 つの防御のうち 7 つは堅牢性の向上に限界があり、開発した改良された攻撃手法によって破られる可能性があることがわかりました。
以下は私たちの論文の表 1 です。ここでは、構築できる敵対的な例に対する、受け入れられている各防御の堅牢性を示しています。
| 防衛 | データセット | 距離 | 正確さ |
|---|---|---|---|
| バックマンら。 (2018) | シファール | 0.031 (リンフ) | 0%* |
| マら。 (2018) | シファール | 0.031 (リンフ) | 5% |
| 郭ら。 (2018) | イメージネット | 0.05(l2) | 0%* |
| ディロンら。 (2018) | シファール | 0.031 (リンフ) | 0% |
| 謝ら。 (2018) | イメージネット | 0.031 (リンフ) | 0%* |
| ソングら。 (2018) | シファール | 0.031 (リンフ) | 9%* |
| サマンゴーエイら。 (2018) | MNIST | 0.005(l2) | 55%** |
| マドリーら。 (2018) | シファール | 0.031 (リンフ) | 47% |
| ナら。 (2018) | シファール | 0.015 (リンフ) | 15% |
(* で示された防御は、敵対的トレーニングの組み合わせも提案しています。ここでは防御のみを報告します。完全な数値については、論文のセクション 5 を参照してください。** で示された防御の背後にある基本原則の精度は 0% です。実際には、防御の不完全性が理論的には失敗する最適な攻撃、詳細についてはセクション 5.4.2 を参照してください。)
提案された脅威モデル内で敵対的な例に対する堅牢性が大幅に向上することが確認された唯一の防御策は、「敵対的攻撃に耐性のある深層学習モデルに向けて」(Madry et al. 2018) であり、脅威モデルの外に出ずにこの防御策を破ることはできませんでした。 。それでも、この手法を ImageNet スケールに拡張するのは難しいことが示されています (Kurakin et al. 2016)。論文の残りの部分 (堅牢性が限定的である Na らによる論文を除く) は、不注意または意図的に、いわゆる難読化勾配に依存しています。標準的な攻撃では、勾配降下法を適用して、特定の画像に対するネットワークの損失を最大化し、ニューラル ネットワーク上に敵対的な例を生成します。このような最適化方法が成功するには、有用な勾配信号が必要です。防御が勾配を難読化すると、この勾配信号が破壊され、最適化ベースのメソッドが失敗します。
私たちは、防御が難読化された勾配を引き起こす 3 つの方法を特定し、これらのそれぞれのケースを回避する攻撃を構築します。私たちの攻撃は通常、意図的か非意図的かに関わらず、微分不可能な演算を含む、あるいは勾配信号がネットワークを流れるのを妨げるあらゆる防御に適用できます。今後の作業では、私たちのアプローチを使用して、より徹底的なセキュリティ評価を実行できることを期待しています。
抽象的な:
私たちは、難読化された勾配 (勾配マスキングの一種) を、敵対的な例に対する防御において誤った安全感をもたらす現象として特定します。難読化された勾配を引き起こす防御は反復最適化ベースの攻撃を打ち破るように見えますが、この効果に依存した防御は回避できることがわかりました。私たちは、その効果を示す防御の特徴的な動作を説明し、発見された 3 種類の難読化勾配のそれぞれについて、それを克服するための攻撃手法を開発します。 ICLR 2018 で認定されていないホワイトボックスの安全な防御を調査したケーススタディでは、難読化された勾配が一般的に発生しており、9 つの防御のうち 7 つが難読化された勾配に依存していることがわかりました。私たちの新しい攻撃は、各論文が考慮している元の脅威モデルの 6 を完全に回避し、1 を部分的に回避することに成功しました。
詳細については、論文をお読みください。
このリポジトリには、ICLR 2018 の防御策の 7 つを突破する、論文で説明されている一般的な攻撃手法のインスタンス化が含まれています。一部の防御策はソース コードを公開していなかったので (この作業を行った時点では)、それらを再実装する必要がありました。
@inproceedings{obfuscated-gradients、著者 = {Anish Athalye、Nicholas Carlini、David Wagner}、title = {難読化されたグラデーションがセキュリティの誤った感覚を与える: 敵対的な例に対する防御の回避}、booktitle = {第 35 回国際機械会議議事録学習、{ICML} 2018}、年 = {2018}、月 = 7 月、URL = {https://arxiv.org/abs/1802.00420}、
} 

