pygwalker
0.4.9.9
英語 |スペイン語 |フランセ |ドイツ語 | 中国語 |テュルクチェ | 日本語 | 한국어
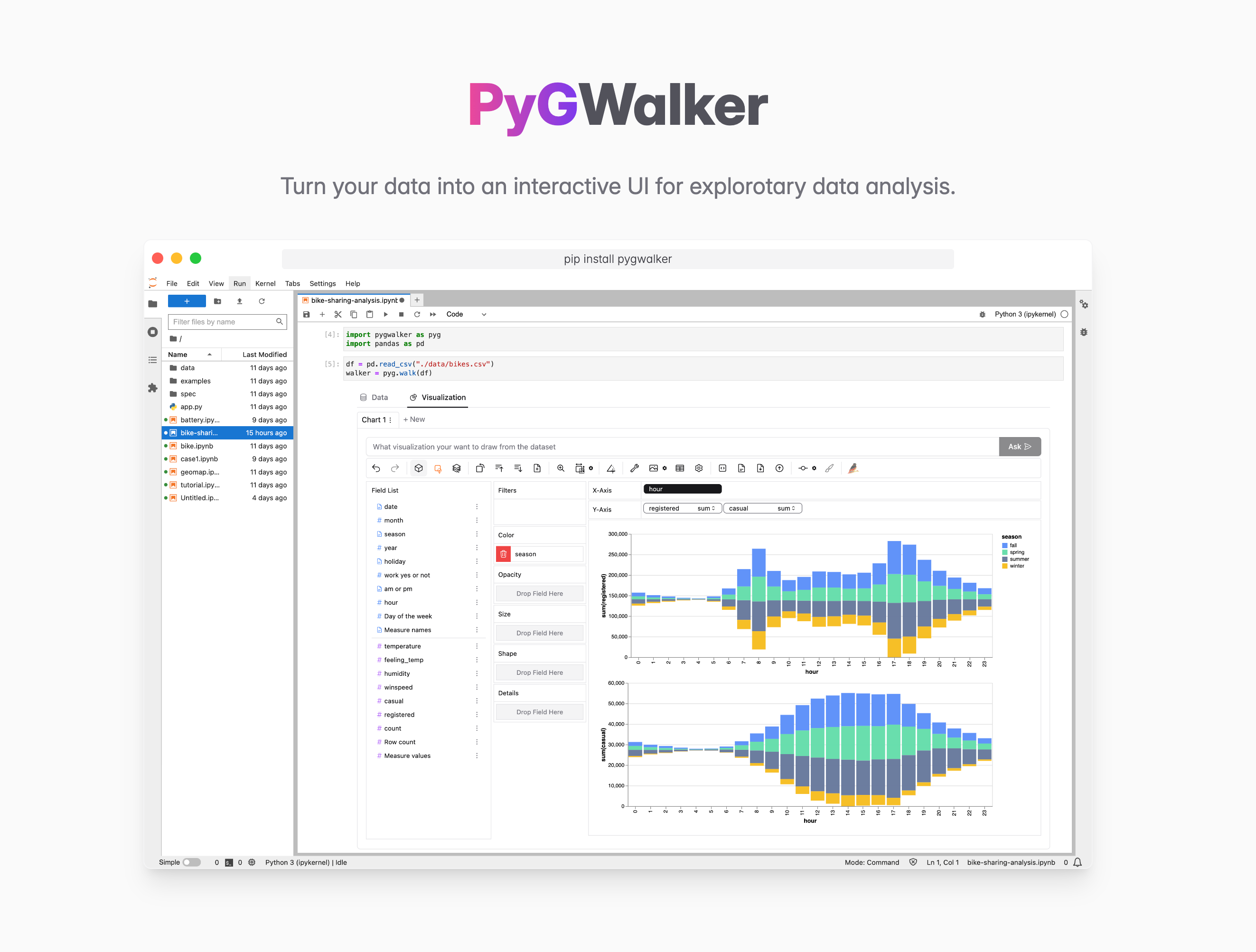
PyGWalker は、 pandas データフレームを視覚的な探索のためのインタラクティブなユーザー インターフェイスに変えることで、Jupyter Notebook のデータ分析とデータ視覚化のワークフローを簡素化できます。
PyGWalker (面白半分で「ピッグ ウォーカー」と発音します) は、「 G raphic WalkerのPy thon binding 」の略語として名前が付けられています。 Jupyter Notebook と、Tableau の代替オープンソースである Graphic Walker を統合します。これにより、データ サイエンティストは、単純なドラッグ アンド ドロップ操作や自然言語クエリでデータを視覚化/クリーニング/注釈付けすることができます。
Google Colab、Kaggle コード、または Graphic Walker オンライン デモにアクセスしてテストしてください。
R を使用したい場合は、Graphic Walker の R ラッパーである GWalkR を確認してください。
pygwalker、pygwalker + streamlit、pygwalker + Snowflake の使用に関するビデオ チュートリアル、Python で PyGWalker を使用してデータを探索する方法を確認してください。
| Kaggle で実行する | Colab で実行する |
|---|---|
pygwalker を使用する前に、pip または conda を使用してコマンド ラインからパッケージをインストールしてください。
pip インストール pygwalker
注記
初期トライアルの場合は、
pip install pygwalker --upgradeを使用してインストールしてバージョンを最新のリリースに保つことができます。また、pip install pygwalker --upgrade --pre使用して最新の機能とバグ修正を入手することもできます。
conda install -c conda-forge pygwalker
または
mamba install -c conda-forge pygwalker
詳細については、conda-forge フィードストックを参照してください。
開始するには、pygwalker と pandas を Jupyter Notebook にインポートします。
パンダを pd としてインポート pygwalker を pyg としてインポート
既存のワークフローを中断することなく pygwalker を使用できます。たとえば、次の方法でデータフレームをロードして PyGWalker を呼び出すことができます。
df = pd.read_csv('./bike_sharing_dc.csv')walker = pyg.walk(df)それでおしまい。これで、簡単なドラッグ アンド ドロップ操作でデータを分析および視覚化できる対話型 UI が完成しました。
PyGwalker でできる素晴らしいこと:
マーク タイプを他のものに変更して、別のグラフ (折れ線グラフなど) を作成できます。 
異なるメジャーを比較するには、複数のメジャーを行/列に追加して連結ビューを作成します。 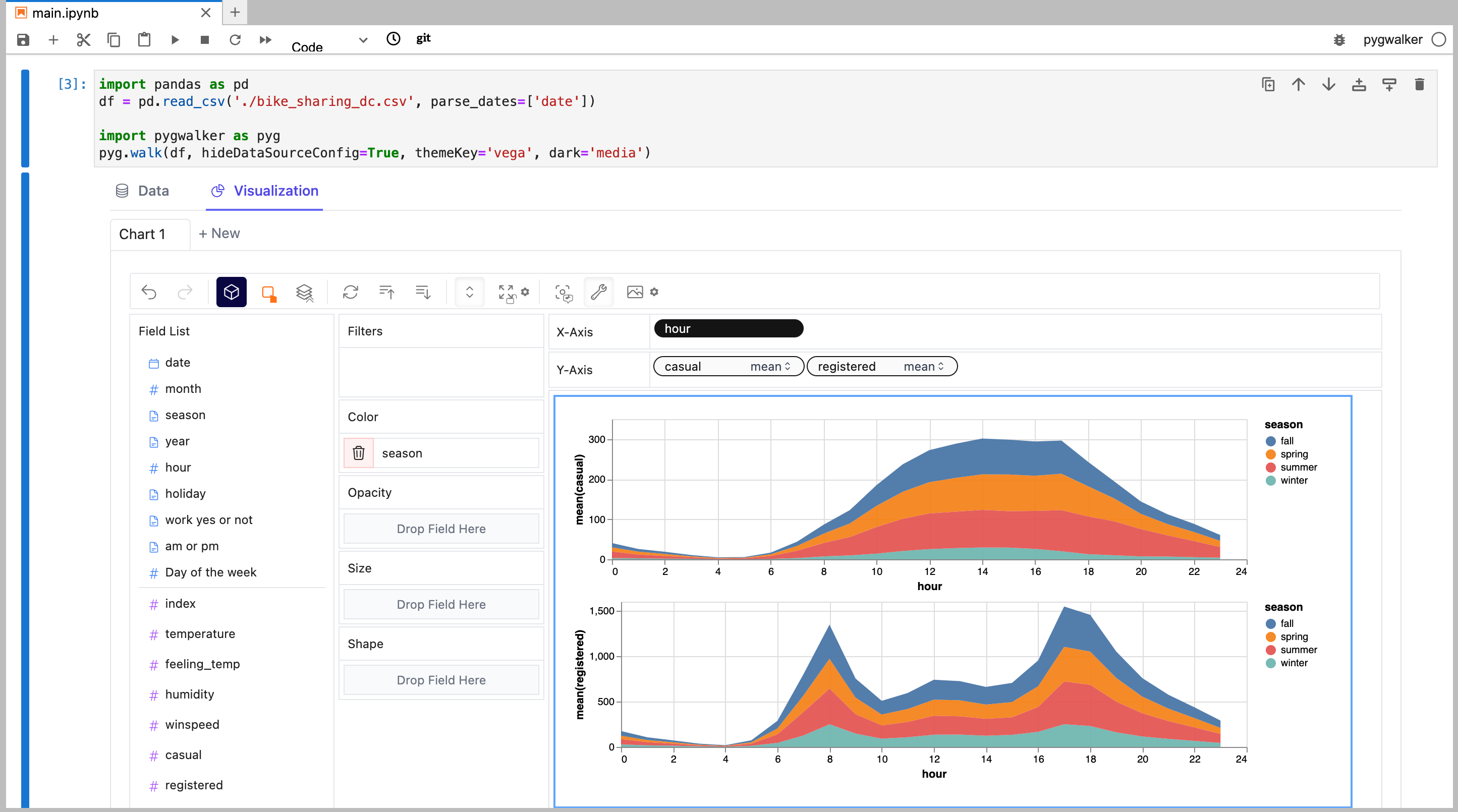
ディメンションの値で分割された複数のサブビューのファセット ビューを作成するには、ディメンションを行または列に配置してファセット ビューを作成します。 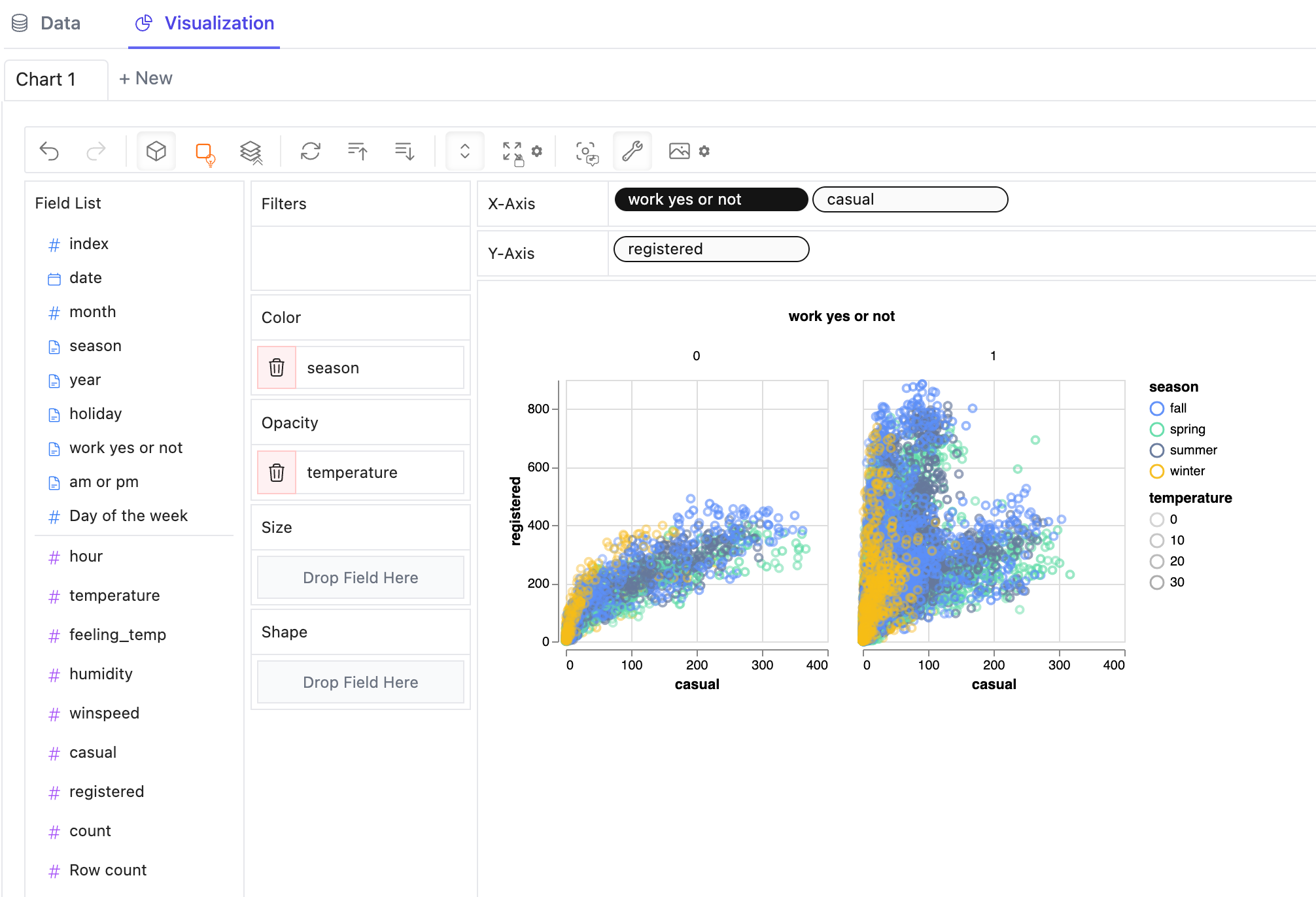
PyGWalker には強力なデータ テーブルが含まれており、データとその分布、プロファイリングを簡単に表示できます。フィルターを追加したり、テーブル内のデータ型を変更したりすることもできます。
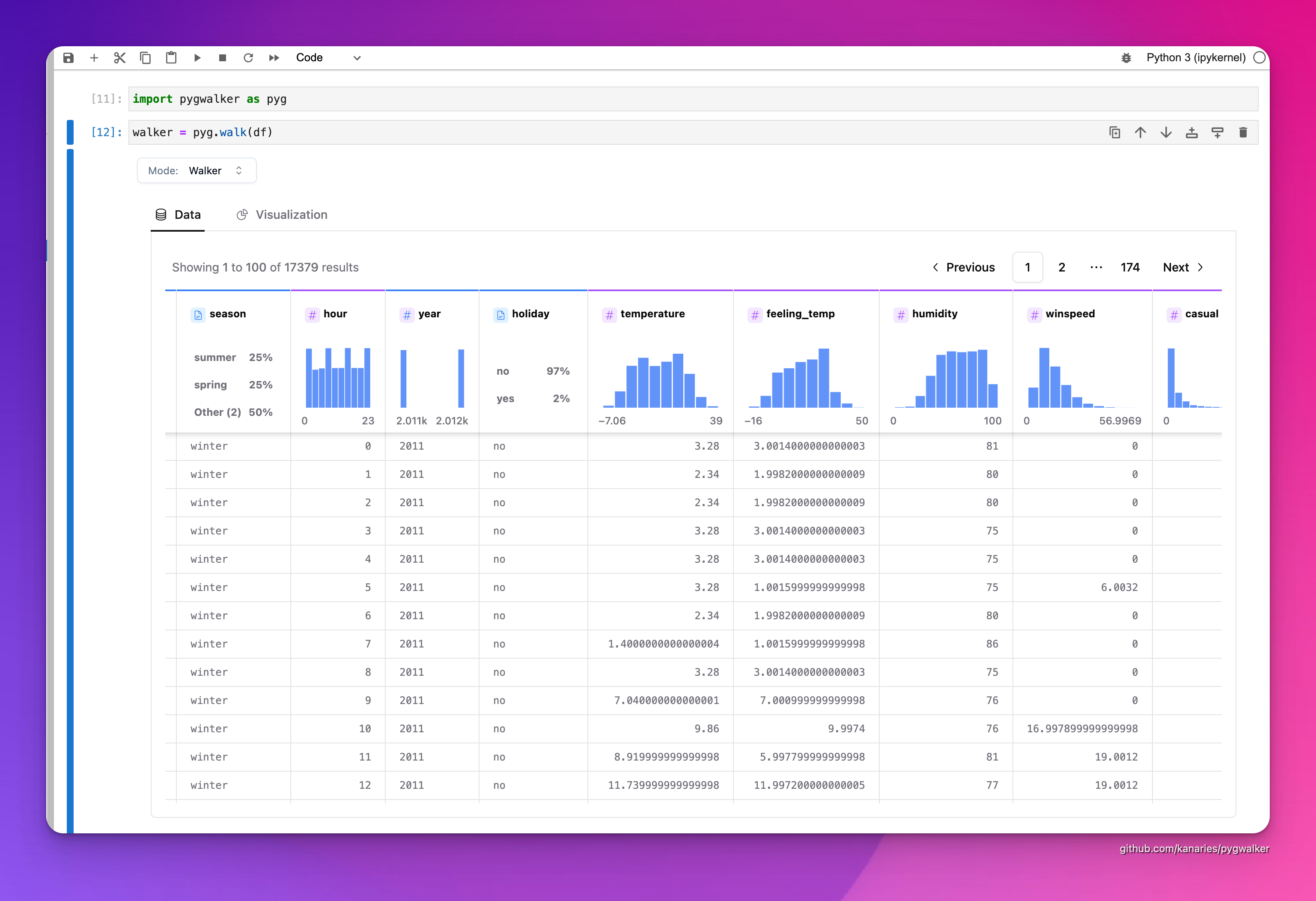
データ探索結果をローカル ファイルに保存できます
pygwalker を使用するときに知っておくべき重要なパラメーターがいくつかあります。
spec : チャート設定の保存/読み込み用 (json 文字列またはファイル パス)
kernel_computation : コンピューティング エンジンとして duckdb を使用すると、ローカル マシンでより大きなデータセットをより高速に処理できるようになります。
use_kernel_calc : 非推奨です。代わりにkernel_computation使用してください。
df = pd.read_csv('./bike_sharing_dc.csv')walker = pyg.walk(df,spec="./chart_meta_0.json", # この JSON ファイルはチャートの状態を保存します。UI の保存ボタンをクリックする必要がありますチャートを終了するときに手動で行うと、「自動保存」が将来サポートされる予定です。kernel_computation=True, # set `kernel_computation=True` の場合、pygwalker はコンピューティング エンジンとして duckdb を使用し、より大きなデータセット (<=100GB) の探索をサポートします。)ノートブックコード: ここをクリックしてください
ノートブック HTML のプレビュー: ここをクリック
Kaggle で PyGWalker を使用する
Google Colab で PyGWalker を使用する
Streamlit を使用すると、Web アプリケーションがどのように動作するかを詳細に理解することなく、Web バージョンの pygwalker をホストできます。
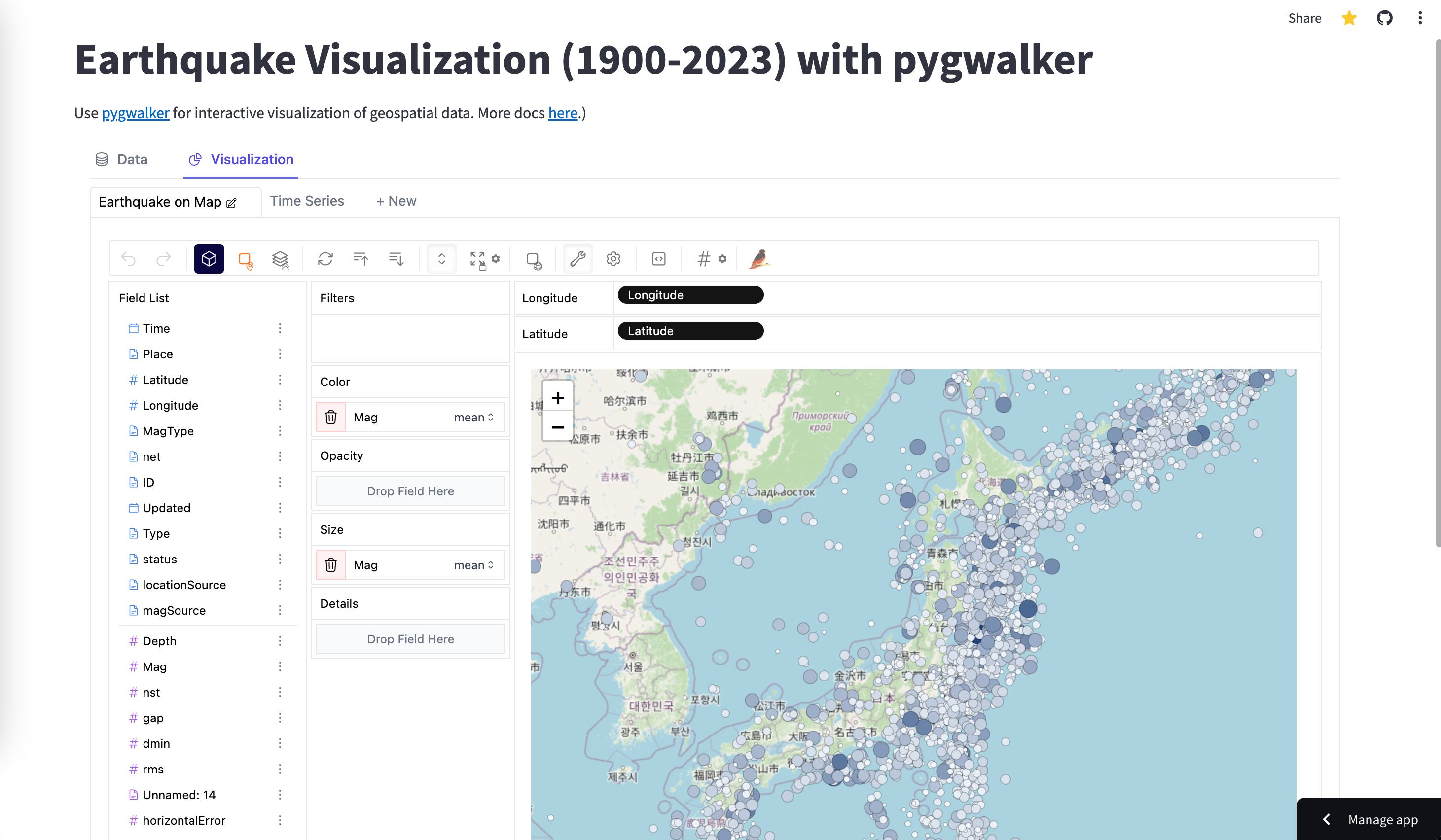
pygwalker と streamlit を使用して構築されたアプリの例の一部を次に示します。
PyGWalker + streamlit 自転車共有データセット用
地震ダッシュボード
from pygwalker.api.streamlit import StreamlitRendererimport pandas as pdimport streamlit as st# Streamlit の幅を調整します pagest.set_page_config(page_title="Use Pygwalker In Streamlit",layout="wide")# Add Titlest.title("Use Pygwalker In Streamlit")# メモリを使いたくない場合は、pygwalker レンダラーをキャッシュする必要があります。 [email protected]_resourcedef get_pyg_renderer() -> "StreamlitRenderer":df = pd.read_csv("./bike_sharing_dc.csv")# チャート設定の保存機能を使用したい場合は、`spec_io_mode="rw"`return StreamlitRenderer を設定してください(df, spec="./gw_config.json", spec_io_mode="rw")renderer = get_pyg_renderer()renderer.explorer()| パラメータ | タイプ | デフォルト | 説明 |
|---|---|---|---|
| データセット | ユニオン[データフレーム、コネクタ] | - | 使用するデータフレームまたはコネクタ。 |
| ギド | Union[int, str] | なし | GraphicWalker コンテナ div の ID。「gwalker-{gid}」の形式で指定します。 |
| 環境 | リテラル['Jupyter', 'JupyterWidget'] | 「ジュピターウィジェット」 | pygwalkerを使用した環境。 |
| フィールドスペック | オプション[Dict[str, FieldSpec]] | なし | フィールドの仕様。指定しない場合は、 datasetから自動的に推測されます。 |
| Hide_data_source_config | ブール | 真実 | True の場合、DataSource のインポートおよびエクスポート ボタンが非表示になります。 |
| テーマキー | リテラル['ベガ', 'g2'] | 「g2」 | GraphicWalker のテーマのタイプ。 |
| 外観 | リテラル['メディア', 'ライト', 'ダーク'] | 'メディア' | テーマ設定。 「メディア」は OS テーマを自動検出します。 |
| スペック | str | 「」 | チャート構成データ。構成 ID、JSON、またはリモート ファイル URL を指定できます。 |
| use_preview | ブール | 真実 | True の場合、プレビュー機能を使用します。 |
| カーネル計算 | ブール | 間違い | True の場合、データにカーネル計算を使用します。 |
| **クワーグス | どれでも | - | 追加のキーワード引数。 |
参照: ローカル開発
ジュピターノートブック
Googleコラボ
Kaggle コード
ジュピターラボ
ジュピター ライト
Databricks ノートブック (バージョン0.1.4a0以降)
Visual Studio Code 用の Jupyter 拡張機能 (バージョン0.1.4a0以降)
ほとんどの Web アプリケーションは IPython カーネルと互換性があります。 (バージョン0.1.4a0以降)
Streamlit (バージョン0.1.4.9以降) 、 pyg.walk(df, env='Streamlit')で有効化
DataCamp ワークスペース (バージョン0.1.4a0以降)
パネル。パネルグラフィックウォーカーを参照してください。
マリモ (バージョン0.4.9.11以降)
ヘックスプロジェクト
...その他の環境についてもお気軽に問題を提起してください。
pygwalker config使用してプライバシー構成を設定できます。
$ pygwalker config --help
使用法: pygwalker config [-h] [--set [key=value ...]] [--reset [key ...]] [--reset-all] [--list]
設定ファイルを変更します。 (デフォルト: ~/ライブラリ/Application Support/pygwalker/config.json)
利用可能な構成:
- プライバシー ['オフライン'、'更新のみ'、'イベント'] (デフォルト: イベント)。「オフライン」: 完全にオフライン、データは送信されず、API も要求されません。「更新のみ」: これが更新かどうかのみを確認します。 「イベント」を更新する pygwalker の新しいバージョン: pygwalker で使用される機能に関するイベントを共有します。これには、製品の最適化のために到着した機能に関するイベント データのみが含まれます。分析したデータは送信されません。イベント データは、pygwalker のインストール時にタイムスタンプに基づいて生成される一意の ID にバインドされます。当社はお客様に関するその他の情報を収集しません。
- kanaries_token ['あなたのカナリーズトークン'] (デフォルト: 空の文字列)。
Kanaries トークンは、https://kanaries.net から取得できます。
参照: https://space.kanaries.net/t/how-to-get-api-key-of-kanaries。
kanaries トークンを使用すると、pygwalker で共有チャート、共有設定などの kanaries サービスを使用できるようになります。
オプション: -h、--help このヘルプ メッセージを表示して終了します
--set [キー=値 ...]
構成を設定します。例: 「pygwalker config --set Privacy=update-only」
--reset [key ...] ユーザー設定をリセットし、代わりにデフォルト値を使用します。例: 「pygwalker config --reset Privacy」
--reset-all すべてのユーザー設定をリセットし、代わりにデフォルト値を使用します。例: 「pygwalker config --reset-all」
--list 現在使用されている構成をリストします。詳細については、「プライバシー構成を設定するにはどうすればよいですか?」を参照してください。
Apache ライセンス 2.0
PyGWalkerクラウドがリリースされました!グラフをクラウドに保存し、インタラクティブなセルを Web アプリとして公開し、GPT を利用した高度な機能を使用できるようになりました。詳細については、PyGWalker Cloud を確認してください。
Kanaries PyGWalker で PyGWalker に関するその他のリソースを確認してください。
PyGWalker ペーパー PyGWalker: 探索的ビジュアル データ分析のためのオンザフライ アシスタント
また、AI を活用した自動化でデータのラングリング、探索、視覚化のワークフローを再定義する、オープンソースの自動探索的データ分析ソフトウェアである RATH にも取り組んでいます。詳細については、Kanaries Web サイトと RATH GitHub をチェックしてください。
Youtube: Python で PyGWalker を使用してデータを探索する方法
pygwalker を使用して、streamlit でビジュアル分析アプリを構築する
Panel-graphic-walker を使用して、Panel でデータ視覚化アプリを構築します。
問題が発生し、サポートが必要な場合は、Discord チャンネルに参加するか、github で問題を提起してください。
気に入ったら、これらのソーシャル メディア プラットフォームで pygwalker を共有してください。


