Megatron LM
NVIDIA Megatron Core 0.9.0
このリポジトリは、 Megatron-LMとMegatron-Core という2 つの重要なコンポーネントで構成されます。 Megatron-LM は、大規模言語モデル (LLM) トレーニングに Megatron-Core を活用する研究指向のフレームワークとして機能します。一方、Megatron-Core は、GPU に最適化されたトレーニング手法のライブラリであり、バージョン管理された API や通常のリリースを含む正式な製品サポートが付属しています。 Megatron-Core を Megatron-LM または Nvidia NeMo フレームワークと併用して、エンドツーエンドのクラウドネイティブ ソリューションを実現できます。あるいは、Megatron-Core の構成要素を好みのトレーニング フレームワークに統合することもできます。
2019 年に初めて導入された Megatron (1、2、および 3) は AI コミュニティにイノベーションの波を引き起こし、研究者や開発者がこのライブラリの基盤を利用して LLM をさらに進歩できるようにしました。現在、最も人気のある LLM 開発者フレームワークの多くは、オープンソースの Megatron-LM ライブラリからインスピレーションを受け、直接活用して構築されており、基盤モデルと AI スタートアップの波を引き起こしています。 Megatron-LM 上に構築された最も人気のある LLM フレームワークには、Colossal-AI、HuggingFace Accelerate、NVIDIA NeMo Framework などがあります。 Megatron を直接使用したプロジェクトのリストは、ここにあります。
Megatron-Core は、GPU に最適化された技術と最先端のシステムレベルの最適化を含む、オープンソースの PyTorch ベースのライブラリです。それらをコンポーザブルなモジュラー API に抽象化し、開発者やモデル研究者が、NVIDIA アクセラレーション コンピューティング インフラストラクチャ上でカスタム トランスフォーマーを大規模にトレーニングできる完全な柔軟性を可能にします。このライブラリは、NVIDIA Hopper アーキテクチャの FP8 アクセラレーション サポートを含む、すべての NVIDIA Tensor コア GPU と互換性があります。
Megatron-Core は、アテンション メカニズム、トランスフォーマー ブロックとレイヤー、正規化レイヤー、埋め込み技術などのコア ビルディング ブロックを提供します。アクティベーションの再計算、分散チェックポイントなどの追加機能もライブラリにネイティブに組み込まれています。ビルディング ブロックと機能はすべて GPU に最適化されており、NVIDIA アクセラレーテッド コンピューティング インフラストラクチャ上で最適なトレーニング速度と安定性を実現する高度な並列化戦略を使用して構築できます。 Megatron-Core ライブラリのもう 1 つの重要なコンポーネントには、高度なモデル並列処理技術 (テンソル、シーケンス、パイプライン、コンテキスト、および MoE エキスパート並列処理) が含まれています。
Megatron-Core は、エンタープライズ グレードの AI プラットフォームである NVIDIA NeMo で使用できます。あるいは、ここでネイティブ PyTorch トレーニング ループを使用して Megatron-Core を探索することもできます。詳細については、Megatron-Core のドキュメントを参照してください。
私たちのコードベースは、モデルとデータの両方の並列処理を使用して、大規模な言語モデル (つまり、数千億のパラメーターを持つモデル) を効率的にトレーニングできます。ソフトウェアが複数の GPU とモデル サイズに合わせてどのように拡張されるかを示すために、20 億パラメーターから 4,620 億パラメーターの範囲の GPT モデルを検討します。すべてのモデルは、語彙サイズ 131,072、シーケンス長 4096 を使用します。特定のモデル サイズに到達するために、隠れサイズ、アテンション ヘッドの数、およびレイヤーの数を変更します。モデル サイズが増加するにつれて、バッチ サイズも適度に増加します。私たちの実験では最大 6144 個の H100 GPU を使用します。データ並列 ( --overlap-grad-reduce --overlap-param-gather )、テンソル並列 ( --tp-comm-overlap )、およびパイプライン並列通信 (デフォルトで有効) のきめ細かいオーバーラップを実行します。スケーラビリティを向上させるための計算。報告されるスループットはエンドツーエンドのトレーニングに対して測定され、データの読み込み、オプティマイザーのステップ、通信、さらにはログ記録を含むすべての操作が含まれます。これらのモデルを収束するようにトレーニングしていないことに注意してください。
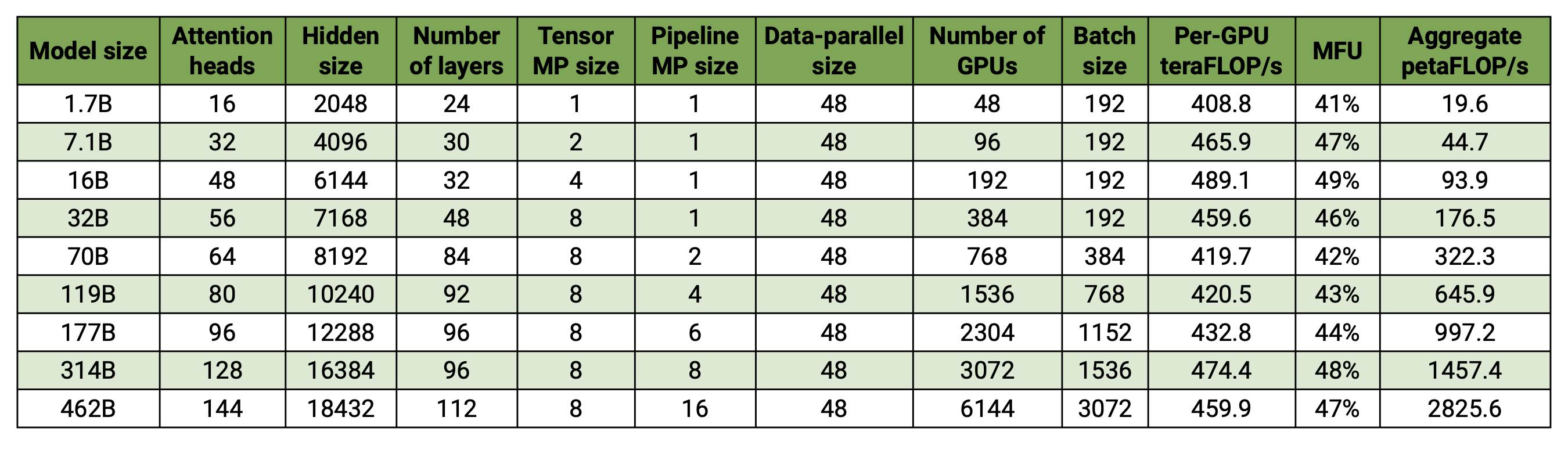
弱いスケーリングの結果は、超線形スケーリングを示しています (MFU は、考慮された最小モデルの 41% から、最大モデルの 47 ~ 48% に増加します)。これは、GEMM が大きいほど演算強度が高く、その結果、実行効率が高くなるためです。
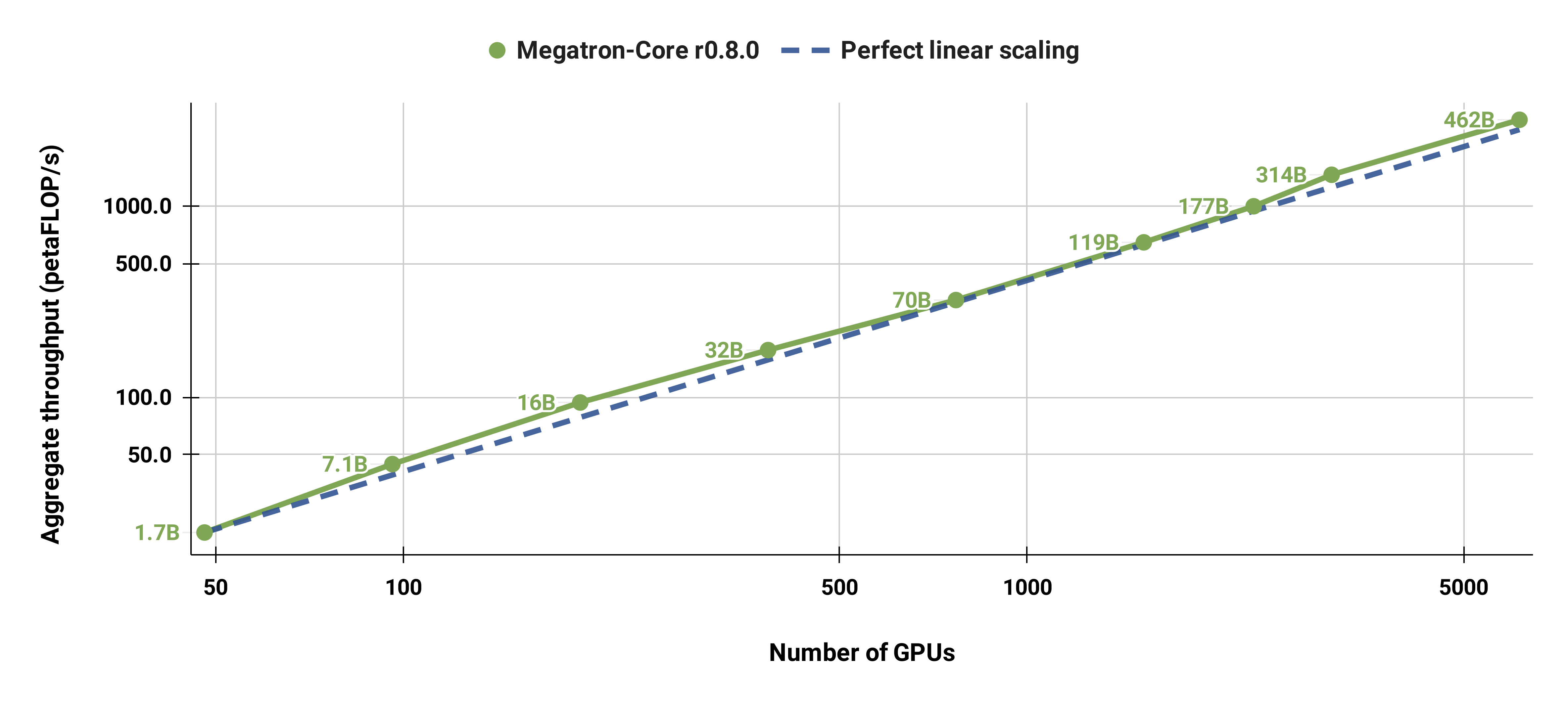
また、全体を通して同じバッチ サイズの 1152 シーケンスを使用して、標準 GPT-3 モデル (語彙サイズが大きいため、私たちのバージョンには 1750 億をわずかに超えるパラメーターがあります) を 96 H100 GPU から 4608 GPU に強力に拡張しました。大規模になると通信の露出が増加し、MFU が 47% から 42% に減少します。
DGX ノードでは NGC の PyTorch コンテナの最新リリースを使用することを強くお勧めします。何らかの理由でこれを使用できない場合は、最新の pytorch、cuda、nccl、および NVIDIA APEX リリースを使用してください。データの前処理には NLTK が必要ですが、トレーニング、評価、またはダウンストリーム タスクには必要ありません。
次の Docker コマンドを使用して、PyTorch コンテナーのインスタンスを起動し、Megatron、データセット、チェックポイントをマウントできます。
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3
docker run --gpus all -it --rm -v /path/to/megatron:/workspace/megatron -v /path/to/dataset:/workspace/dataset -v /path/to/checkpoints:/workspace/checkpoints nvcr.io/nvidia/pytorch:xx.xx-py3
下流タスクの評価または微調整のために、事前トレーニングされた BERT-345M および GPT-345M チェックポイントを提供しました。これらのチェックポイントにアクセスするには、まず NVIDIA GPU クラウド (NGC) レジストリ CLI にサインアップしてセットアップします。モデルのダウンロードに関する詳細なドキュメントは、NGC ドキュメントにあります。
あるいは、以下を使用してチェックポイントを直接ダウンロードすることもできます。
BERT-345M-uncased: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O megatron_bert_345m_v0.1_uncased.zip BERT-345M ケース: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O megatron_bert_345m_v0.1_cased.zip GPT-345M: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
モデルを実行するには語彙ファイルが必要です。 BERT WordPiece 語彙ファイルは、Google の事前トレーニング済み BERT モデル (大文字小文字なし、大文字小文字あり) から抽出できます。 GPT 語彙ファイルとマージ テーブルは直接ダウンロードできます。
インストール後は、いくつかのワークフローが考えられます。最も包括的なものは次のとおりです。
ただし、ステップ 1 と 2 は、上記の事前トレーニング済みモデルのいずれかを使用して置き換えることができます。
BERT と GPT の両方を事前トレーニングするためのいくつかのスクリプトがexamplesディレクトリに用意されています。また、MNLI、RACE、WikiText103、LAMBADA 評価などのゼロショット タスクと微調整されたダウンストリーム タスクの両方用のスクリプトも提供されています。 GPT インタラクティブ テキスト生成用のスクリプトもあります。
トレーニング データには前処理が必要です。まず、トレーニング データを緩やかな JSON 形式で配置します。1 行にテキスト サンプルを含む 1 つの JSON が含まれます。例えば:
{"src": "www.nvidia.com", "text": "The Quick Brown fox", "type": "Eng", "id": "0", "title": "最初のパート"}
{"src": "インターネット", "text": "怠惰な犬を飛び越える", "type": "Eng", "id": "42", "title": "第二部"}
json のtextフィールドの名前は、 preprocess_data.pyの--json-keyフラグを使用して変更できます。他のメタデータはオプションであり、トレーニングでは使用されません。
次に、ルーズな JSON はトレーニング用にバイナリ形式に処理されます。 json を mmap 形式に変換するには、 preprocess_data.pyを使用します。 BERT トレーニング用のデータを準備するスクリプトの例は次のとおりです。
Python ツール/preprocess_data.py
--input my-corpus.json
--output-prefix my-bert
--vocab-file bert-vocab.txt
--tokenizer-type BertWordPieceLowerCase
--分割文
出力は、この場合、 my-bert_text_sentence.binおよびmy-bert_text_sentence.idxという名前の 2 つのファイルになります。後の BERT トレーニングで指定される--data-path 、ファイル拡張子を除いた完全なパスと新しいファイル名です。
T5 の場合は、BERT と同じ前処理を使用し、名前を次のように変更します。
--output-prefix my-t5
GPT データの前処理には、いくつかの小さな変更が必要です。つまり、マージ テーブルの追加、文書末尾トークン、文分割の削除、トークナイザー タイプの変更です。
Python ツール/preprocess_data.py
--input my-corpus.json
--output-prefix my-gpt2
--vocab-file gpt2-vocab.json
--tokenizer-type GPT2BPETokenizer
--merge-file gpt2-merges.txt
--append-eod
ここで、出力ファイルの名前はmy-gpt2_text_document.binおよびmy-gpt2_text_document.idxです。前と同様に、GPT トレーニングでは、 --data-pathとして拡張子のない長い名前を使用します。
その他のコマンド ライン引数は、ソース ファイルpreprocess_data.pyで説明されています。
examples/bert/train_bert_340m_distributed.shスクリプトは、単一 GPU 345M パラメーターの BERT 事前トレーニングを実行します。コード ベースとコマンド ライン引数は高度に分散されたトレーニング用に最適化されているため、単一 GPU トレーニングの主な用途はデバッグです。ほとんどの議論は一目瞭然です。デフォルトでは、学習率は、 --lrから開始して、 --lr-decay-iters反復にわたって--min-lrで設定された最小値まで、トレーニング反復にわたって線形に減衰します。ウォームアップに使用されるトレーニング反復の割合は、 --lr-warmup-fractionによって設定されます。これは単一 GPU トレーニングですが、 --micro-batch-sizeで指定されたバッチ サイズは単一の順方向/逆方向パスのバッチ サイズであり、コードはバッチ サイズであるglobal-batch-sizeに達するまで勾配累積ステップを実行します。反復ごとに。データは、トレーニング/検証/テスト セットの比率 949:50:1 に分割されます (デフォルトは 969:30:1)。この分割は実行中に行われますが、同じランダム シード (デフォルトでは 1234、または--seedで手動で指定) を使用した実行間で一貫性があります。要求されたトレーニング反復としてtrain-iters使用します。あるいは、トレーニングするサンプルの総数である--train-samplesを指定することもできます。このオプションが存在する場合は、 --lr-decay-itersを指定する代わりに、 --lr-decay-samples指定する必要があります。
ログ記録、チェックポイント保存、および評価間隔のオプションが指定されます。 --data-pathは、前処理で追加された追加の_text_sentenceサフィックスが含まれるようになりましたが、ファイル拡張子は含まれないことに注意してください。
その他のコマンド ライン引数は、ソース ファイルarguments.pyで説明されています。
train_bert_340m_distributed.sh実行するには、 CHECKPOINT_PATH 、 VOCAB_FILE 、およびDATA_PATHの環境変数の設定を含む必要な変更を加えます。これらの変数をコンテナ内のパスに設定してください。次に、Megatron と必要なパスがマウントされたコンテナーを起動し (セットアップで説明したように)、サンプル スクリプトを実行します。
examples/gpt3/train_gpt3_175b_distributed.shスクリプトは、単一 GPU 345M パラメーターの GPT 事前トレーニングを実行します。前述したように、コードは分散トレーニング用に最適化されているため、単一 GPU トレーニングは主にデバッグ目的を目的としています。
これは、以前の BERT スクリプトとほぼ同じ形式に従いますが、いくつかの顕著な違いがあります。使用されるトークン化スキームは WordPiece ではなく BPE (マージ テーブルとjsonボキャブラリ ファイルが必要) であり、モデル アーキテクチャはより長いシーケンスを許可します (最大位置の埋め込みは最大シーケンス長以上でなければなりません)、 --lr-decay-styleコサイン減衰に設定されています。 --data-pathは、前処理で追加された追加の_text_documentサフィックスが含まれるようになりましたが、ファイル拡張子は含まれないことに注意してください。
その他のコマンド ライン引数は、ソース ファイルarguments.pyに説明されています。
train_gpt3_175b_distributed.sh 、BERT で説明したのと同じ方法で起動できます。環境変数を設定してその他の変更を行い、適切なマウントでコンテナを起動して、スクリプトを実行します。詳細については、 examples/gpt3/README.mdを参照してください。
BERT および GPT と非常によく似ており、 examples/t5/train_t5_220m_distributed.shスクリプトは、単一 GPU の「ベース」(~220M パラメータ) T5 事前トレーニングを実行します。 BERT および GPT との主な違いは、T5 アーキテクチャに対応するために次の引数が追加されていることです。
--kv-channelsモデル内のすべてのアテンション メカニズムの「キー」行列と「値」行列の内部次元を設定します。 BERT および GPT の場合、これはデフォルトで非表示サイズをアテンション ヘッドの数で割った値になりますが、T5 に対して構成できます。
--ffn-hidden-sizeトランス層内のフィードフォワード ネットワークの非表示サイズを設定します。 BERT および GPT の場合、これはデフォルトでトランスフォーマーの非表示サイズの 4 倍に設定されますが、T5 用に構成できます。
--encoder-seq-lengthと--decoder-seq-lengthエンコーダーとデコーダーのシーケンス長を個別に設定します。
他のすべての引数は、BERT および GPT 事前トレーニングの場合と同じままです。他のスクリプトについて上記で説明したのと同じ手順でこの例を実行します。
詳細については、 examples/t5/README.mdを参照してください。
pretrain_{bert,gpt,t5}_distributed.shスクリプトは、分散トレーニング用に PyTorch 分散ランチャーを使用します。そのため、環境変数を適切に設定することでマルチノード トレーニングを実現できます。これらの環境変数の詳細については、PyTorch の公式ドキュメントを参照してください。デフォルトでは、マルチノード トレーニングは nccl 分散バックエンドを使用します。分散トレーニングを採用するための追加要件は、追加の引数の単純なセットと、 torchrunエラスティック ランチャーでの PyTorch 分散モジュールの使用 ( python -m torch.distributed.runに相当) だけです。詳細については、 pretrain_{bert,gpt,t5}_distributed.shを参照してください。
データ並列処理とモデル並列処理という 2 種類の並列処理を使用します。データ並列処理の実装はmegatron/core/distributedにあり、 --overlap-grad-reduceコマンドライン オプションが使用される場合に、バックワード パスによる勾配低減のオーバーラップをサポートします。
次に、シンプルで効率的な 2 次元モデル並列アプローチを開発しました。最初の次元のテンソル モデルの並列処理 (単一の変換モジュールの複数の GPU への分割実行、論文のセクション 3 を参照) を使用するには、 --tensor-model-parallel-sizeフラグを追加して、実行する GPU の数を指定します。前述のように、分散ランチャーに渡される引数とともにモデルを分割します。 2 番目の次元であるシーケンス並列処理を使用するには、 --sequence-parallelを指定します。これには、同じ GPU 間で分割されるため、テンソル モデル並列処理も有効にする必要があります (詳細については、論文のセクション 4.2.2 を参照)。
パイプライン モデルの並列処理 (トランスフォーマー モジュールを各ステージのトランスフォーマー モジュールの数が等しいステージにシャーディングし、バッチをより小さなマイクロバッチに分割してパイプライン実行する、本稿のセクション 2.2 を参照) を使用するには、 --pipeline-model-parallel-size使用します。 --pipeline-model-parallel-sizeモデルを分割するステージ数を指定するフラグ (たとえば、24 のトランス層を持つモデルを 4 つのステージに分割すると、各ステージがそれぞれ 6 つのトランス層を取得することになります)。
これら 2 つの異なる形式のモデル並列処理の使用例が、 distributed_with_mp.shで終わるサンプル スクリプトにあります。
これらの小さな変更を除けば、分散トレーニングは単一 GPU でのトレーニングと同じです。
インターリーブ パイプライン スケジュール (詳細については、この論文のセクション 2.2.2 を参照) は、仮想ステージ内のトランスフォーマー層の数を制御する--num-layers-per-virtual-pipeline-stage引数を使用して有効にできます (デフォルト)非インターリーブ スケジュールでは、各 GPU はNUM_LAYERS / PIPELINE_MP_SIZEトランスフォーマー レイヤーを含む単一の仮想ステージを実行します。変圧器モデル内の層の総数は、この引数の値で割り切れる必要があります。さらに、このスケジュールを使用する場合、パイプライン内のマイクロバッチの数 ( GLOBAL_BATCH_SIZE / (DATA_PARALLEL_SIZE * MICRO_BATCH_SIZE)として計算) は、 PIPELINE_MP_SIZEで割り切れる必要があります (この条件はコード内のアサーションでチェックされます)。インターリーブ スケジュールは、2 ステージのパイプライン ( PIPELINE_MP_SIZE=2 ) ではサポートされません。
大規模なモデルをトレーニングするときに GPU メモリの使用量を削減するために、さまざまな形式のアクティベーション チェックポイントと再計算がサポートされています。従来の深層学習モデルの場合のように、バックプロップ中に使用されるすべてのアクティベーションがメモリに保存されるのではなく、モデル内の特定の「チェックポイント」でのアクティベーションのみがメモリに保持 (または保存) され、他のアクティベーションはメモリ上で再計算されます。バックプロップに必要な場合は -the-fly。この種のチェックポイント設定 (アクティブ化チェックポイント設定) は、他の場所で説明されているモデル パラメーターやオプティマイザーの状態のチェックポイント設定とは大きく異なることに注意してください。
再計算の粒度は、 selectiveとfullの 2 つのレベルがサポートされています。選択的再計算はデフォルトであり、ほとんどすべての場合に推奨されます。このモードは、必要なメモリ ストレージ スペースが少なく再計算にコストがかかるアクティベーションをメモリに保持し、より多くのメモリ ストレージ スペースを必要とするが再計算が比較的安価なアクティベーションを再計算します。詳細については、論文を参照してください。このモードでは、アクティベーションの保存に必要なメモリを最小限に抑えながら、パフォーマンスを最大化できることがわかります。選択的アクティベーションの再計算を有効にするには、 --recompute-activations使用するだけです。
メモリが非常に限られている場合、 full再計算では、入力のみをトランスフォーマー層、またはトランスフォーマー層のグループまたはブロックに保存し、他のすべてを再計算します。完全なアクティブ化の再計算を有効にするには、 --recompute-granularity full使用します。 fullアクティベーションの再計算を使用する場合、 uniformとblock 2 つのメソッドがあり、 --recompute-method引数を使用して選択されます。
uniformメソッドは、トランスフォーマ層を層のグループ (各グループのサイズ--recompute-num-layers ) に均等に分割し、各グループの入力アクティベーションをメモリに保存します。ベースライン グループ サイズは 1 で、この場合、各トランス層の入力アクティブ化が保存されます。 GPU メモリが不十分な場合、グループあたりのレイヤー数を増やすとメモリ使用量が減り、より大きなモデルをトレーニングできるようになります。たとえば、 --recompute-num-layersが 4 に設定されている場合、4 つのトランスフォーマー層の各グループの入力アクティベーションのみが保存されます。
blockメソッドは、パイプライン ステージごとに個々のトランスフォーマー層の特定の数 ( --recompute-num-layersで指定) の入力アクティベーションを再計算し、パイプライン ステージの残りの層の入力アクティベーションを保存します。 --recompute-num-layers減らすと、入力アクティベーションがより多くのトランスフォーマー層に保存されることになり、バックプロップで必要なアクティベーションの再計算が減り、メモリ使用量が増加しながらトレーニングのパフォーマンスが向上します。たとえば、パイプライン ステージごとに 8 つのレイヤーを再計算するために 5 つのレイヤーを指定すると、最初の 5 つのトランスフォーマー レイヤーのみの入力アクティベーションがバックプロップ ステップで再計算され、最後の 3 つのレイヤーの入力アクティベーションが保存されます。 --recompute-num-layers必要なメモリ ストレージ スペースの量が使用可能なメモリに収まる程度になるまで段階的に増やすことができ、これによりメモリを最大限に活用し、パフォーマンスを最大化することができます。
使用法: --use-distributed-optimizer 。すべてのモデルとデータ型に互換性があります。
分散オプティマイザはメモリ節約手法であり、オプティマイザの状態がデータ並列ランク全体に均等に分散されます (データ並列ランク全体でオプティマイザの状態をレプリケートする従来の方法とは対照的)。 「ZeRO: 兆パラメータ モデルのトレーニングに向けたメモリの最適化」で説明されているように、私たちの実装では、モデルの状態と重複しないすべてのオプティマイザの状態が分散されます。たとえば、fp16 モデル パラメータを使用する場合、分散オプティマイザは、DP ランク全体に分散される fp32 メイン パラメータと grad の独自のコピーを維持します。ただし、bf16 モデル パラメータを使用する場合、分散オプティマイザの fp32 メイン grad はモデルの fp32 grad と同じであるため、この場合の grad は分散されません (ただし、fp32 メイン パラメータは bf16 とは別個であるため、依然として分散されます)。モデルパラメータ)。
理論的なメモリ節約量は、モデルの param dtype と grad dtype の組み合わせによって異なります。私たちの実装では、パラメーターあたりの理論上のバイト数は次のとおりです (「d」はデータの並列サイズです)。
| 非分散最適化 | 分散最適化 | |
|---|---|---|
| fp16 パラメータ、fp16 卒業生 | 20 | 4 + 16/日 |
| bf16パラメータ、fp32卒業生 | 18 | 6 + 12/日 |
| fp32 パラメータ、fp32 卒業生 | 16 | 8 + 8/日 |
通常のデータ並列処理と同様に、 --overlap-grad-reduceフラグを使用すると、勾配リダクション (この場合、reduce-scatter) とバックワード パスのオーバーラップを容易にすることができます。さらに、 --overlap-param-gather使用して、パラメーター all-gather のオーバーラップをフォワード パスとオーバーラップできます。
使用法: --use-flash-attn 。最大 128 の注意ヘッド寸法をサポートします。
FlashAttention は、正確なアテンションを計算するための高速でメモリ効率の高いアルゴリズムです。モデルのトレーニングが高速化され、メモリ要件が軽減されます。
FlashAttentionをインストールするには:
pip install flash-attnexamples/gpt3/train_gpt3_175b_distributed.shでは、1024 GPU で 1750 億のパラメーターを使用して GPT-3 をトレーニングするように Megatron を構成する方法の例が提供されています。このスクリプトは pyxis プラグインを使用した slurm 用に設計されていますが、他のスケジューラーにも簡単に採用できます。 8 方向のテンソル並列処理と 16 方向のパイプライン並列処理が使用されます。オプションglobal-batch-size 1536およびrampup-batch-size 16 16 5859375を使用すると、トレーニングはグローバル バッチ サイズ 16 から開始され、増分ステップ 16 で 5,859,375 サンプルにわたってグローバル バッチ サイズを 1536 まで線形に増加します。トレーニング データセットは次のいずれかです。単一セット、または一連の重みと組み合わせた複数のデータセット。
1024 個の A100 GPU で 1536 の完全なグローバル バッチ サイズを使用すると、各反復に約 32 秒かかり、結果として GPU あたり 138 テラ FLOP となり、これは理論上のピーク FLOP の 44% に相当します。
Retro (Borgeaud et al., 2022) は、検索拡張で事前トレーニングされた自己回帰デコーダー専用言語モデル (LM) です。 Retro は、数兆のトークンから取得することにより、大規模な事前トレーニングをゼロからサポートする実用的なスケーラビリティを備えています。検索を伴う事前トレーニングは、事実の知識をネットワークのパラメーター内に暗黙的に保存する場合と比較して、より効率的な事実の知識の保存メカニズムを提供するため、標準 GPT よりも低い混乱度を達成しながら、モデルのパラメーターを大幅に削減できます。 Retro は、LM を再度トレーニングすることなく検索データベースを更新することで、LM に保存された知識を更新する柔軟性も提供します (Wang et al., 2023a)。
InstructRetro (Wang et al.、2023b) は、Retro のサイズを 48B までさらにスケールアップし、検索で事前トレーニングされた最大の LLM を特徴としています (2023 年 12 月現在)。得られた基礎モデルである Retro 48B は、複雑さの点で GPT の対応物を大幅に上回っています。 Retro での命令チューニングにより、InstructRetro は、ゼロショット設定での下流タスクで命令チューニング GPT に比べて大幅な改善を示します。具体的には、InstructRetro の平均改善率は、8 つの短い形式の QA タスクでは GPT と比べて 7% 向上し、4 つの困難な長い形式の QA タスクでは GPT より 10% 向上しました。また、InstructRetro アーキテクチャからエンコーダをアブレートし、InstructRetro デコーダ バックボーンを GPT として直接使用しながら、同等の結果を達成できることもわかりました。
このリポジトリでは、Retro と InstructRetro を実装するためのエンドツーエンドの再現ガイドを提供します。
詳細な概要については、tools/retro/README.md を参照してください。
詳細については、examples/mamba を参照してください。
さまざまなゼロショットおよび微調整されたダウンストリーム タスクを処理するために、以下のスクリプトで詳しく説明されているいくつかのコマンド ライン引数が提供されています。ただし、必要に応じて、他のコーパスの事前トレーニング済みチェックポイントからモデルを微調整することもできます。これを行うには、 --finetuneフラグを追加し、元のトレーニング スクリプト内の入力ファイルとトレーニング パラメーターを調整するだけです。反復カウントはゼロにリセットされ、オプティマイザと内部状態が再初期化されます。微調整が何らかの理由で中断された場合は、続行する前に必ず--finetuneフラグを削除してください。そうしないと、トレーニングが最初から再開されます。
評価に必要なメモリはトレーニングよりも大幅に少ないため、ダウンストリーム タスクでより少ない GPU で使用できるように、並行してトレーニングされたモデルをマージすると有利な場合があります。次のスクリプトはこれを実現します。この例では、4 方向テンソルおよび 4 方向パイプライン モデル並列処理を使用して GPT モデルを読み取り、2 方向テンソルおよび 2 方向パイプライン モデル並列処理を使用してモデルを書き込みます。
Python ツール/チェックポイント/convert.py
--モデルタイプ GPT
--load-dir チェックポイント/gpt3_tp4_pp4
--save-dir チェックポイント/gpt3_tp2_pp2
--ターゲットテンソル並列サイズ 2
--ターゲットパイプライン並列サイズ 2
以下では、GPT モデルと BERT モデルの両方について、いくつかのダウンストリーム タスクについて説明します。これらは、トレーニング スクリプトで使用されたものと同じ変更を加えて、分散モードおよびモデル並列モードで実行できます。
tools/run_text_generation_server.pyには、テキスト生成に使用する単純な REST サーバーが含まれています。適切な事前トレーニング済みチェックポイントを指定して、事前トレーニング ジョブを開始するのと同じように実行します。いくつかのオプションのパラメータもあります: temperature 、 top-k 、およびtop-p 。詳細については、 --helpまたはソース ファイルを参照してください。サーバーの実行方法の例については、examples/inference/run_text_generation_server_345M.sh を参照してください。
サーバーが実行されたら、 tools/text_generation_cli.py使用してサーバーをクエリできます。これには、サーバーが実行されているホストを 1 つの引数として受け取ります。
tools/text_generation_cli.py ローカルホスト:5000
CURL またはその他のツールを使用して、サーバーに直接クエリを実行することもできます。
curl 'http://localhost:5000/api' -X 'PUT' -H 'Content-Type: application/json; charset=UTF-8' -d '{"プロンプト":["Hello world"], "生成するトークン":1}'
その他の API オプションについては、megatron/inference/text_generation_server.py を参照してください。
言語モデルの生成力を活用して言語モデルを無毒化する例がexamples/academic_paper_scripts/detxoify_lm/に含まれています。
ドメイン適応トレーニングを実行し、自己生成コーパスを使用して LM を解毒する方法に関するステップバイステップのチュートリアルについては、examples/academic_paper_scripts/detxoify_lm/README.md を参照してください。
WikiText の複雑さの評価と LAMBADA Cloze の精度に関する GPT 評価のサンプル スクリプトが含まれています。
以前の研究と均等に比較するために、単語レベルの WikiText-103 テスト データセットでパープレキシティを評価し、サブワード トークナイザーを使用する際のトークンの変化を考慮してパープレキシティを適切に計算します。
次のコマンドを使用して、345M パラメータ モデルで WikiText-103 評価を実行します。
タスク="WIKITEXT103"
VALID_DATA=<ウィキテキストのパス>.txt
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=チェックポイント/gpt2_345m
COMMON_TASK_ARGS="--層数 24
--隠しサイズ 1024
--num-attention-heads 16
--seq-length 1024
--max-position-embeddings 1024
--fp16
--vocab-file $VOCAB_FILE"
Python タスク/main.py
--タスク $TASK
$COMMON_TASK_ARGS
--有効なデータ $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--マージファイル $MERGE_FILE
--load $CHECKPOINT_PATH
--マイクロバッチサイズ 8
--ログ間隔 10
--no-load-optim
--no-load-rng
LAMBADA クローズの精度 (前のトークンから最後のトークンを予測する精度) を計算するには、LAMBADA データセットの非トークン化処理済みバージョンを利用します。
次のコマンドを使用して、345M パラメーター モデルで LAMBADA 評価を実行します。単語全体の一致を要求するには、 --strict-lambadaフラグを使用する必要があることに注意してください。 lambadaがファイル パスの一部であることを確認してください。
タスク=「ランバダ」
VALID_DATA=<ランバダパス>.json
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=チェックポイント/gpt2_345m
COMMON_TASK_ARGS=<上記の WikiText の複雑さの評価と同じ>
Python タスク/main.py
--タスク $TASK
$COMMON_TASK_ARGS
--有効なデータ $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--strict-lambada
--マージファイル $MERGE_FILE
--load $CHECKPOINT_PATH
--マイクロバッチサイズ 8
--ログ間隔 10
--no-load-optim
--no-load-rng
さらなるコマンドライン引数はソースファイルmain.pyに記述されています。
次のスクリプトは、RACE データセットでの評価のために BERT モデルを微調整します。 TRAIN_DATAディレクトリとVALID_DATAディレクトリには、RACE データセットが個別の.txtファイルとして含まれています。 RACE の場合、バッチ サイズは評価する RACE クエリの数であることに注意してください。各 RACE クエリには 4 つのサンプルがあるため、モデルを通過する有効なバッチ サイズは、コマンド ラインで指定したバッチ サイズの 4 倍になります。
TRAIN_DATA="データ/RACE/トレイン/ミドル"
VALID_DATA="データ/RACE/dev/middle
データ/RACE/dev/高"
VOCAB_FILE=バート-vocab.txt
PRETRAINED_CHECKPOINT=チェックポイント/bert_345m
CHECKPOINT_PATH=チェックポイント/bert_345m_race
COMMON_TASK_ARGS="--層数 24
--隠しサイズ 1024
--num-attention-heads 16
--seq-length 512
--max-position-embeddings 512
--fp16
--vocab-file $VOCAB_FILE"
COMMON_TASK_ARGS_EXT="--train-data $TRAIN_DATA
--有効なデータ $VALID_DATA
--pretrained-checkpoint $PRETRAINED_CHECKPOINT
--保存間隔 10000
--$CHECKPOINT_PATH を保存
--ログ間隔 100
--eval-interval 1000
--eval-iters 10
--weight-decay 1.0e-1"
Python タスク/main.py
--タスクレース
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--tokenizer-type BertWordPieceLowerCase
--エポック3
--マイクロバッチサイズ 4
--lr 1.0e-5
--lr-ウォームアップ-フラクション 0.06
次のスクリプトは、MultiNLI 文ペア コーパスを使用して評価するために BERT モデルを微調整します。マッチング タスクは非常に似ているため、スクリプトをすぐに調整して Quora 質問ペア (QQP) データセットでも動作するようにすることができます。
train_data = "data/glue_data/mnli/train.tsv"
valid_data = "data/glue_data/mnli/dev_matched.tsv
data/glue_data/mnli/dev_mismatched.tsv "
pretrained_checkpoint = checkpoints/bert_345m
vocab_file = bert-vocab.txt
checkpoint_path = checkpoints/bert_345m_mnli
common_task_args = <上記のレース評価のものと同じ>
common_task_args_ext = <上記のレース評価のものと同じ>
python tasks/main.py
-Task Mnli
$ common_task_args
$ common_task_args_ext
- トコーネザータイプのbertwordpiecelowercase
-epochs5
- マイクロバッチサイズ8
-lr 5.0e-5
-lr-warmup-fraction 0.065
モデルのLlama-2ファミリーは、幅広いベンチマークで強力な結果を達成した、前処理された(チャット用)モデルのオープンソースセットです。リリース時に、Llama-2モデルはオープンソースモデルの最良の結果の中で達成され、クローズドソースGPT-3.5モデルと競合しました(https://arxiv.org/pdf/2307.09288.pdfを参照)。
Llama-2チェックポイントは、推論と微調整のためにメガトロンにロードできます。こちらのドキュメントを参照してください。
Megatron-Core(MCORE) GPTModelファミリーは、Tensort-llmを介した高度な量子化アルゴリズムと高性能推論をサポートしています。
llama2およびnemotron3の例のMegatronモデルの最適化と展開を参照してください。
GPTまたはBERTトレーニングのデータセットはホストしていませんが、結果が再現されるようにコレクションを詳しく説明します。
Google Researchで指定されたWikipediaデータ抽出プロセスに従うことをお勧めします。「推奨される前処理は、最新のダンプをダウンロードし、wikiextractor.pyでテキストを抽出し、必要なクリーンアップを適用してプレーンテキストに変換することです。」
Wikiextractorを使用する場合は、 --json引数を使用することをお勧めします。Wikiextractorは、Wikipediaデータをloose JSON形式(1行ごとに1つのJSONオブジェクト)にダンプし、ファイルシステム上でより管理しやすく、コードベースで容易に消費できるようにすることをお勧めします。 NLTK句読点標準化を使用して、このJSONデータセットをさらに前処理することをお勧めします。 BERTトレーニングには、上記のように--split-sentencesフラグをpreprocess_data.pyに使用して、生成されたインデックスに文章を含めます。 GPTトレーニングにWikipediaデータを使用したい場合は、NLTK/SPACY/FTFYでクリーニングする必要がありますが、 --split-sentencesフラグを使用しないでください。
jcpetersonとeukaryote31の作業から公開されているOpenWeBtextライブラリを利用して、URLをダウンロードします。次に、OpenWeBtextディレクトリに記載されている手順に従って、ダウンロードされたすべてのコンテンツをフィルタリング、クリーニング、および強化します。 2018年10月までのコンテンツに対応するReddit URLの場合、約37GBのコンテンツに到着しました。
メガトロンのトレーニングは、ビットごとに再現可能です。このモードを有効にするには--deterministic-mode使用します。つまり、同じトレーニング構成が同じHWとSW環境で2回実行されることを意味し、同一のモデルチェックポイント、損失、精度メトリック値を生成するはずです(反復時間メトリックは異なる場合があります)。
現在、ほぼ同じトレーニングの実行を生成しながら再現性を破る3つの既知のメガトロンの最適化があります。
NCCL_ALGOで指定)が重要です。 ^NVLS TreeテストCollnetDirect Ring CollnetChain 。このコードは、 ^NVLSの使用を認めており、NCCLが非NVLSアルゴリズムの選択を可能にします。その選択は安定しているようです。--use-flash-attn 。NVTE_ALLOW_NONDETERMINISTIC_ALGO=0を設定する必要があります。さらに、detinisimは、23.12よりも新しいNGC Pytorch容器でのみ検証されています。他の状況下でメガトロンのトレーニングで非決定的主義を観察した場合は、問題を開いてください。
以下は、メガトロンを直接使用したプロジェクトの一部です。


