tabled
1.0.0
Tabled は、テーブルを検出して抽出するための小さなライブラリです。 surya を使用して PDF 内のすべての表を検索し、行/列を識別し、セルをマークダウン、csv、または html にフォーマットします。
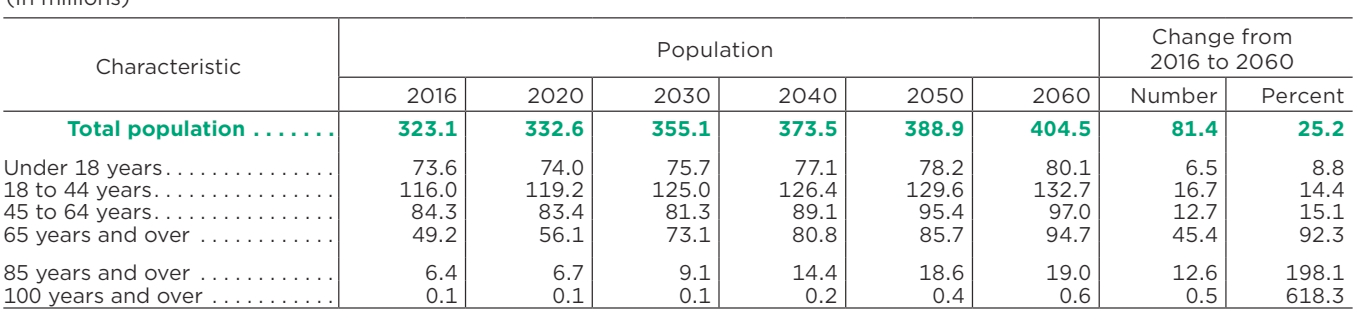
| 特性 | 人口 | 2016年から2060年への変化 | ||||||
|---|---|---|---|---|---|---|---|---|
| 2016年 | 2020年 | 2030年 | 2040年 | 2050年 | 2060年 | 番号 | パーセント | |
| 総人口 | 323.1 | 332.6 | 355.1 | 373.5 | 388.9 | 404.5 | 81.4 | 25.2 |
| 18歳未満 | 73.6 | 74.0 | 75.7 | 77.1 | 78.2 | 80.1 | 6.5 | 8.8 |
| 18~44歳 | 116.0 | 119.2 | 125.0 | 126.4 | 129.6 | 132.7 | 16.7 | 14.4 |
| 45~64歳 | 84.3 | 83.4 | 81.3 | 89.1 | 95.4 | 97.0 | 12.7 | 15.1 |
| 65歳以上 | 49.2 | 56.1 | 73.1 | 80.8 | 85.7 | 94.7 | 45.4 | 92.3 |
| 85歳以上 | 6.4 | 6.7 | 9.1 | 14.4 | 18.6 | 19.0 | 12.6 | 198.1 |
| 100年以上 | 0.1 | 0.1 | 0.1 | 0.2 | 0.4 | 0.6 | 0.5 | 618.3 |
Discordでは今後の開発について話し合う場です。
ここで利用可能なテーブル用のホストされた API があります。
PDF、画像、Word ドキュメント、PowerPoint で動作します
遅延のスパイクがない、安定した速度
高い信頼性と稼働時間
開発/トレーニング費用に資金を提供しつつ、テーブルをできるだけ広くアクセスできるようにしたいと考えています。研究や個人での使用はいつでも問題ありませんが、商用使用にはいくつかの制限があります。
モデルの重み付けはcc-by-nc-sa-4.0ライセンスされていますが、直近 12 か月の総収益が 500 万ドル未満、かつ生涯の VC/エンジェル資金が 500 万ドル未満の組織については、このライセンスを免除します。上げた。また、Datalab API と競合してはいけません。 GPL ライセンス要件を削除 (デュアル ライセンス) したい場合、および/または収益制限を超えてウェイトを商業的に使用したい場合は、ここでオプションを確認してください。
Python 3.10 以降と PyTorch が必要です。 Mac または GPU マシンを使用していない場合は、最初に CPU バージョンの torch をインストールする必要がある場合があります。 詳細については、こちらを参照してください。
以下を使用してインストールします。
pip インストール tabled-pdf
インストール後:
tabled/settings.pyの設定を調べます。 環境変数を使用して任意の設定を上書きできます。
トーチ デバイスは自動的に検出されますが、これを無効にすることもできます。 たとえば、 TORCH_DEVICE=cuda 。
モデルの重みは、初めて tabled を実行するときに自動的にダウンロードされます。
テーブル化されたDATA_PATH
DATA_PATHは、画像、PDF、または画像/PDF のフォルダーを指定できます。
--format各テーブルの出力形式 ( markdown 、 html 、またはcsv ) を指定します。
--save_json追加の行と列の情報を json ファイルに保存します
--save_debug_images検出された行と列を示す画像を保存します。
--skip_detection 、渡す画像がすべてトリミングされたテーブルであり、テーブル検出が必要ないことを意味します。
--detect_cell_boxesデフォルトでは、tabled は pdf からセル情報を取得しようとします。 代わりに検出モデルによってセルを検出したい場合は、これを指定します (通常、これは不適切なテキストが埋め込まれた PDF でのみ必要です)。
--save_images検出された行/列およびセルの画像を保存することを指定します。
スクリプトを実行すると、出力ディレクトリには、入力ファイル名と同じベース名のフォルダーが含まれます。 これらのフォルダー内には、ソース ドキュメント内の各テーブルのマークダウン ファイルが含まれます。 オプションでテーブルの画像も表示されます。
出力ディレクトリのルートには、 results.jsonファイルも存在します。ファイルには、拡張子なしの入力ファイル名をキーとする json 辞書が含まれます。 各値は、ドキュメント内のテーブルごとに 1 つずつ、辞書のリストになります。 各テーブル ディクショナリには次のものが含まれます。
cells - 各表セルの検出されたテキストと境界ボックス。
bbox - テーブル bbox 内のセルの bbox
text - セルのテキスト
row_ids - セルが属する行の ID
col_ids - セルが属する列の ID
order - 割り当てられた行/列セル内のこのセルの順序。 (行、列、順序で並べ替えます)
rows - 検出された行の bbox
bbox - (x1, x2, y1, y2) 形式の行の bbox
row_id - 行の一意の ID
cols - 検出された列の bbox
bbox - (x1, x2, y1, y2) 形式の列の bbox
col_id - 列の一意の ID
image_bbox - (x1, y1, x2, y2) 形式の画像の bbox。 (x1, y1) は左上隅、(x2, y2) は右下隅です。 テーブル bbox はこれに関連しています。
bbox - 画像 bbox 内のテーブルの境界ボックス。
pnum - 文書内のページ番号
tnum - ページ上のテーブルインデックス
画像や PDF ファイルをインタラクティブにテーブル化できるストリームリット アプリを組み込みました。 次のように実行します。
pip インストール streamlit tabled_gui
from tabled.extract import extract_tablesfrom tabled.fileinput importload_pdfs_imagesfrom tabled.inference.models importload_detection_models、load_recognition_modelsdet_models、rec_models =load_detection_models()、load_recognition_models()images、highres_images、names、text_lines = load_pdfs_images(IN_PATH)page_results = extract_tables(images、highres_images、text_lines、det_models、rec_models)
| 平均スコア | テーブルあたりの時間 | 合計テーブル |
|---|---|---|
| 0.847 | 0.029 | 688 |
ヒューリスティックに解析してレンダリングできる単純なレイアウトに制約されるか、間違いを犯す LLM を使用する必要があるため、テーブルの適切なグラウンド トゥルース データを取得するのは困難です。 私は、疑似グラウンドトゥルースとして GPT-4 テーブル予測を使用することにしました。
GPT-4 と比較した場合、Tabled は.847アライメント スコアを獲得しており、これはテーブルの行/セル内のテキスト間のアライメントを示します。 位置ずれの一部は、GPT-4 の間違い、または GPT-4 がテーブルの境界とみなしたものに小さな矛盾があることが原因です。 一般に、抽出品質は非常に高いです。
10 GB の VRAM 使用量とバッチ サイズ64の A10G で実行すると、テーブルごとに.029秒かかります。
以下を使用してベンチマークを実行します。
Pythonベンチマーク/benchmark.py out.json
ベンチマーク データセットとテーブル解析についてのディスカッションについては、Peter Jansen に感謝します。
推論コードとモデルのホスティングのための Huggingface
トレーニング/推論用の PyTorch


