Stable Diffusion は、Stability AI および Runway とのコラボレーションのおかげで可能になり、以前の作業に基づいて構築されています。
潜在拡散モデルによる高解像度画像合成
ロビン ロンバック*、アンドレアス ブラットマン*、ドミニク ロレンツ、パトリック エッサー、ビョルン オマー
CVPR '22 オーラル |ギットハブ | arXiv |プロジェクトページ
 安定拡散は、潜在的なテキストから画像への拡散モデルです。 Stability AI からの寛大なコンピューティングの寄付と LAION からのサポートのおかげで、LAION-5B データベースのサブセットからの 512x512 画像で潜在拡散モデルをトレーニングすることができました。 Google の Imagen と同様に、このモデルはフリーズされた CLIP ViT-L/14 テキスト エンコーダーを使用して、テキスト プロンプトでモデルを条件付けします。 860M UNet と 123M テキスト エンコーダを備えたこのモデルは比較的軽量で、少なくとも 10GB VRAM を備えた GPU で実行されます。以下のこのセクションとモデル カードを参照してください。
安定拡散は、潜在的なテキストから画像への拡散モデルです。 Stability AI からの寛大なコンピューティングの寄付と LAION からのサポートのおかげで、LAION-5B データベースのサブセットからの 512x512 画像で潜在拡散モデルをトレーニングすることができました。 Google の Imagen と同様に、このモデルはフリーズされた CLIP ViT-L/14 テキスト エンコーダーを使用して、テキスト プロンプトでモデルを条件付けします。 860M UNet と 123M テキスト エンコーダを備えたこのモデルは比較的軽量で、少なくとも 10GB VRAM を備えた GPU で実行されます。以下のこのセクションとモデル カードを参照してください。
ldmという名前の適切な conda 環境は、次のように作成してアクティブ化できます。
conda env create -f environment.yaml
conda activate ldm
次のコマンドを実行して、既存の潜在拡散環境を更新することもできます。
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
Stable Diffusion v1 は、拡散モデルに 860M UNet および CLIP ViT-L/14 テキスト エンコーダを備えたダウンサンプリング係数 8 オートエンコーダを使用するモデル アーキテクチャの特定の構成を指します。モデルは 256x256 画像で事前トレーニングされ、その後 512x512 画像で微調整されました。
注: Stable Diffusion v1 は、一般的なテキストから画像への拡散モデルであるため、トレーニング データに存在するバイアスや (誤った) 概念を反映しています。トレーニング手順とデータ、およびモデルの使用目的の詳細については、対応するモデル カードに記載されています。
ウェイトは、Hugging Face の CompVis 組織を通じてライセンスに基づいて入手できます。このライセンスには、モデル カードに記載されている誤用や危害を防ぐための特定の使用ベースの制限が含まれていますが、それ以外は寛容なままです。商用利用はライセンス条項に基づいて許可されていますが、提供されたウェイトを追加の安全メカニズムや考慮事項なしでサービスまたは製品に使用することはお勧めしません。ウェイトには既知の制限とバイアスがあり、安全かつ倫理的な展開に関する研究があるためです。一般的なテキストから画像へのモデルは継続的な取り組みです。重みは研究成果物であるため、そのように扱う必要があります。
CreativeML OpenRAIL M ライセンスは Open RAIL M ライセンスであり、BigScience と RAIL Initiative が責任ある AI ライセンスの分野で共同で行っている研究成果を基にしています。当社のライセンスのベースとなっている BLOOM Open RAIL ライセンスに関する記事も参照してください。
現在、次のチェックポイントが提供されています。
sd-v1-1.ckpt : laion2B-en の解像度256x256で 237k ステップ。 laion-high-resolution の解像度512x512で 194k ステップ (解像度>= 1024x1024の LAION-5B からの 170M の例)。sd-v1-2.ckpt : sd-v1-1.ckptから再開。 laion-aesthetics v2 5+ の解像度512x512で 515k ステップ (推定美学スコア> 5.0を持つ laion2B-en のサブセット、さらに元のサイズ>= 512x512および推定透かし確率< 0.5の画像にフィルタリングされています。透かし推定)は LAION-5B メタデータからのものであり、美的スコアはLAION-美学予測器 V2)。sd-v1-3.ckpt : sd-v1-2.ckptから再開。 「laion-aesthetics v2 5+」では解像度512x512で 195k ステップが実行され、分類子を使用しないガイダンス サンプリングを改善するためにテキストコンディショニングが 10% 削減されました。sd-v1-4.ckpt : sd-v1-2.ckptから再開。 「laion-aesthetics v2 5+」では解像度512x512で 225k ステップ、分類子なしのガイダンス サンプリングを改善するためにテキストコンディショニングが 10% 削減されました。さまざまな分類子を使用しないガイダンス スケール (1.5、2.0、3.0、4.0、5.0、6.0、7.0、8.0) および 50 PLMS サンプリング ステップでの評価では、チェックポイントの相対的な改善が示されています。 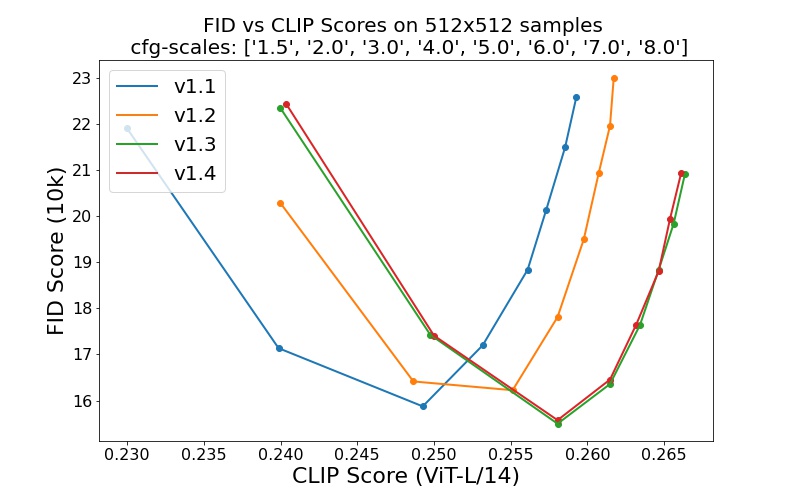


安定拡散は、CLIP ViT-L/14 テキスト エンコーダの (プールされていない) テキスト埋め込みを条件とした潜在拡散モデルです。サンプリング用のリファレンス スクリプトを提供していますが、ディフューザーの統合も存在しており、より活発なコミュニティ開発が期待されます。
リファレンス サンプリング スクリプトを提供します。
stable-diffusion-v1-*-originalウェイトを取得したら、それらをリンクします
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
そしてサンプルを使って
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
デフォルトでは、これは--scale 7.5のガイダンス スケール (Katherine Crowson による PLMS サンプラーの実装) を使用し、サイズ 512x512 (トレーニングされた) の画像を 50 ステップでレンダリングします。サポートされているすべての引数を以下に示します ( python scripts/txt2img.py --helpと入力します)。
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
注: すべての v1 バージョンの推論構成は、EMA のみのチェックポイントで使用するように設計されています。このため、構成でuse_ema=Falseが設定されます。それ以外の場合、コードは非 EMA 重みから EMA 重みに切り替えようとします。 EMA の効果と EMA なしの効果を調べたい場合は、両方のタイプのウェイトを含む「完全な」チェックポイントが提供されます。これらの場合、 use_ema=False非 EMA 重みをロードして使用します。
Stable Diffusion をダウンロードしてサンプルする簡単な方法は、ディフューザー ライブラリを使用することです。
# make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
use_auth_token = True
). to ( "cuda" )
prompt = "a photo of an astronaut riding a horse on mars"
with autocast ( "cuda" ):
image = pipe ( prompt )[ "sample" ][ 0 ]
image . save ( "astronaut_rides_horse.png" )SDEdit によって最初に提案された拡散ノイズ除去メカニズムを使用することにより、このモデルは、テキストガイドによる画像間の変換やアップスケーリングなどのさまざまなタスクに使用できます。 txt2img サンプリング スクリプトと同様に、Stable Diffusion による画像修正を実行するスクリプトを提供します。
Pintaで作成したラフスケッチを詳細なアートワークに変換する例を説明します。
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
ここで、強度は 0.0 ~ 1.0 の値で、入力画像に追加されるノイズの量を制御します。値が 1.0 に近づくと、多くのバリエーションが可能になりますが、入力と意味的に一貫性のない画像も生成されます。次の例を参照してください。
入力

出力


この手順は、たとえば、ベース モデルからサンプルをアップスケールする場合にも使用できます。
拡散モデルのコードベースは、OpenAI の ADM コードベースと https://github.com/lucidrains/denoising-diffusion-pytorch に大きく基づいて構築されています。オープンソース化していただきありがとうございます!
トランスフォーマー エンコーダーの実装は、lucidrains による x-transformers からのものです。
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


