ACM MM'18 最優秀学生論文賞
シンガポール国立大学 (NUS) ラーニング アンド ビジョン (LV) グループのマルチヒューマン解析プロジェクトは、群衆シーンにおける人間のきめ細かい視覚的理解の最前線を開拓するために提案されています。
マルチヒューマン解析は、物体の位置 (境界ボックス) の大まかなレベルの予測のみを提供する物体検出など、従来の明確に定義された物体認識タスクとは大きく異なります。インスタンス セグメンテーション。体の部位やファッション カテゴリに関する詳細な情報は含まず、インスタンス レベルのマスクのみを予測します。人間による解析。異なるアイデンティティを区別せずにカテゴリレベルのピクセル単位の予測を実行します。
現実世界のシナリオでは、相互作用のある複数の人物の設定がより現実的であり、通常のものです。したがって、各個人のきめ細かい意味情報と、人々のグループ全体の関係と相互作用の両方を考慮するためのタスク、対応するデータセット、およびベースライン手法が強く望まれています。
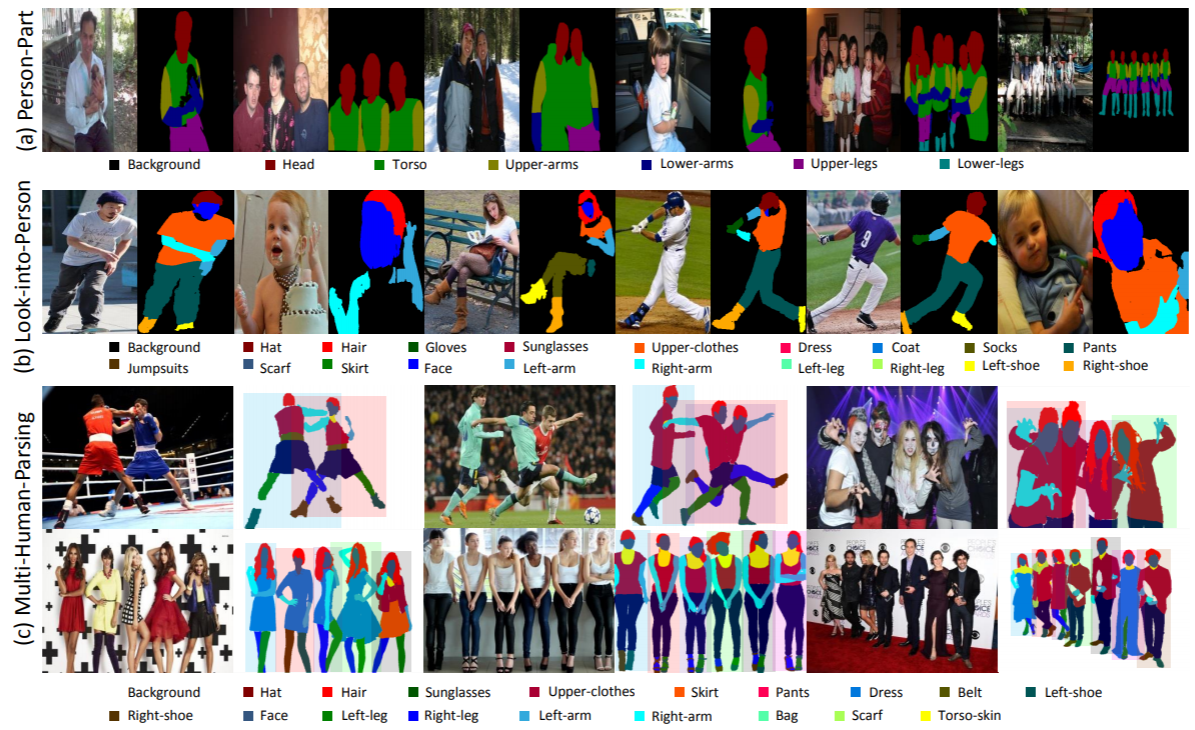
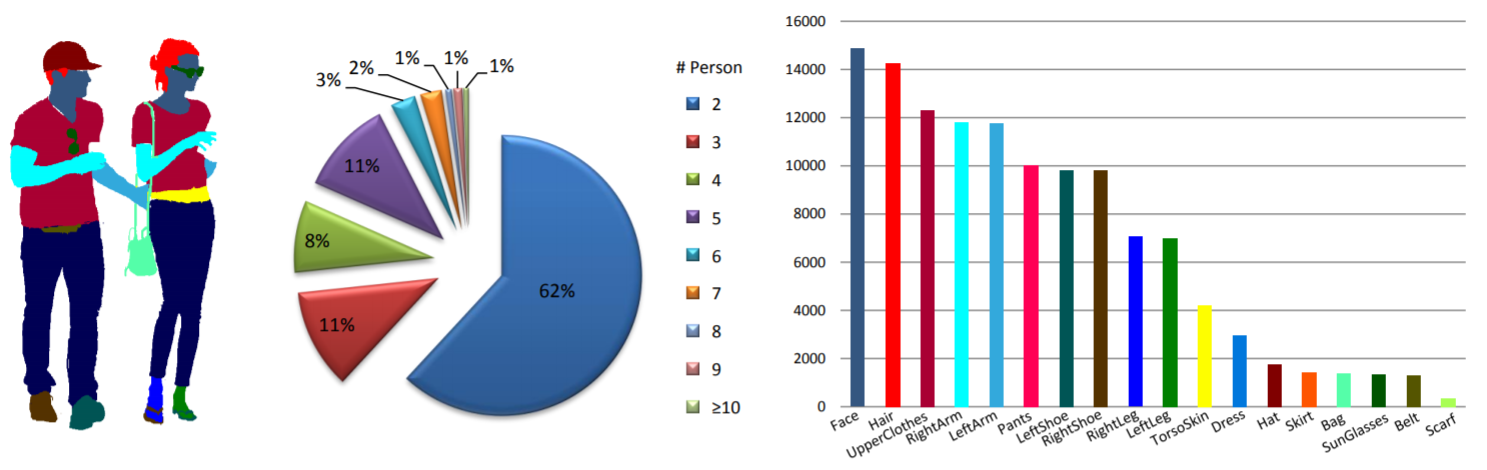
統計: MHP v1.0 データセットには 4,980 個の画像が含まれており、それぞれに少なくとも 2 人 (平均は 3 人) の人物が含まれています。 980 個の画像とそれに対応する注釈をテスト セットとしてランダムに選択します。残りは 3,000 枚の画像のトレーニング セットと 1,000 枚の画像の検証セットを形成します。各インスタンスについて、「背景」カテゴリを除く 18 の意味カテゴリが定義され、注釈が付けられます。つまり、「帽子」、「髪」、「サングラス」、「上着」、「スカート」、「パンツ」、「ドレス」、「 「ベルト」、「左靴」、「右靴」、「顔」、「左脚」、「右脚」、「左腕」、「右腕」、「バッグ」、「スカーフ」、「胴皮」。各インスタンスには、対応するカテゴリが現在の画像に表示されるたびに、完全な注釈セットが含まれます。
微信ニュース。
ダウンロード: MHP v1.0 データセットは、Google ドライブおよび Baidu ドライブ (パスワード: cmtp) で入手できます。
詳細については、MHP v1.0 ペーパー (IJCV に提出) を参照してください。

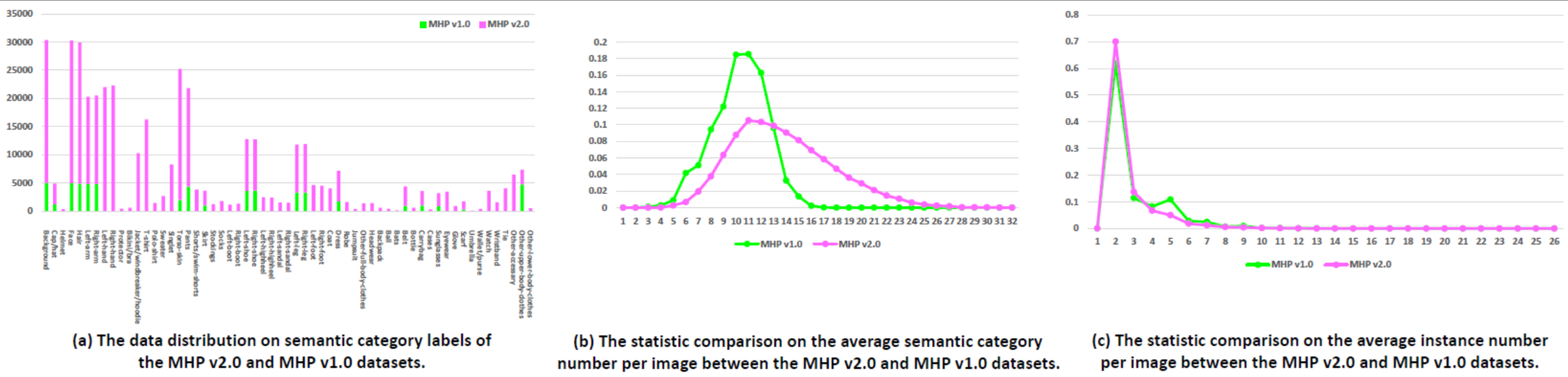

統計: MHP v2.0 データセットには 25,403 個の画像が含まれており、それぞれに少なくとも 2 人の人物が含まれています (平均は 3 人)。 5,000 枚の画像とそれに対応する注釈をテスト セットとしてランダムに選択します。残りは 15,403 枚の画像のトレーニング セットと 5,000 枚の画像の検証セットを形成します。各インスタンスについて、「背景」カテゴリを除く 58 の意味カテゴリが定義され、注釈が付けられます。つまり、「帽子/帽子」、「ヘルメット」、「顔」、「髪」、「左腕」、「右腕」、 「左手用」、「右手用」、「プロテクター」、「ビキニ/ブラ」、「ジャケット/ウインドブレーカー/パーカー」、「Tシャツ」、「ポロシャツ」、「セーター」、 「シングレット」、「トルソースキン」、「パンツ」、「ショートパンツ/スイムショーツ」、「スカート」、「ストッキング」、「ソックス」、「左ブーツ」、「右ブーツ」、「左靴」 "、"右-靴"、"左-ハイヒール"、"右-ハイヒール"、"左-サンダル"、"右-サンダル"、"左脚"、"右脚"、 「左足」、「右足」、「コート」、「ドレス」、「ローブ」、「ジャンプスーツ」、「その他全身服」、「帽子」、「バックパック」、「ボール」、 「コウモリ」、「ベルト」、「ボトル」、「キャリーバッグ」、「ケース」、「サングラス」、「アイウェア」、「グローブ」、「スカーフ」、「傘」、 「財布・財布」、「時計」、「リストバンド」、「ネクタイ」、「その他アクセサリー」、「その他上半身服」、「その他下半身服」各インスタンスには、対応するカテゴリが現在の画像に表示されるたびに、完全な注釈セットが含まれます。さらに、16箇所のキーポイント(「右肩」「右肘」「右手首」「左肩」「左肘」「左手首」「右手首」)を密集した2D人物ポーズを実現。股関節」、「右膝」、「右足首」、「左腰」、「左膝」、「左足首」、「頭」、「首」、「背骨」、各キーポイントには、それが可視-0/遮蔽-1/画像外-2であるかどうかを示すフラグがあり、複数の人間の姿勢推定研究を容易にするために、頭部とインスタンスの境界ボックスも提供されます。
ダウンロード: MHP v2.0 データセットは、Google ドライブおよび Baidu ドライブ (パスワード: uxrb) で入手できます。
詳細については、MHP v2.0 論文 (ACM MM'18 Best Student Paper) を参照してください。
マルチヒューマン解析: マルチヒューマン解析評価には 2 つの人間中心のメトリクスを使用します。これらは、MHP v1.0 論文で最初に報告されました。 2 つのメトリクスは、部分に基づく平均精度 (AP p ) (%) と正しく解析された意味部分の割合 (PCP) (%) です。評価コードについては、「Multi-Human-Parsing_MHP」リポジトリの「Evaluation」フォルダを参照してください。
複数人の姿勢推定: MPII に従い、mAP (%) 評価尺度を使用します。
私たちは、群集シーンにおける人間の視覚的理解に関する CVPR 2018 ワークショップ (VUHCS 2018) を開催しました。このワークショップは、NUS、CMU、SYSU の協力により行われます。 VUHCS 2017 に基づいて、私たちはこのワークショップを 5 つの競技トラックで強化することでさらに強化しました。1 人の人間の解析、複数人の人間の解析、1 人の姿勢推定、複数人の姿勢推定、および詳細なパフォーマンスです。粒度の高いマルチヒューマン解析。
結果の提出とリーダーボード。
微信ニュース。
次の論文を参照し、引用することを検討してください。
@article{zhao2018understanding,
title={Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing},
author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Zhou, Li and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1804.03287},
year={2018}
}
@article{li2017towards,
title={Multi-Human Parsing in the Wild},
author={Li, Jianshu and Zhao, Jian and Wei, Yunchao and Lang, Congyan and Li, Yidong and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1705.07206},
year={2017}
}


