Buqian Zheng(buqianz)、Yongkang Huang(yongkan1) 著
ポスター
Swift と Metal の深層学習フレームワークである Corgy を実装しました。 Corgy は macOS と iOS の両方のアプリケーションに組み込むことができ、訓練されたニューラル ネットワークを構築して簡単に評価するために使用できます。さまざまな GPU を搭載したさまざまなデバイスで 60 倍を超える高速化を達成しました。

Metal 2 フレームワークは、iPhone/iPad および Mac 上のグラフィックス プロセッシング ユニット (GPU) へのほぼ直接的なアクセスを提供する Apple が提供するインターフェイスです。 Metal 2 には、グラフィックスに加えて、さまざまな種類の Apple デバイスで実行できる必要な線形代数演算と信号処理関数に対する優れた並列化サポートを提供するライブラリが多数組み込まれています。これらのライブラリにより、他のフレームワークによって提供されたトレーニング済みモデルに基づいて、適切に実装された GPU アクセラレーションの深層学習モデルを iOS デバイス上に構築できるようになりました。 1
一般に、トレーニング済みニューラル ネットワークの推論段階は、特に非常に多くのレイヤーを持つモデルや、高解像度画像の処理に必要なシナリオに適用されるモデルの場合、非常に多くの計算を要します。パフォーマンスを最適化するために並列処理を適用するのに適した、膨大な量の行列計算 (畳み込み層など)が存在することに注目してください。
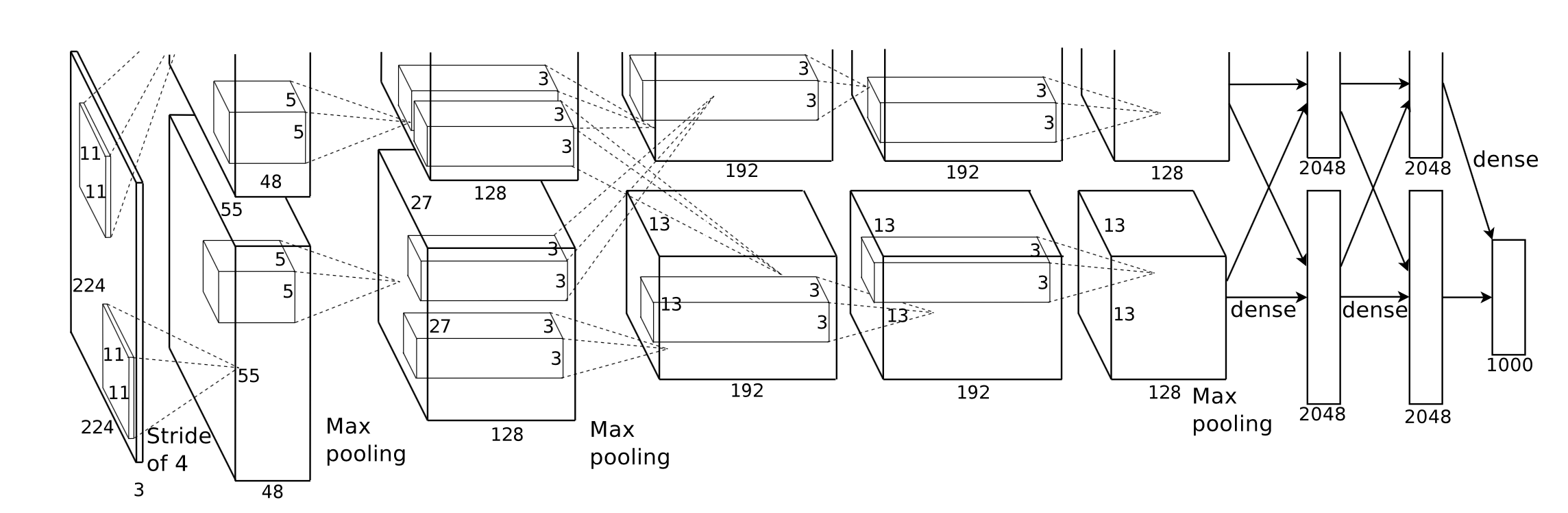
私たちが直面した最初の課題は、表現力豊かで、学習曲線が低く、ユーザーにとって使いやすい、アプリケーション プログラミング インターフェイスの優れた抽象化を設計することです。
開発プロセス全体を通じて、Swift が提供する関数型プログラミング メカニズムを活用して、必要なすべてのコンポーネントを作成するために必要なすべてのプロパティを備えながら、パブリック API を可能な限りシンプルに保つよう最善の努力を試みました。また、学習曲線をスムーズにするために、Metal が提供する不必要なハードウェア抽象化を意図的に隠しました。
さまざまなネットワークのトレーニング済みモデルはインターネット上で簡単に入手できますが、さまざまな種類のツールを適用する異なる実装によって引き起こされるモデル間の異種性により、ユニバーサル モデル インポーターを作成する作業が始まりました。
一部の計算は、その概念自体は簡単に理解できますが、それを抽象化して効果的な実装を作成する場合は、注意深く考える必要があります。代表的な例としてコンボリューションがあります。
畳み込み演算の固有のプロパティには良好な局所性がなく、通常の実装は理解するのが難しく、複雑な for ループを使用すると効果的ではありません。また、Metal 2 によって提供される抽象化を考慮し、データ表現とメモリ レイアウトを慎重に考慮して、ホストとデバイス間で必要な情報とデータ構造を共有する便利な方法を作成する必要があります。
開発段階では、両方のプラットフォームでパフォーマンスに妥協することなく、macOS と iOS で正常に実行されるコードの機能に慎重に取り組んでいます。私たちは、両方のプラットフォームでコンパイルおよび実行できるコード ライブラリを維持するために最善の努力を試みました。私たちは、異なるターゲット間で共有されるコードを最大化し、可能な限りコードを再利用するように注意しています。
ニューラル ネットワーク層の完全に実装されたコンポーネントは、コンポーネントを十分に使用可能にする適切な量のパラメータによるサポートを提供する必要があるため、コンポーネントの複雑さは実際には非常に印象的です。たとえば、畳み込み層はパディングや拡張ストライドなどを組み込んだパラメータをサポートする必要があり、適切なパフォーマンスを達成する並列化を行う際には、それらすべてを慎重に考慮する必要があります。回帰テストを行うためにいくつかの単純なネットワークを構築しました。テスト ケースは、すべての実装が正しく動作することを確認するために、他のフレームワーク (主に PyTorch と Keras) で作成されます。
Swift は 2010 年 7 月に初めて開発され、2014 年に公開およびオープンソース化されました。公開されてからほぼ 4 年が経ちますが、影響力のあるライブラリの欠如は依然として無視できない問題です。何らかの理由がこの状況を引き起こしました。Apple の支配的な役割と Swift の自然な高速反復がこの現象の理由である可能性があります。私たちにとって重要な一部のライブラリは、私たちのニーズを満たすほど強力または機能的ではないか、またはそれらを発明した個々の開発者によって十分に保守されていません。私たちは、要求に応えて適切に機能するテンソル クラスVariable実装するのにかなりの時間を費やしました。
また、ファイルおよび文字列処理関数の能力が非常に限られているということも、ユニバーサル モデル パーサーの開発を妨げるもう 1 つの理由です。
さらに、開発ツールとデバッグ ツールは基本的に Xcode に制限されていますが、私たちにとってより一般的な選択肢は他にもありますが、Xcode は依然として私たちの開発の事実上の標準ツールです。
モバイルデバイスのパフォーマンスチューニングに関して、Apple は SoC の詳細なハードウェア仕様を提供していません。マーケティング名はメディアで広く使用されており、特定のハードウェア機能と実装のパフォーマンスの微調整の正確な影響を推測するのは困難です。 。
私たちは Swift プログラミング言語、具体的にはこれまでのところ最新の Swift 4.2 を使用しています。 Metal 2 フレームワークと、Metal Performance Shader によって提供されるいくつかのライブラリ関数 (基本的に線形代数関数)。 Apple は 2017 年春に畳み込みニューラル ネットワークのサポートを組み込んだ CoreML SDK をリリースしましたが、ネットワーク層の並列実装の開発で貴重な経験を積み、優れた使いやすさとスムーズな学習曲線を備えた簡潔で直感的な API を提供するために、Corgy では CoreML SDK を使用していません。ユーザーが他のフレームワークからモデルを簡単に移行できるようにします。
対象となるマシンは、iMac、MacBook、iPhone、iPad など、macOS と iOS を実行しているすべてのデバイスです。具体的には、MPS 線形代数ライブラリをサポートするプラットフォームを搭載したデバイス (iOS 10.0 および macOS 10.13 以降)。つまり、iPhone は iPhone 5 以降に発売され、iPad は iPad (第 4 世代) 以降に発売され、iPod Touch (第 6 世代) 以降に発売されます。 iOS プラットフォームとしてサポートされています。 Mac 製品ラインはさらに幅広く、2009 年後半以降に製造された iMac、2010 年半ば以降に発売されたすべての MacBook シリーズ、および iMac Pro が含まれます。
Metal 2 の並列抽象化は CUDA とよく似ています。コンピュータ パスを GPU にディスパッチするとき、プログラマはまず各スレッドによって実行されるカーネル関数を記述し、次にグリッド内のスレッド グループ (別名 CUDA のブロック) の数を指定します。各スレッド グループ内のスレッドの数に応じて、Metal はこのグリッド上でカーネルを実行します。カーネルは Metal シェーディング言語という名前の C++14 方言で実装されます。各スレッド グループ内には、SIMD グループと呼ばれる小さな単位があります。これは、同じ SIMD 命令を共有するスレッドの束を意味します。しかし、私たちの実装では、これを考慮する必要はありません。
Metal は、GPU によってコミットおよび実行されるエンコードされたコマンドを保存する MTLCommandBuffer という名前の API を提供します。 GPU で実行するタスクを起動するたびに、プリコンパイルされたカーネル関数が GPU 命令にエンコードされ、メタル シェーディング パイプラインに埋め込まれて、MTLCommandBuffer に送信されます。デバイスに渡す必要がある計算パラメータを保存するために使用されるメタル バッファもこの段階で設定されます。次に、指定された数のスレッド グループとグループごとのスレッドを使用すると、コマンド バッファーによって処理されるコマンドが完全にエンコードされ、すべてデバイスにコミットされるように設定されます。 GPU はタスクをスケジュールし、実行終了後に作業を送信する CPU スレッドに通知します。
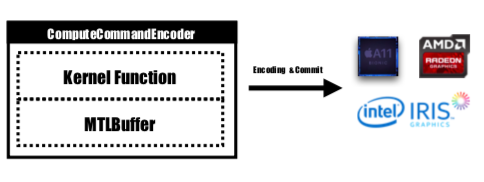
カーネル関数はMTLComputeCommandEncoderによってエンコードされ、サポートされているすべてのプラットフォームに対してタスクが作成されます。
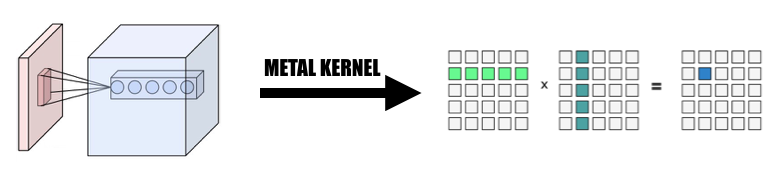
私たちの実装では、要素を GPU スレッドにマップする直感的な方法を広く利用しました。現在のレイヤーの出力テンソルの各要素を 1 つの GPU スレッドにマップします。各スレッドは出力の 1 つの要素を正確に計算して更新します。入力は次のようになります。読み取り専用なので、スレッド間の同期について心配する必要はありません。このマッピングでは、連続 ID を持つスレッドは、異なるメモリ位置から入力データを読み取る可能性がありますが、常に連続メモリ位置に書き込みます。したがって、SIMD グループがメモリに書き込むときに分散操作は行われません。
すべての実装の基礎としてテンソル クラスVariable設計し、実装の複雑さを軽減するために主な焦点ではない演算を深く掘り下げる追加のカーネルを作成する代わりに、線形代数演算を利用してVariableクラスにカプセル化しました。ネットワーク層の高速化に集中する時間を節約できます。
1. 畳み込みを巨大行列乗算に変更する
並列化された方法で入力からデータを収集し、入力変数と重みの両方の巨大な行列を形成します。再計算を避けるために、各畳み込み層の重みをキャッシュします。畳み込み層のパディングは、計算中の並列化変換中に生成され、その後、巨大行列に対して MPSMatrixMultiply を呼び出し、巨大行列からのデータを、作成した通常のテンソル クラスに変換して戻します。この方法はクラスのスライドで説明されています。
2. Variableクラスの設計と実装
変数クラスは、テンソル表現としての実装の基礎です。変数の MPSMatrixMultiplication をカプセル化しました (Unicode 乗算記号 (×) を中置演算子として定義して、エレガントに表現します :-))。
変数の基礎となるデータ構造は、データ型を指すUnsafemutableBufferPointerです。簡単にするために 32 ビット Float を選択しました。 Variableクラスは 2 つのデータ サイズを保持します。count count実際に格納された要素番号を保持します。actualCount actualCount 、 getpagesize()を使用して取得されるプラットフォームのページ サイズに切り上げられたすべての要素のサイズです。
これら 2 つの値を維持して、 makeBuffer(bytesNoCopy:)指定された VM 領域に直接バッファーを作成し、オーバーヘッドを削減する冗長な再割り当てを回避できるようにします。 Metal に渡されるメモリがページ位置合わせされていない場合、Metal はこのメモリを入力バッファまたは出力バッファとして使用できません。新しいバッファを作成し、入力メモリの場所からデータをコピーするmakeBuffer(bytes:)メソッドを使用する必要があります。したがって、 Variable内のすべてのメモリがページ アラインメントされていることを確認するには、常に必要以上のメモリを割り当てる必要があります。したがって、このメモリのチャンクが正確にどれくらいの大きさであるか、またどれくらいの大きさを使用すべきかを追跡するには 2 つの値が必要です。
3. 単一スレッドで処理される要素の数
1 つのスレッドを複数の要素 (スレッドあたり 2 ~ 16 要素) にマップしようとしました。パフォーマンスはほぼ同じですが、プロジェクトが大幅に複雑になるため、このアプローチは破棄しました。
以下で説明するすべての CPU バージョンは、SIMD 最適化を行わない単純なシングルスレッド CPU コードです。レベル-Ofastのコンパイラ最適化が適用されます。
私たちの実装のパフォーマンスは良好ですが、十分ではありません。
iPhone 6s と 15 インチ MacBook Pro をベンチマーク プラットフォームとして適用しました。ハードウェアは以下で指定されます。
MacBook Pro(Retina 15インチ、Mid 2015)
iPhone6S
並列処理を行わない単純な CPU バージョンの実装と比較すると、GPU バージョンは60 倍以上高速です。
MNIST モデルが小さすぎるため、その結果は正確な高速化を反映していない可能性があります。また、適切に実装されたシングルスレッド バージョンがないため、正確な高速化数値を示すことはできません。 CPU のバージョンが遅すぎるため、Tiny YOLO の高速化は信じられないほど大きくなります。
実験ネットワーク属性:
MNIST:
ヨロ:
測定結果:
| iPhone 6s | MNIST | 小さなヨロ |
|---|---|---|
| CPU | 1500ミリ秒 | 753秒 |
| GPU | 0.025秒 | 0.5秒 |
| スピードを上げる | ~60倍 | ~1500倍 |
| マックブックプロ | MNIST | 小さなヨロ |
|---|---|---|
| CPU | 650ミリ秒 | 729秒 |
| GPU | 10ミリ秒 | 0.028秒 |
| スピードを上げる | ~65倍 | ~26000x |
上記のベンチマークに基づくと、問題のサイズが大きくなるにつれて、
高速化が十分ではないと言えるのはなぜでしょうか? MPSCNNConvolutionの Apple 公式実装と比較すると、速度が約 3 分の 1 しかないため、最適化の余地がまだたくさんあることを意味します。この比較は、公式MPSCNNConvolutionを使用した iPhone 上の YOLO のオープンソース実装に基づいています。この実装では 1 秒あたり最大 5 枚の画像を認識できますが、私たちの実装では 1 秒あたり最大 2 枚の画像しか認識できません。
また、時間が限られていたため、ベンチマークを実行するためのより優れたベースライン バージョンと CPU 並列バージョンを作成できなかったため、高速化の数値が大きくなりすぎました。
また、さまざまな問題サイズでのパフォーマンスの向上を報告することも価値があります。見てわかるように、MNIST には 10 万の重みしかありませんが、Tiny YOLO には 1,700 万の重みがあります。 Tiny YOLO は MNIST よりもはるかに複雑ですが、GPU バージョンの実行時間はそれほどスケールしませんでした。それもアムダールの法則によるものです。 GPU タスクが起動されるたびに、対応する GPU コマンドをコマンド バッファーにエンコードする必要があります。このプロセスは本質的にシリアルです。問題のサイズが小さい場合、このプロセスは総実行時間に大きく寄与するため、MINST でニューラル ネットワーク推論ステージを並列化しても、実行時間のオーバーヘッドが無視できる Tiny YOLO ほど高速化されない可能性があります。
スピードアップを制限したものは何ですか?
ifおよびforがあり、SIMD の使用率が低下する可能性があります。より深い分析: さまざまなフェーズの実行時間の内訳。
Tiny YOLO を例にとると、Macbook での合計実行時間 227 ミリ秒のサンプル実行では、畳み込み層は合計実行時間の 92% である 207 ミリ秒を使用しました。プーリング層は 14 ミリ秒 (6%)、ReLU は 6 ミリ秒 (2%) を使用しました。アムダールの法則によれば、パフォーマンスをさらに向上させたい場合は、畳み込み層の開発を継続する必要があります。
全体として、iOS および macOS デバイスでニューラル ネットワーク アクセラレーションを実行するために Metal フレームワークを選択したことは、特に iOS デバイスにとって適切であると考えています。コアの数が少ないため、SIMD 命令を使用しても、適切に調整された CPU バージョンは GPU バージョンと同様のパフォーマンスを得る可能性が低くなります。
両方のチームメンバーが同等の作業を行います。
1 https://developer.apple.com/metal/ ↩
2 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
3 http://pytorch.org ↩
4 https://github.com/BVLC/caffe ↩
5 https://developer.apple.com/documentation/metal/compute_processing/about_threads_and_threadgroups ↩
6 https://developer.apple.com/library/content/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Render-Ctx/Render-Ctx.html ↩


