Image to text chrome extension
1.0.0
OCR の概念を使用して、ブラウザ内のあらゆるビデオや画像からあらゆる種類のテキストを認識できる Chrome 拡張機能。 OCR は、Optical Character Recognition (光学式文字認識) の略称で、画像内のテキストを検索する言葉です。 Google は以前 Tesseract OCR と呼ばれるエンジンをリリースしていました。これは、Google がテキスト認識をすでにトレーニングしたプログラムを提供していることを意味します。そのため、OCR でデータをトレーニングするような複雑なことを自分で行う必要はありません。ただし、より正確にするためには、Tesseract に画像を渡す前に画像を前処理する必要があります。Tesseract には、正確な結果を得るために従う必要があるいくつかの事前定義された状況があるためです。したがって、拡張機能の機能としては、まず現在開いているタブからスクリーンショットを取得し、次にキャンバスを使用して目的の部分を切り取り、しきい値二値化を使用して調整して、OCR 要件を満たすことができ、より正確な結果が得られます。次に、それを pytesseract (Tesseract の Python バージョン) に送信して、変換できるようにします。最後にテキストを取得し、.txt ファイル形式でダウンロードします。そのため、ユーザーはメモ帳またはその他のテキスト エディタでファイルを開いて、必要に応じてテキストを比較および変更できます。
YouTube やその他の Web サイトでコード スニペットに遭遇することはよくありますが、ダウンロードまたはコピーするためのリンクが提供されていないコードに遭遇するたびに、チュートリアル作成者がビデオに費やした労力に非常に感謝しています。そこで、これらのビデオからコードを取得するために、tesseract プラグインを使用してこのプロジェクトを作成し、ビデオや画像からテキストを抽出できるようにしました。
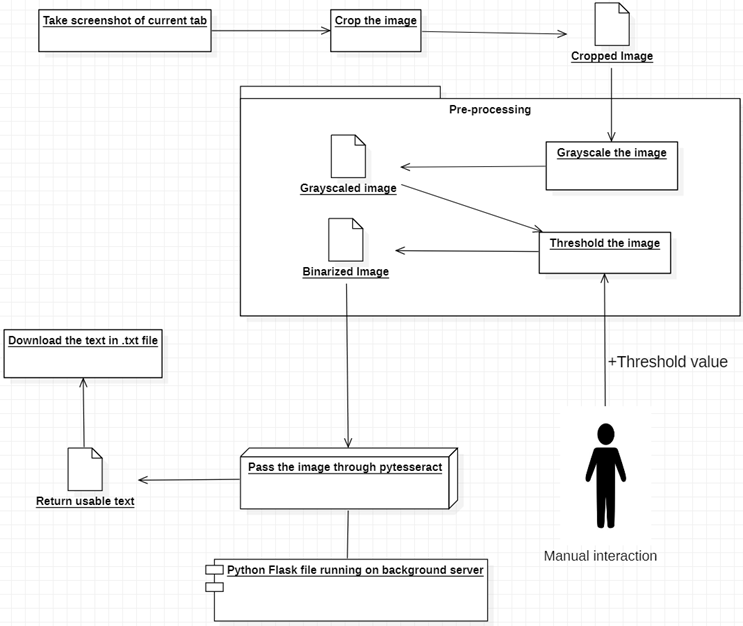
モジュールの実装とデモは ppt にあります。
pip install pytesseract
npm i flask
jQuery min ファイルは、変更したい場合、または cdn アプローチを使用して変更できる場合に備えて、ファイルに添付されています。


