disclosure backend static
1.0.0
disclosure-backend-staticリポジトリは、Open Disclosure California を駆動するバックエンドです。
これは 2016 年の選挙に向けて急いで作成されたため、「やり遂げる」という理念に基づいて設計されています。その時点で、私たちはすでに API を設計し、フロントエンド (ほとんど) を構築していました。このリポジトリは、これらをできるだけ早く実装するために作成されました。
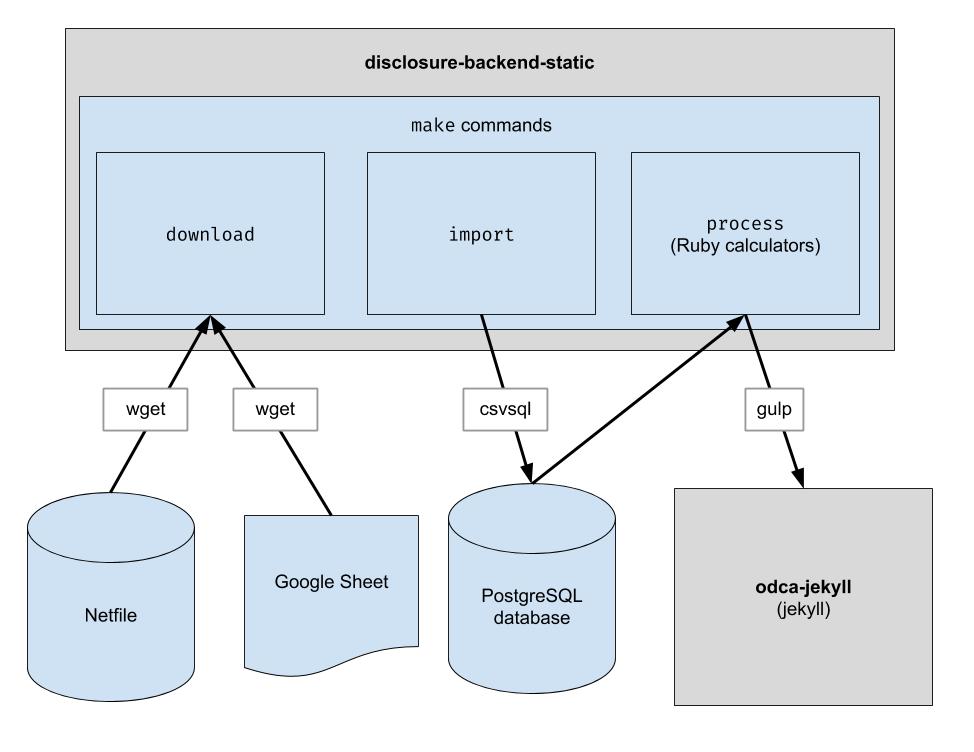
このプロジェクトは、オークランドのネットファイル データをダウンロードし、人間が厳選したオークランドの CSV データをダウンロードし、その 2 つを結合するための基本的な ETL パイプラインを実装します。出力は既存の API 構造を模倣した JSON ファイルのディレクトリであるため、クライアント コードの変更は必要ありません。
.ruby-versionのバージョンを参照) 注:フロントエンドで開発する場合、これらのコマンドを実行する必要はありません。必要なのは、フロントエンド リポジトリに隣接するリポジトリのクローンを作成することだけです。
バックエンド コードを変更する予定がある場合は、次の手順に従って、新しい PostgreSQL データベースや Python 3 など、必要な開発依存関係をすべてセットアップします。
brew update && brew upgrade
brew install postgresql@16
brew services start postgresql@16
pipの代わりにpython3 -m pip使用します。 python3 -m pip install ...
pip Python 3 を指している場合は、 pip直接使用できます。 pip install ...
sudo -H python -m pip install -r requirements.txt
gem install pg bundler
bundle install
このリポジトリは、Codespaces の下のコンテナで動作するように設定されています。つまり、ローカル環境のセットアップに必要なインストール手順を実行せずに、すでにセットアップされている環境を起動できます。これは、実稼働パイプラインにコミットされる前にコードのトラブルシューティングを行う方法として使用できます。コードスペースの使用を開始するには、次の情報が役立つ場合があります。
Codeボタンをクリックし、ドロップダウンのCodespacesタブをクリックします。/workspaceのターミナル プロンプトが表示されるまで待ちます。以前に VS Code を使用したことがある場合は見覚えがあるはずです。make downloadなどのコマンドの実行を開始できます。psqlと入力するだけでサーバーに接続できます。make importコマンドは Postgres データベースにデータを取り込みますgit push行わないと GitHub リポジトリに保存されません。このリポジトリは、Docker コンテナ内で実行されるように構成されています。これは Codespaces に似ていますが、好みの IDE とローカル設定を使用できる点が異なります。 VSCode で Docker の使用を開始する方法は次のとおりです。
生データ ファイルをダウンロードします。最新のデータを取得するには、これを時々実行するだけで済みます。
$ make download
処理を容易にするためにデータをデータベースにインポートします。これを実行する必要があるのは、新しいデータをダウンロードした後でのみです。
$ make import
計算機を実行します。すべてが「build」フォルダーに出力されます。
$ make process
必要に応じて、ビルド出力のインデックスを Algolia に再作成します。 (インデックスの再作成には、ALGOLIASEARCH_APPLICATION_ID および ALGOLIASEARCH_API_KEY 環境変数が必要です)。
$ make reindex
静的 JSON ファイルをローカル Web サーバー経由で提供する場合は、次のようにします。
$ make run
make import実行すると、ダウンロードしたデータをインポートするために多数の postgres テーブルが作成されます。これらのテーブルのスキーマはdbschemaディレクトリで明示的に定義されており、将来のデータに対応するために将来更新する必要がある場合があります。文字列データを保持する列のサイズが、将来のデータに十分な大きさにならない可能性があります。たとえば、名前列が最大 20 文字の名前を受け入れ、将来、名前の長さが 21 文字のデータが存在する場合、データのインポートは失敗します。この問題が発生した場合、より多くの文字をサポートするためにdbschema内の対応するスキーマ ファイルを更新する必要があります。変更を加えてmake importを再実行し、成功することを確認するだけです。
このリポジトリは、Web サイトで使用されるデータ ファイルを生成するために使用されます。 make processが実行されると、データ ファイルを含むbuildディレクトリが生成されます。このディレクトリはリポジトリにチェックインされ、後で Web サイトの生成時にチェックアウトされます。コードを変更した後は、生成されたbuildディレクトリとコード変更前に生成されたbuildディレクトリを比較し、コード変更による変更が期待どおりであることを確認することが重要です。
buildディレクトリのすべての内容の厳密な比較には、コードの変更とは関係なく発生する変更が常に含まれるため、すべての開発者は、このチェックを実行するために、これらの予想される変更について知っておく必要があります。この必要性を排除するために、特定のファイルbin/create-digests.py 、これらの予想される変更を除外した後、 buildディレクトリ内の JSON データのダイジェストを生成します。これらの予想される変更を除外する変更を探すには、 build/digests.jsonファイル内の変更を探すだけです。
現時点では、コードの変更とは関係なく発生すると予想される変更は次のとおりです。
予想される変更は、 buildディレクトリ内のデータのダイジェストを生成する前に除外されます。このロジックは、ファイルbin/create-digests.pyにある関数clean_dataにあります。予期された変更が存在しないようにコードが変更された後、その変更の除外をclean_dataから削除できます。たとえば、float の丸めは、環境の違いにより、 make processが実行されるたびに一貫して同じではありません。データが変更されない限り浮動小数点数の丸めが同じになるようにコードが修正されると、 clean_data内のround_float呼び出しを削除できます。
候補者の合計を比較できるレポートを生成する追加のスクリプトが作成されました。スクリプトはbin/report-candidates.pyで、 build/candidates.csvとbuild/candidates.xlsxを生成します。レポートには、すべての候補者のリストと、合計すると同じ数になるはずの複数の方法で計算された合計が含まれます。
データベース スキーマの変更がプル リクエストに表示されるようにするために、完全な postgres スキーマもbuildディレクトリのschema.sqlファイルに保存されます。 buildディレクトリは PR 内のブランチごとに自動的に再構築され、リポジトリにコミットされるため、コード変更によるスキーマへの変更は、PR をレビューするときにschema.sqlファイルの違いとして示されます。
候補者に関する各メトリックは独立して計算されます。指標には、「受け取った寄付金の合計」などのものもあれば、「100 ドル未満の寄付金の割合」などのより複雑なものもあります。
新しい計算を追加するときは、まず公式のフォーム 460 から始めるのが良いでしょう。探しているデータはそのフォームで報告されていますか?その場合は、インポート プロセス後にデータベースで見つかる可能性があります。 Form 496 など、インポートするフォームが他にもいくつかあります (これらはinputディレクトリ内のファイルの名前です。確認してください)。
各フォームの各スケジュールは、別の postgres テーブルにインポートされます。たとえば、フォーム 460 のスケジュール A は、 A-Contributionsテーブルにインポートされます。
データをクエリする方法ができたので、取得しようとしている値を計算する SQL クエリを作成する必要があります。計算を SQL として表現できたら、次のように計算ファイルに記述します。
calculators/[your_thing]_calculator.rbという名前の新しいファイルを作成します。 # the name of this class _must_ match the filename of this file, i.e. end
# with "Calculator" if the file ends with "_calculator.rb"
class YourThingCalculator
def initialize ( candidates : [ ] , ballot_measures : [ ] , committees : [ ] )
@candidates = candidates
@candidates_by_filer_id = @candidates . where ( '"FPPC" IS NOT NULL' )
. index_by { | candidate | candidate [ 'FPPC' ] }
end
def fetch
@results = ActiveRecord :: Base . connection . execute ( <<-SQL )
-- your sql query here
SQL
@results . each do | row |
# make sure Filer_ID is returned as a column by your query!
candidate = @candidates_by_filer_id [ row [ 'Filer_ID' ] . to_i ]
# change this!
candidate . save_calculation ( :your_thing , row [ column_with_your_desired_data ] )
end
end
endFiler_ID列が選択されていることを確認します。candidate.save_calculationの呼び出しを更新してください。このメソッドは 2 番目の引数を JSON としてシリアル化するため、あらゆる種類のデータを保存できます。candidate.calculation(:your_thing)で取得できます。これをprocess.rbファイルの API 応答に追加するとよいでしょう。 これがバックエンドを介したデータの流れです。財務データは Netfile から取得され、Google シートで候補者名、事務所、投票指標などの投票情報にファイラー ID をマッピングすることで補完されます。データがフィルタリング、集計、変換されると、フロントエンドがそれを使用して静的 HTML を構築します。フロントエンド。
バンドルのインストール中
error: use of undeclared identifier 'LZMA_OK'
試す:
brew unlink xz
bundle install
brew link xz
make download中
wget: command not found
brew install wget実行します。
make import中
Apple チップを使用している Macintosh システムに問題があるようです。
ImportError: You don't appear to have the necessary database backend installed for connection string you're trying to use. Available backends include:
PostgreSQL: pip install psycopg2
次のことを試してください。
pip uninstall psycopg2-binary
pip install psycopg2-binary --no-cache-dir


