offensive ai compilation
1.0.0
攻撃的な AI をカバーする役立つリソースの厳選されたリスト。
AI モデルの脆弱性を悪用します。
Adversarial Machine Learning は、敵対者の弱点を評価し、対策を提供する責任があります。
攻撃は抽出、反転、中毒、回避の 4 種類に分類されます。
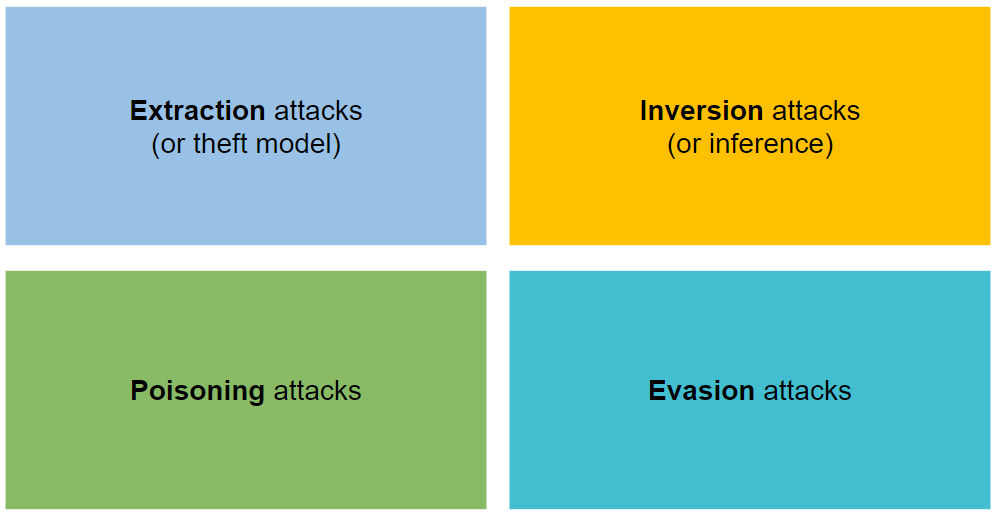
情報の抽出を最大限に高めるリクエストを作成して、モデルのパラメータとハイパーパラメータを盗もうとします。
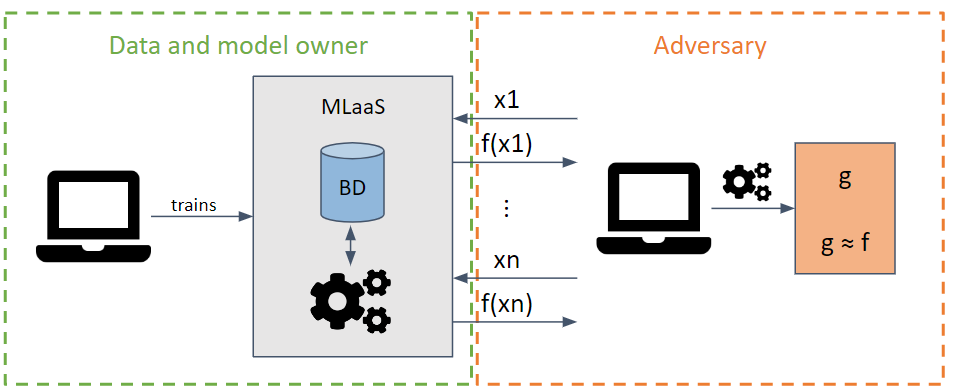
敵対者のモデルの知識に応じて、ホワイトボックス攻撃とブラックボックス攻撃を実行できます。
最も単純なホワイトボックスの場合 (攻撃者がシグモイド関数などのモデルについて十分な知識を持っている場合)、簡単に解ける線形方程式系を作成できます。
一般的なケースでは、モデルに関する知識が不十分な場合、代替モデルが使用されます。このモデルは、元のモデルと同じ機能を模倣するために、元のモデルに対して行われたリクエストを使用してトレーニングされます。
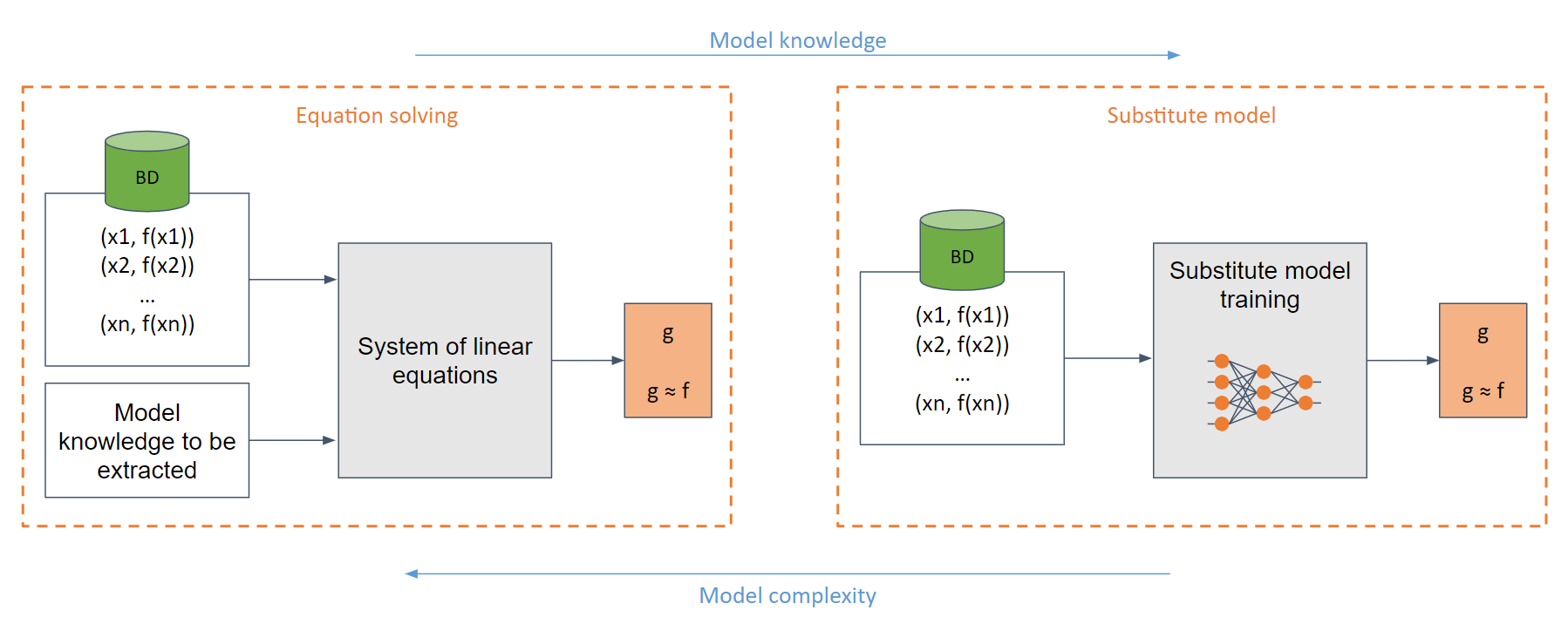
代替モデルをトレーニングすることは、(多くの場合) モデルを最初からトレーニングすることと同等です。
非常に計算量が多い。
攻撃者には、検出されるまでのリクエストの数に制限があります。
出力値の丸め。
差分プライバシーの使用。
アンサンブルの使用。
特定の防御策の使用
これらは、機械学習モデルの情報の流れを逆にすることを目的としています。
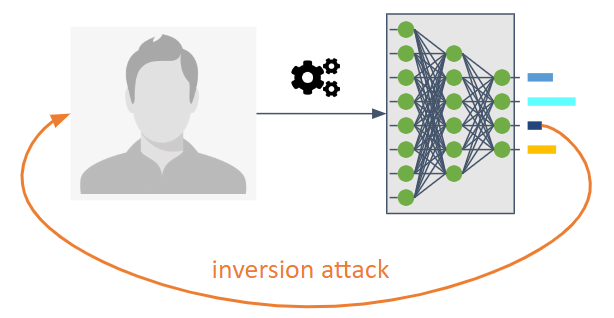
これらにより、敵対者は明示的に共有することを意図していないモデルを知ることができます。
これらにより、トレーニング データや情報をモデルの統計的特性として知ることができます。
次の 3 つのタイプが考えられます。
Membership Inference Attack (MIA) : 攻撃者は、サンプルがトレーニングの一部として使用されたかどうかを判断しようとします。
プロパティ推論攻撃 (PIA) : 攻撃者は、トレーニング段階で特徴として明示的にエンコードされなかった統計プロパティを抽出することを目的としています。
再構築: 敵対者は、トレーニング セットおよび/または対応するラベルから 1 つ以上のサンプルを再構築しようとします。反転とも言います。
高度な暗号化の使用。対策には、差分プライバシー、準同型暗号、安全なマルチパーティ計算が含まれます。
オーバートレーニングとプライバシーの関係によるドロップアウトなどの正則化手法の使用。
モデル圧縮は、再構成攻撃に対する防御として提案されています。
彼らは、機械学習モデルの精度を低下させることでトレーニング セットを破壊することを目的としています。
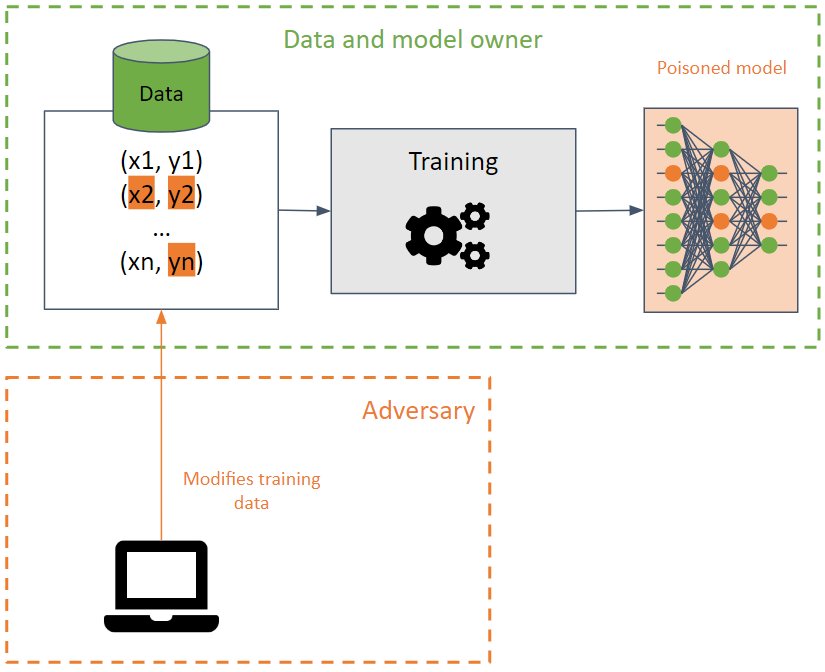
この攻撃は、同じトレーニング データを使用する異なるモデル間で伝播する可能性があるため、トレーニング データに対して実行された場合、検出するのが困難です。
敵対者は、決定境界を変更することでモデルの可用性を破壊し、その結果、誤った予測を生成したり、モデルにバックドアを作成したりしようとします。後者では、望ましくない結果を生み出す敵対者によって特別に作成された特定の入力を除いて、モデルはほとんどの場合正しく動作します (望ましい予測を返します)。攻撃者は予測結果を操作し、将来の攻撃を開始する可能性があります。
BadNet は、機械学習モデルにおける最も単純なタイプのバックドアです。さらに、BadNet は、元のモデルとは異なるタスク (転移学習) で再トレーニングされた場合でも、モデル内に保存できます。
公開されている事前トレーニング済みモデルにはバックドアが含まれている可能性があることに注意することが重要です。
データサニタイズを使用した、汚染されたデータの検出。
しっかりとしたトレーニング方法。
特定の防御策。
攻撃者は、機械学習モデルの入力に小さな摂動 (ノイズの形で) を追加して、モデルを誤って分類させます (攻撃者の例)。
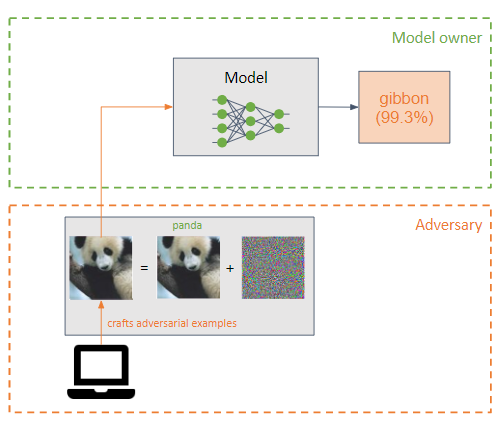
これらはポイズニング攻撃に似ていますが、主な違いは、回避攻撃が推論フェーズでモデルの弱点を悪用しようとすることです。
敵対者の目標は、敵対的な例が人間には知覚できないようにすることです。
相手が望む出力に応じて、2 種類の攻撃を実行できます。
Targeted : 敵は、自分が選択した予測を取得することを目的としています。
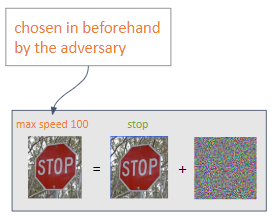
Untargeted : 敵対者は誤分類を達成することを意図しています。

最も一般的な攻撃はホワイトボックス攻撃です。
敵対的トレーニング。トレーニング中に敵対的サンプルを作成して、モデルが敵対的サンプルの特徴を学習できるようにすることで構成され、このタイプの攻撃に対してモデルをより堅牢にします。
入力の変換。
グラデーションマスキング/正則化。あまり効果的ではありません。
防御力が弱い。
プロンプトインジェクション防御: プロンプトインジェクションに対するあらゆる実践的で提案された防御。
Lakera PINT ベンチマーク: プロンプト インジェクション テスト (PINT) ベンチマークは、これらのツールが評価パフォーマンスの最適化に使用できる既知の公開データセットに依存せずに、Lakera Guard などのプロンプト インジェクション検出システムのパフォーマンスを評価する中立的な方法を提供します。
悪魔の推論: 特定の入力にさらされたときの頭部全体の注意の分布を観察することによって、Phi-3 Instruct モデルを敵対的に評価する方法。このアプローチにより、モデルは「悪魔の考え方」を採用するようになり、暴力的な性質の出力を生成できるようになります。
| 名前 | タイプ | サポートされているアルゴリズム | サポートされている攻撃タイプ | 攻撃/防御 | サポートされているフレームワーク | 人気 |
|---|---|---|---|---|---|---|
| クレバーハンス | 画像 | ディープラーニング | 回避 | 攻撃 | Tensorflow、Keras、JAX | |
| フールボックス | 画像 | ディープラーニング | 回避 | 攻撃 | Tensorflow、PyTorch、JAX | |
| 美術 | 任意のタイプ (画像、表形式データ、音声など) | ディープラーニング、SVM、LRなど | 任意 (抽出、推論、中毒、回避) | 両方 | Tensorflow、Keras、Pytorch、Scikit Learn | |
| テキスト攻撃 | 文章 | ディープラーニング | 回避 | 攻撃 | ケラス、ハグフェイス | |
| アドバートーチ | 画像 | ディープラーニング | 回避 | 両方 | --- | |
| アドボックス | 画像 | ディープラーニング | 回避 | 両方 | PyTorch、Tensorflow、MxNet | |
| 深い堅牢な | 画像、グラフ | ディープラーニング | 回避 | 両方 | パイトーチ | |
| カウンターフィット | どれでも | どれでも | 回避 | 攻撃 | --- | |
| 敵対的な音声の例 | オーディオ | ディープスピーチ | 回避 | 攻撃 | --- |
Adversarial Robustness Toolbox (ART と略称) は、機械学習モデルの堅牢性をテストするためのオープンソースの Adversarial Machine Learning ライブラリです。

これは Python で開発されており、抽出、反転、ポイズニング、および回避の攻撃と防御を実装しています。
ART は、Tensorflow、Keras、PyTorch、MxNet、ScikitLearn などの最も人気のあるフレームワークをサポートしています。
画像を入力として使用するモデルの使用に限定されず、オーディオ、ビデオ、表形式データなどの他のタイプのデータもサポートします。
ARTで敵対的機械学習を学ぶワークショップ ??
Cleverhans は、回避攻撃を実行し、画像モデルに対する深層学習モデルの堅牢性をテストするためのライブラリです。

Python で開発され、Tensorflow、Torch、JAX フレームワークと統合されています。
L-BFGS、FGSM、JSMA、C&W などの多数の攻撃を実行します。
AI は、悪意のあるタスクを実行し、古典的な攻撃を強化するために使用されます。
ミゲル・ヘルナンデス | ホセ・イグナシオ・エスクライクノ |


