phenaki pytorch
0.5.0
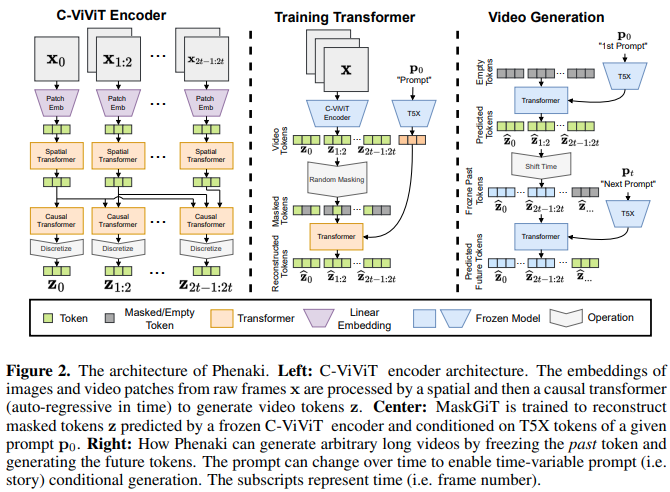
Phenaki Video の実装。Mask GIT を使用して、長さ最大 2 分のテキスト ガイド付きビデオを Pytorch で作成します。また、潜在的にさらに優れた世代のために、トークン批評家を含む別の手法も組み合わせる予定です。
この作品を公開で再現することに興味がある場合は、参加してください
AI コーヒーブレイクの説明
Stability.ai は最先端の人工知能研究に取り組むための寛大なスポンサーシップを提供しています
?素晴らしいトランスフォーマーとアクセラレータ ライブラリにハグフェイス
ギエムの継続的な貢献に感謝
あなた?あなたが優れた機械学習エンジニアや研究者であれば、オープンソースの生成 AI の最前線に自由に貢献してください。
$ pip install phenaki-pytorchC-ビビット
import torch
from phenaki_pytorch import CViViT , CViViTTrainer
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = 256 ,
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
). cuda ()
trainer = CViViTTrainer (
cvivit ,
folder = '/path/to/images/or/videos' ,
batch_size = 4 ,
grad_accum_every = 4 ,
train_on_images = False , # you can train on images first, before fine tuning on video, for sample efficiency
use_ema = False , # recommended to be turned on (keeps exponential moving averaged cvivit) unless if you don't have enough resources
num_train_steps = 10000
)
trainer . train () # reconstructions and checkpoints will be saved periodically to ./resultsフェナキ
import torch
from phenaki_pytorch import CViViT , MaskGit , Phenaki
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = ( 256 , 128 ), # video with rectangular screen allowed
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
)
cvivit . load ( '/path/to/trained/cvivit.pt' )
maskgit = MaskGit (
num_tokens = 5000 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
)
phenaki = Phenaki (
cvivit = cvivit ,
maskgit = maskgit
). cuda ()
videos = torch . randn ( 3 , 3 , 17 , 256 , 128 ). cuda () # (batch, channels, frames, height, width)
mask = torch . ones (( 3 , 17 )). bool (). cuda () # [optional] (batch, frames) - allows for co-training videos of different lengths as well as video and images in the same batch
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
loss = phenaki ( videos , texts = texts , video_frame_mask = mask )
loss . backward ()
# do the above for many steps, then ...
video = phenaki . sample ( texts = 'a squirrel examines an acorn' , num_frames = 17 , cond_scale = 5. ) # (1, 3, 17, 256, 128)
# so in the paper, they do not really achieve 2 minutes of coherent video
# at each new scene with new text conditioning, they condition on the previous K frames
# you can easily achieve this with this framework as so
video_prime = video [:, :, - 3 :] # (1, 3, 3, 256, 128) # say K = 3
video_next = phenaki . sample ( texts = 'a cat watches the squirrel from afar' , prime_frames = video_prime , num_frames = 14 ) # (1, 3, 14, 256, 128)
# the total video
entire_video = torch . cat (( video , video_next ), dim = 2 ) # (1, 3, 17 + 14, 256, 128)
# and so on...または、 make_video関数をインポートするだけです
# ... above code
from phenaki_pytorch import make_video
entire_video , scenes = make_video ( phenaki , texts = [
'a squirrel examines an acorn buried in the snow' ,
'a cat watches the squirrel from a frosted window sill' ,
'zoom out to show the entire living room, with the cat residing by the window sill'
], num_frames = ( 17 , 14 , 14 ), prime_lengths = ( 5 , 5 ))
entire_video . shape # (1, 3, 17 + 14 + 14 = 45, 256, 256)
# scenes - List[Tensor[3]] - video segment of each sceneそれでおしまい!
新しい論文は、信頼性の尺度として各トークンの予測確率に依存する代わりに、追加の批評家を訓練して、サンプリング中に何を繰り返しマスクするかを決定できることを示唆しています。以下に示すように、オプションでこの批評家を潜在的により良い世代に向けてトレーニングできます。
import torch
from phenaki_pytorch import CViViT , MaskGit , TokenCritic , Phenaki
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = ( 256 , 128 ),
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
)
maskgit = MaskGit (
num_tokens = 65536 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
)
# (1) define the critic
critic = TokenCritic (
num_tokens = 65536 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
has_cross_attn = True
)
trainer = Phenaki (
maskgit = maskgit ,
cvivit = cvivit ,
critic = critic # and then (2) pass it into Phenaki
). cuda ()
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
videos = torch . randn ( 3 , 3 , 3 , 256 , 128 ). cuda () # (batch, channels, frames, height, width)
loss = trainer ( videos = videos , texts = texts )
loss . backward ()あるいは、さらに単純には、 Phenakiの初期化時にself_token_critic = True設定することで、 MaskGit自体を Self Critic (Nijkamp ら) として再利用するだけです。
phenaki = Phenaki (
...,
self_token_critic = True # set this to True
)これで、あなたの世代は大幅に改善されるはずです。
このリポジトリでは、研究者がテキストから画像へ、さらにテキストからビデオへのトレーニングができるようにする予定です。同様に、無条件トレーニングの場合、研究者は最初に画像でトレーニングし、次にビデオで微調整できる必要があります。以下はテキストからビデオへの例です。
import torch
from torch . utils . data import Dataset
from phenaki_pytorch import CViViT , MaskGit , Phenaki , PhenakiTrainer
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = 256 ,
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
)
cvivit . load ( '/path/to/trained/cvivit.pt' )
maskgit = MaskGit (
num_tokens = 5000 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
unconditional = False
)
phenaki = Phenaki (
cvivit = cvivit ,
maskgit = maskgit
). cuda ()
# mock text video dataset
# you will have to extend your own, and return the (<video tensor>, <caption>) tuple
class MockTextVideoDataset ( Dataset ):
def __init__ (
self ,
length = 100 ,
image_size = 256 ,
num_frames = 17
):
super (). __init__ ()
self . num_frames = num_frames
self . image_size = image_size
self . len = length
def __len__ ( self ):
return self . len
def __getitem__ ( self , idx ):
video = torch . randn ( 3 , self . num_frames , self . image_size , self . image_size )
caption = 'video caption'
return video , caption
dataset = MockTextVideoDataset ()
# pass in the dataset
trainer = PhenakiTrainer (
phenaki = phenaki ,
batch_size = 4 ,
grad_accum_every = 4 ,
train_on_images = False , # if your mock dataset above return (images, caption) pairs, set this to True
dataset = dataset , # pass in your dataset here
sample_texts_file_path = '/path/to/captions.txt' # each caption should be on a new line, during sampling, will be randomly drawn
)
trainer . train ()無条件とは以下の通り
元。無条件の画像とビデオのトレーニング
import torch
from phenaki_pytorch import CViViT , MaskGit , Phenaki , PhenakiTrainer
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = 256 ,
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
)
cvivit . load ( '/path/to/trained/cvivit.pt' )
maskgit = MaskGit (
num_tokens = 5000 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
unconditional = False
)
phenaki = Phenaki (
cvivit = cvivit ,
maskgit = maskgit
). cuda ()
# pass in the folder to images or video
trainer = PhenakiTrainer (
phenaki = phenaki ,
batch_size = 4 ,
grad_accum_every = 4 ,
train_on_images = True , # for sake of example, bottom is folder of images
dataset = '/path/to/images/or/video'
)
trainer . train ()マスク確率をmaskgitとautomaskに渡し、クロスエントロピー損失を取得します
クロスアテンション + imagen-pytorch から t5 埋め込みコードを取得し、分類器の無料ガイダンスを接続します
c-vivit 用に完全な vqgan-vae を接続します。parti-pytorch に既にあるものを使用するだけですが、論文で述べられているように、必ず stylegan 識別子を使用してください。
完全なトークン評論家トレーニング コード
マスクギットのスケジュールされたサンプリング + トークン批評家の最初のパスを完了します (研究者が追加のトレーニングをしたくない場合はオプションなし)
スライド時間 + 過去の K フレームの条件付けを可能にする推論コード
一時的な注意に対するアリバイ肯定バイアス
空間に注意を向ける、最も強力な位置バイアスを与える
stylegan 風の識別子を必ず使用してください
マスクギットの 3D 相対位置バイアス
マスクギットが画像のトレーニングもサポートできることを確認し、ローカルマシンで動作することを確認してください
テキストで条件付けされるトークン批評家のオプションも構築します
最初にテキストから画像への生成をトレーニングできるはずです
批評家トレーナーが cvivit を取り込み、相対位置バイアスのビデオ パッチ形状を自動的に渡すことができることを確認します。批評家も最適な相対位置バイアスを取得できるようにします。
cvivit のトレーニング コード
cvivit を独自のファイルに移動する
無条件の生成 (ビデオと画像の両方)
c-vivit とマスクギットの両方のマルチ GPU トレーニング用に加速を接続します。
位置生成のために Depthwise-convs を cvivit に追加します
いくつかの基本的なビデオ操作コード。サンプリングされたテンソルを gif として保存できるようにします。
基本的な批評家トレーニングコード
位置生成dsconvもmaskgitに追加
スタイルガン識別子への衣装のカスタマイズ可能な自己注意ブロック
変圧器のトレーニングを安定させるための最先端の研究をすべて追加
基本的な批評家サンプリング コードを取得し、批評家ありと批評家なしの比較を表示します。
連結トークンシフトを導入する(時間次元)
DDPM アップサンプラーを追加します。imagen-pytorch から移植するか、ここで単純なバージョンを書き換えます。
マスキングはmaskgitで処理してください
オックスフォードの花のデータセットでマスクギットと批評家を単独でテストする
長方形サイズのビデオをサポート
すべてのトランスフォーマーのオプションとしてフラッシュ アテンションを追加し、@tridao を引用します
@article { Villegas2022PhenakiVL ,
title = { Phenaki: Variable Length Video Generation From Open Domain Textual Description } ,
author = { Ruben Villegas and Mohammad Babaeizadeh and Pieter-Jan Kindermans and Hernan Moraldo and Han Zhang and Mohammad Taghi Saffar and Santiago Castro and Julius Kunze and D. Erhan } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02399 }
} @article { Chang2022MaskGITMG ,
title = { MaskGIT: Masked Generative Image Transformer } ,
author = { Huiwen Chang and Han Zhang and Lu Jiang and Ce Liu and William T. Freeman } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11305-11315 }
} @article { Lezama2022ImprovedMI ,
title = { Improved Masked Image Generation with Token-Critic } ,
author = { Jos{'e} Lezama and Huiwen Chang and Lu Jiang and Irfan Essa } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2209.04439 }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { press2021ALiBi ,
title = { Train Short, Test Long: Attention with Linear Biases Enable Input Length Extrapolation } ,
author = { Ofir Press and Noah A. Smith and Mike Lewis } ,
year = { 2021 } ,
url = { https://ofir.io/train_short_test_long.pdf }
} @article { Liu2022SwinTV ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11999-12009 }
} @inproceedings { Nijkamp2021SCRIPTSP ,
title = { SCRIPT: Self-Critic PreTraining of Transformers } ,
author = { Erik Nijkamp and Bo Pang and Ying Nian Wu and Caiming Xiong } ,
booktitle = { North American Chapter of the Association for Computational Linguistics } ,
year = { 2021 }
} @misc { https://doi.org/10.48550/arxiv.2302.01327 ,
doi = { 10.48550/ARXIV.2302.01327 } ,
url = { https://arxiv.org/abs/2302.01327 } ,
author = { Kumar, Manoj and Dehghani, Mostafa and Houlsby, Neil } ,
title = { Dual PatchNorm } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { Creative Commons Attribution 4.0 International }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @misc { mentzer2023finite ,
title = { Finite Scalar Quantization: VQ-VAE Made Simple } ,
author = { Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen } ,
year = { 2023 } ,
eprint = { 2309.15505 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

