imagen pytorch
2.1.0
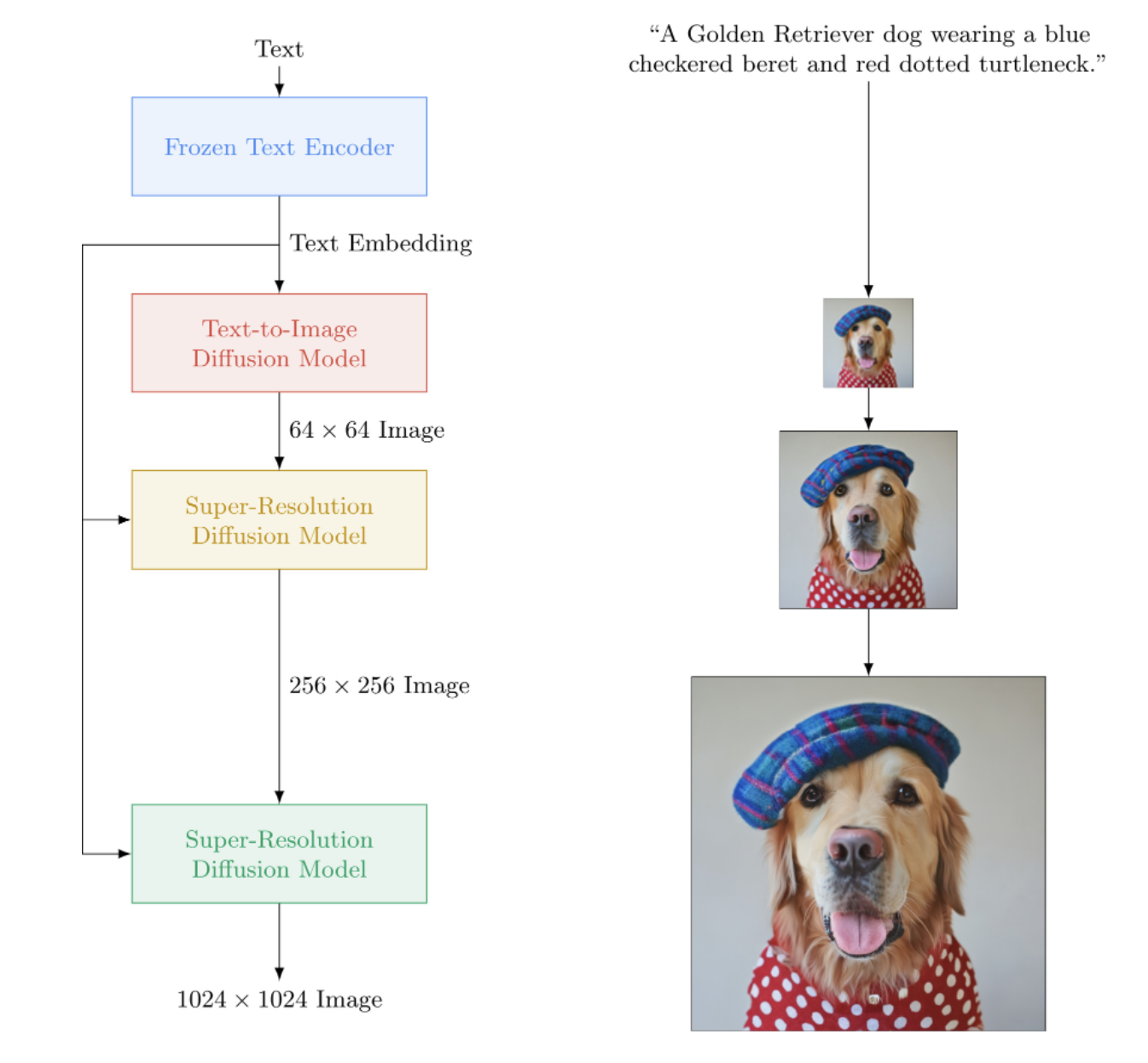
DALL-E2 を上回る Google の Text-to-Image ニューラル ネットワークである Imagen を Pytorch で実装。これは、テキストから画像への合成のための新しい SOTA です。
アーキテクチャ的には、実際には DALL-E2 よりもはるかに単純です。これは、大規模な事前トレーニング済み T5 モデル (アテンション ネットワーク) からのテキスト埋め込みに条件付けされたカスケード DDPM で構成されます。また、改善された分類子なしのガイダンス、ノイズ レベルの調整、およびメモリ効率の高い unet 設計のための動的クリッピングも含まれています。
結局のところ、CLIP も事前のネットワークも必要ないようです。そして研究は続けられています。
レティシアと AI コーヒーブレイク |組立AI |ヤニック・キルチャー
LAION コミュニティでレプリケーションを支援することに興味がある場合は、ぜひご参加ください。
StabilityAI の寛大なスポンサーシップと、他のスポンサーの皆様
?彼らの素晴らしいトランスフォーマーライブラリにハグフェイス。テキストエンコーダ部分は、これらのおかげでかなり処理されます。
ジョナサン・ホー氏、独創的な論文を通じて生成人工知能に革命をもたらした功績
このリポジトリが分散トレーニングに使用する Accelerate ライブラリの Sylvain と Zachary
Alex の einops、テンソル操作に不可欠なツール
Jorge Gomes は、T5 ロード コードと正しい T5 バージョンに関するアドバイスを手伝ってくれました。
Katherine Crowson、彼女の美しいコード、ガウス拡散の連続時間バージョンを理解するのに役立ちました
Marunine と Netruk44、コードのレビュー、実験結果の共有、デバッグ支援
メモリ効率の高い u-net におけるカラーシフトの問題に対する潜在的な解決策を提供してくださった Marunine。基本ユニットとメモリ効率の高いユニットの実験的な比較を共有してくれた Jacob に感謝します
マルニネさん、多数のバグを発見し、適切なサイズ変更に関する問題を解決し、実験的な構成と結果を共有してくれました
MalumaDev は、チェックボードのアーティファクトを修正するためのピクセル シャッフル アップサンプラーの使用を提案してくださいました。
Valentin は、unet でのスキップ接続が不十分であること、および付録の Base-unet でのアテンション コンディショニングの具体的な方法を指摘してくれました。
BIGJUN 推論時の連続時間ガウス拡散ノイズ レベル コンディショニングで大きなバグを捕捉する
Bingbing は、低解像度の調整画像によるサンプリングと正規化の順序とノイズのバグを特定します。
Kay は Imagen の 1 行コマンド トレーニングに貢献してくれました!
Hadrien Reynaud は、医療データセットでテキストからビデオへの変換をテストし、結果を共有し、問題を特定してくれました。
$ pip install imagen-pytorch import torch
from imagen_pytorch import Unet , Imagen
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
layer_cross_attns = ( False , True , True , True )
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , text_embeds = text_embeds , unet_number = i )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = imagen . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
], cond_scale = 3. )
images . shape # (3, 3, 256, 256)トレーニングをより簡単にするには、テキスト エンコーディングを事前に計算する代わりに、テキスト文字列を直接指定できます。 (スケーリングの目的ではありますが、テキストの埋め込みとマスクを事前計算する必要があることは間違いありません)
この方法を使用する場合、テキスト キャプションの数は画像のバッチ サイズと一致する必要があります。
# mock images and text (get a lot of this)
texts = [
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
]
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , texts = texts , unet_number = i )
loss . backward () ImagenTrainerラッパー クラスを使用すると、カスケード DDPM 内のすべての U ネットの指数移動平均が、 update呼び出し時に自動的に処理されます。
import torch
from imagen_pytorch import Unet , Imagen , ImagenTrainer
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
text_encoder_name = 't5-large' ,
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# wrap imagen with the trainer class
trainer = ImagenTrainer ( imagen )
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 64 , 256 , 1024 ). cuda ()
images = torch . randn ( 64 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = trainer (
images ,
text_embeds = text_embeds ,
unet_number = 1 , # training on unet number 1 in this example, but you will have to also save checkpoints and then reload and continue training on unet number 2
max_batch_size = 4 # auto divide the batch of 64 up into batch size of 4 and accumulate gradients, so it all fits in memory
)
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = trainer . sample ( texts = [
'a puppy looking anxiously at a giant donut on the table' ,
'the milky way galaxy in the style of monet'
], cond_scale = 3. )
images . shape # (2, 3, 256, 256)次のように、テキストなしで Imagen をトレーニングすることもできます (無条件の画像生成)。
import torch
from imagen_pytorch import Unet , Imagen , SRUnet256 , ImagenTrainer
# unets for unconditional imagen
unet1 = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True ),
layer_cross_attns = False ,
use_linear_attn = True
)
unet2 = SRUnet256 (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = ( 2 , 4 , 8 ),
layer_attns = ( False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
timesteps = 1000
)
trainer = ImagenTrainer ( imagen ). cuda ()
# now get a ton of images and feed it through the Imagen trainer
training_images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train each unet separately
# in this example, only training on unet number 1
loss = trainer ( training_images , unet_number = 1 )
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample images unconditionally from the cascading unet(s)
images = trainer . sample ( batch_size = 16 ) # (16, 3, 128, 128)または、超解像ユニットのみをトレーニングします
import torch
from imagen_pytorch import Unet , NullUnet , Imagen
# unet for imagen
unet1 = NullUnet () # add a placeholder "null" unet for the base unet
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 250 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = imagen ( images , text_embeds = text_embeds , unet_number = 2 )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings as well as low resolution images
lowres_images = torch . randn ( 3 , 3 , 64 , 64 ). cuda () # starting un-resoluted images
images = imagen . sample (
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
],
start_at_unet_number = 2 , # start at unet number 2
start_image_or_video = lowres_images , # pass in low resolution images to be resoluted
cond_scale = 3. )
images . shape # (3, 3, 256, 256) saveおよびloadメソッドを使用すると、いつでもトレーナーと関連するすべての状態を保存およびロードできます。トレーナー内の内部でデバイス メモリ管理が行われているため、 state_dict呼び出しを使用して手動で保存する代わりに、これらのメソッドを使用することをお勧めします。
元。
trainer . save ( './path/to/checkpoint.pt' )
trainer . load ( './path/to/checkpoint.pt' )
trainer . steps # (2,) step number for each of the unets, in this case 2 ImagenTrainerを利用してDataLoaderインスタンスを自動的にトレーニングすることもできます。 images (無条件の場合) またはテキスト ガイド付き生成の場合('images', 'text_embeds')を返すようにDataLoaderを作成するだけです。
元。無条件の訓練
from imagen_pytorch import Unet , Imagen , ImagenTrainer
from imagen_pytorch . data import Dataset
# unets for unconditional imagen
unet = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 1 ,
layer_attns = ( False , False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unet above
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = unet ,
image_sizes = 128 ,
timesteps = 1000
)
trainer = ImagenTrainer (
imagen = imagen ,
split_valid_from_train = True # whether to split the validation dataset from the training
). cuda ()
# instantiate your dataloader, which returns the necessary inputs to the DDPM as tuple in the order of images, text embeddings, then text masks. in this case, only images is returned as it is unconditional training
dataset = Dataset ( '/path/to/training/images' , image_size = 128 )
trainer . add_train_dataset ( dataset , batch_size = 16 )
# working training loop
for i in range ( 200000 ):
loss = trainer . train_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'loss: { loss } ' )
if not ( i % 50 ):
valid_loss = trainer . valid_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'valid loss: { valid_loss } ' )
if not ( i % 100 ) and trainer . is_main : # is_main makes sure this can run in distributed
images = trainer . sample ( batch_size = 1 , return_pil_images = True ) # returns List[Image]
images [ 0 ]. save ( f'./sample- { i // 100 } .png' )のおかげで?高速化、2 ステップで簡単にマルチ GPU トレーニングを行うことができます。
まず、トレーニング スクリプトと同じディレクトリでaccelerate config呼び出す必要があります (たとえば、 train.pyという名前です)。
$ accelerate config次に、単一 GPU の場合のようにpython train.py呼び出す代わりに、加速 CLI を使用します。
$ accelerate launch train.pyそれでおしまい!
Imagen は CLI 経由で直接使用することもできます。
元。
$ imagen configまたは
$ imagen config --path ./configs/config.json設定では、トレーナー、データセット、イメージン設定の設定を変更できます。
Imagen 設定パラメータはここにあります
Elucidated Imagen 設定パラメータはここにあります
Imagen Trainer の設定パラメータはここにあります。
データセット パラメーターには、すべてのデータローダー パラメーターを使用できます。
このコマンドを使用すると、モデルをトレーニングまたはトレーニングを再開できます。
元。
$ imagen trainまたは
$ imagen train --unet 2 --epoches 10次の引数をトレーニング コマンドに渡すことができます。
--configトレーニングに使用する構成ファイルを指定します [デフォルト: ./imagen_config.json]--unetトレーニングする unet のインデックス [デフォルト: 1]--epochesトレーニングするエポックの数 [デフォルト: 50]サンプリングするときは、使用可能な結果が得られるようにチェックポイントですべてのユニットをトレーニングする必要があることに注意してください。
元。
$ imagen sample --model ./path/to/model/checkpoint.pt " a squirrel raiding the birdfeeder "
# image is saved to ./a_squirrel_raiding_the_birdfeeder.pngサンプルコマンドには次の引数を渡すことができます。
--modelサンプリングに使用するモデル ファイルを指定します。--cond_scaleデコーダーのコンディショニング スケール (分類子なしのガイダンス)--load_ema利用可能な場合は EMA バージョンのユニットをロードしますこの機能で保存されたチェックポイントを使用するには、構成クラスImagenConfigおよびElucidatedImagenConfig使用して Imagen インスタンスをインスタンス化するか、CLI 経由でチェックポイントを直接作成する必要があります。
適切なトレーニングを行うには、構成主導のトレーニングをセットアップする必要があるでしょう。
元。
import torch
from imagen_pytorch import ImagenConfig , ElucidatedImagenConfig , ImagenTrainer
# in this example, using elucidated imagen
imagen = ElucidatedImagenConfig (
unets = [
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 )),
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 ))
],
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.5 ,
num_sample_steps = 32
). create ()
trainer = ImagenTrainer ( imagen )
# do your training ...
# then save it
trainer . save ( './checkpoint.pt' )
# you should see a message informing you that ./checkpoint.pt is commandable from the terminal本当はそれくらいシンプルであるべきです
このチェックポイント ファイルを渡すこともでき、誰でも自分のデータの微調整を続けることができます。
from imagen_pytorch import load_imagen_from_checkpoint , ImagenTrainer
imagen = load_imagen_from_checkpoint ( './checkpoint.pt' )
trainer = ImagenTrainer ( imagen )
# continue training / fine-tuning Inpainting は、最近の Repaint ペーパーで定められた配合に従います。 ImagenまたはElucidatedImagenのsample関数にinpaint_imagesとinpaint_masksを渡すだけです。
inpaint_images = torch . randn ( 4 , 3 , 512 , 512 ). cuda () # (batch, channels, height, width)
inpaint_masks = torch . ones (( 4 , 512 , 512 )). bool (). cuda () # (batch, height, width)
inpainted_images = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_images = inpaint_images , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_images # (4, 3, 512, 512)ビデオの場合も同様に、ビデオを.sampleのinpaint_videosキーワードに渡します。修復マスクは、すべてのフレーム(batch, height, width)で同じにすることも、異なるもの(batch, frames, height, width)にすることもできます。
inpaint_videos = torch . randn ( 4 , 3 , 8 , 512 , 512 ). cuda () # (batch, channels, frames, height, width)
inpaint_masks = torch . ones (( 4 , 8 , 512 , 512 )). bool (). cuda () # (batch, frames, height, width)
inpainted_videos = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_videos = inpaint_videos , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_videos # (4, 3, 8, 512, 512) StyleGAN で有名な Tero Karras が新しい論文を書き、その結果は私自身のマシンだけでなく多くの独立した研究者によって裏付けられました。私は、テキストガイドによるカスケード生成に新しい解明された DDPM を使用できるように、 ImagenのバージョンであるElucidatedImagenを作成することにしました。
ElucidatedImagenインポートし、前と同じようにインスタンスをインスタンス化するだけです。ハイパーパラメータは、離散時間および連続時間ガウス拡散の通常のパラメータとは異なり、カスケード内のユニットごとに個別に設定できます。
元。
from imagen_pytorch import ElucidatedImagen
# instantiate your unets ...
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.1 ,
num_sample_steps = ( 64 , 32 ), # number of sample steps - 64 for base unet, 32 for upsampler (just an example, have no clue what the optimal values are)
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, @crowsonkb recommends double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# rest is the same as above このリポジトリでは、テキストガイド付きビデオ合成に関する新しい研究の蓄積も開始します。まず、Jonathan Ho が「Video Diffusion Models」で説明した 3D UNET アーキテクチャを採用します。
更新: Hadrien Reynaud によって動作が確認されました。
元。
import torch
from imagen_pytorch import Unet3D , ElucidatedImagen , ImagenTrainer
unet1 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
unet2 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
# elucidated imagen, which contains the unets above (base unet and super resoluting ones)
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 16 , 32 ),
random_crop_sizes = ( None , 16 ),
temporal_downsample_factor = ( 2 , 1 ), # in this example, the first unet would receive the video temporally downsampled by 2x
num_sample_steps = 10 ,
cond_drop_prob = 0.1 ,
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# mock videos (get a lot of this) and text encodings from large T5
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
]
videos = torch . randn ( 4 , 3 , 10 , 32 , 32 ). cuda () # (batch, channels, time / video frames, height, width)
# feed images into imagen, training each unet in the cascade
# for this example, only training unet 1
trainer = ImagenTrainer ( imagen )
# you can also ignore time when training on video initially, shown to improve results in video-ddpm paper. eventually will make the 3d unet trainable with either images or video. research shows it is essential (with current data regimes) to train first on text-to-image. probably won't be true in another decade. all big data becomes small data
trainer ( videos , texts = texts , unet_number = 1 , ignore_time = False )
trainer . update ( unet_number = 1 )
videos = trainer . sample ( texts = texts , video_frames = 20 ) # extrapolating to 20 frames from training on 10 frames
videos . shape # (4, 3, 20, 32, 32)最初にテキストと画像のペアでトレーニングすることもできます。 Unet3D 、それを単一フレームのビデオに自動的に変換し、1 次元の畳み込みであれ、時間にわたる因果的注意であれ、時間コンポーネントなしで (自動的にignore_time = Trueに設定することで) 学習します。
これは、すべての大手人工知能研究所 (Brain、MetaAI、Bytedance) が採用している現在のアプローチです。
Imagen は、Classifier Free Guide と呼ばれるアルゴリズムを使用します。サンプリングするときは、コンディショニング (この場合はテキスト) に1.0より大きいスケールを適用します。
研究者 Netruk44 は、 5-10最適であるが、 10超えると限界があると報告しています。
trainer . sample ( texts = [
'a cloud in the shape of a roman gladiator'
], cond_scale = 5. ) # <-- cond_scale is the conditioning scale, needs to be greater than 1.0 to be better than average現時点ではありませんが、早ければ年内にトレーニングを受けてオープンソース化される可能性があります。参加したい場合は、Laion の人工ニューラル ネットワーク トレーナーのコミュニティに参加し (Discord リンクは上記の Readme にあります)、コラボレーションを開始できます。
今日から独自のモデルのトレーニングを開始すべき理由がさらにわかります。このテクノロジーが少数のエリートの手に渡ることは絶対に避けるべきです。このリポジトリによって、必要なコンピューティングを見つけて、独自に厳選されたデータセットで拡張するだけの作業が軽減されることを願っています。
何でも! MITライセンスを取得しています。言い換えれば、自分の研究のために自由にコピー/ペーストし、思いつく限りのあらゆるモダリティに合わせてリミックスすることができます。利益のため、科学のため、または単に目の前で神聖な何かが解明されるのを目撃して個人的な喜びを満たすために、素晴らしいモデルをトレーニングしてみませんか。
心エコー図合成 [コード]
SOTA Hi-Cコンタクトマトリックス合成 [コード]
フロアプランの生成
超高解像度の病理組織スライド
合成腹腔鏡画像
メタマテリアルの設計
Flavio Schneider によるオーディオの拡散
Ryan O. の Mini Imagen | AssemblyAI の記事
T5 の小さいテキストの埋め込みに ハグフェイス トランスフォーマーを使用する
動的しきい値処理を追加する
動的しきい値処理 DALLE2 とビデオ拡散リポジトリも追加
T5-large を設定できるようにします (そしておそらくハグフェイス トランスフォーマーを受け入れるための小規模な工場の方法も可能です)。
付録の疑似コードで低解像度ノイズ レベルを追加し、推論時に行われるこのスイープが何であるかを理解します。
DALLE2 からのトレーニング コードを移植
unet ごとに異なるノイズ スケジュールを使用できる必要がある (ベースにはコサインが使用されましたが、SR には線形が使用されました)
マスター構成可能な unet を 1 つ作成するだけです
完全な resnet ブロック (biggan からインスピレーションを得た? ただし groupnorm を使用) - 完全な自己注意
完全なコンディショニング埋め込みブロック (アテンション、フィルムなど、完全に構成可能にする)
アテンションプーリングの代わりにhttps://github.com/lucidrains/flamingo-pytorchのpercepter-resamplerの使用を検討してください。
クロスアテンションとフィルムに加えて、アテンションプーリングオプションを追加します
各ユニットのウォームアップを伴うオプションのコサイン減衰スケジュールをトレーナーに追加します
離散化ではなく連続タイムステップに切り替えます。それがすべての段階で使用されているようです - まず、変分 ddpm 論文 https://openreview.net/forum?id=2LdBqxc1Yv から線形ノイズ スケジュールのケースを理解します。
アルファ コサイン ノイズ スケジュールの log(snr) を計算します。
T5encoder のみが使用されるため、トランスフォーマーの警告を抑制します
フルアテンションを使用できないレイヤーでリニアアテンションを使用する設定を許可します
それが私がローカルで作業しているものなので、連続時間の場合に非フーリエ化条件を使用するように単位を強制します(オプションのレイヤーノルムを使用してMLPにログ(SNR)を渡すだけです)
学習された分散を削除しました
連続時間の p2 損失重み付けを追加する
カスケード ddpm がテキスト条件なしでトレーニングできることを確認し、連続時間と離散時間の両方のガウス拡散が機能することを確認します。
線形注意の qkv 投影でプライマーの深さ方向の変換を使用します (または投影前にトークン シフトを使用します) - 線形注意でうまく機能するように見えるため、bayesformer によって提案された新しいドロップアウトも使用します
UNET デコーダーでスキップ層の励起を探索する
統合を加速する
CLI ツールを構築し、イメージを 1 行で生成
加速によって生じた問題をすべて解決する
リペイントペーパーのリサンプラーを使用して修復機能を追加 https://arxiv.org/abs/2201.09865
フォルダーを基盤とした単純なチェックポイント システムを構築する
すべてのアップサンプル ブロックの出力からのスキップ接続を追加します。unet squared Paper および一部の以前の unet 作品で使用されます。
Romain @rom1504 が推奨する fsspec を追加し、クラウド/ローカル ファイル システムに依存しないチェックポイントの永続性を実現します。
https://github.com/fsspec/gcsfs で gcs の永続性をテストします。
Ho のビデオ DDPM 論文のように軸方向の時間注意を使用して、ビデオ生成に拡張します。
解明された画像を任意の形状に一般化できるようにする
imagen を任意の形状に一般化できるようにする
動的な位置バイアスを追加して、ビデオ時間全体にわたる最適な長さの外挿を実現します。
時間の外挿を試みるため、ビデオ フレームをサンプル関数に移動します。
null キー/値への注意バイアスは、頭の次元の学習されたスカラーである必要があります
ビット拡散ペーパーからセルフコンディショニングを追加します。すでに ddpm-pytorch でコード化されています。
imagen ビデオ ペーパーから v-parameterization (https://arxiv.org/abs/2202.00512) を追加します。唯一の新しい点です。
make-a-video (https://makeavideo.studio/) から学んだことをすべて組み込む
トレーニング用の CLI ツールを構築し、設定ファイルからトレーニングを再開します
特定の段階で時間的補間を可能にする
時間補間が修復で機能することを確認する
すべての補間モードをカスタマイズできることを確認してください (一部の研究者はトリリニアの方が良い結果を発見しています)
imagen-video : ビデオの前の (そして場合によっては将来の) フレームを条件付けできるようにします。そのシナリオでは時間を無視することは許可されるべきではありません
ビデオフレームを調整するために一時的なダウン/アップサンプリングを自動的に処理するようにしますが、それをオフにするオプションも許可します
ビデオで修復が機能することを確認する
ビデオの修復マスクがフレームごとにカスタマイズできることを確認してください
フラッシュアテンションを追加する
cogvideo を読み直し、フレーム レート コンディショニングをどのように使用できるかを理解する
unet3d のセルフ アテンション レイヤーに注意の専門知識を導入する
NUWA の 3D 畳み込みアテンションの導入を検討してください
時間的注意ブロック内のtransformer-xlメモリを考慮する
過去の時間に注意を向けるための知覚者的アプローチを検討する
アテンション中のフレームドロップアウトを抑制し、正則化効果とトレーニング時間の短縮を両立
Frank Wood の主張 https://github.com/lucidrains/flexible-diffusion-modeling-videos-pytorch を調査し、階層的サンプリング手法を追加するか、その欠陥について人々に知らせてください。
研究者がテキストからビデオに分岐するための 1 行のトレーニング可能なベースラインとして、挑戦的な移動リスト (ディストラクター オブジェクトを含む) を提供します。
memmap 埋め込みへのテキストのプリエンコード
古いエポックスタイルに基づいてデータローダーイテレータを作成でき、シャッフルなども設定できます
(モデル上のすべてのキーワード引数を forward にする代わりに) 引数を渡すこともできます。
メモリの負担を軽減するために、3D UNET の Revnet から可逆ブロックを取り込みます。
超解像度ネットワークのみをトレーニングする機能を追加
dpm-solver を読んで、連続時間ガウス拡散に適用できるかどうかを確認します。
ビデオ フレームを任意の絶対時間で調整できるようにします (時間的注意中に RPE を計算します)。
夢のブースの微調整に対応
テキストの反転を追加する
imagen のインスタンス化時に抽出されるクリーンアップ自己調整
最終的な Dreambooth が imagen-video で動作することを確認する
ビデオ拡散のためのフレームレート調整を追加
プロンプトとしてビデオ フレームを同時に条件付けできることと、すべてのフレームにわたって画像を条件付けできることを確認します。
一貫性モデルからの蒸留技術をテストして追加する
@inproceedings { Saharia2022PhotorealisticTD ,
title = { Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding } ,
author = { Chitwan Saharia and William Chan and Saurabh Saxena and Lala Li and Jay Whang and Emily L. Denton and Seyed Kamyar Seyed Ghasemipour and Burcu Karagol Ayan and Seyedeh Sara Mahdavi and Raphael Gontijo Lopes and Tim Salimans and Jonathan Ho and David Fleet and Mohammad Norouzi } ,
year = { 2022 }
} @article { Alayrac2022Flamingo ,
title = { Flamingo: a Visual Language Model for Few-Shot Learning } ,
author = { Jean-Baptiste Alayrac et al } ,
year = { 2022 }
} @inproceedings { Sankararaman2022BayesFormerTW ,
title = { BayesFormer: Transformer with Uncertainty Estimation } ,
author = { Karthik Abinav Sankararaman and Sinong Wang and Han Fang } ,
year = { 2022 }
} @article { So2021PrimerSF ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Ma'nke and Hanxiao Liu and Zihang Dai and Noam M. Shazeer and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2109.08668 }
} @misc { cao2020global ,
title = { Global Context Networks } ,
author = { Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu } ,
year = { 2020 } ,
eprint = { 2012.13375 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Karras2022ElucidatingTD ,
title = { Elucidating the Design Space of Diffusion-Based Generative Models } ,
author = { Tero Karras and Miika Aittala and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2206.00364 }
} @inproceedings { NEURIPS2020_4c5bcfec ,
author = { Ho, Jonathan and Jain, Ajay and Abbeel, Pieter } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin } ,
pages = { 6840--6851 } ,
publisher = { Curran Associates, Inc. } ,
title = { Denoising Diffusion Probabilistic Models } ,
url = { https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf } ,
volume = { 33 } ,
year = { 2020 }
} @article { Lugmayr2022RePaintIU ,
title = { RePaint: Inpainting using Denoising Diffusion Probabilistic Models } ,
author = { Andreas Lugmayr and Martin Danelljan and Andr{'e}s Romero and Fisher Yu and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2201.09865 }
} @misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { chen2022analog ,
title = { Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning } ,
author = { Ting Chen and Ruixiang Zhang and Geoffrey Hinton } ,
year = { 2022 } ,
eprint = { 2208.04202 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @article { Sunkara2022NoMS ,
title = { No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects } ,
author = { Raja Sunkara and Tie Luo } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.03641 }
} @article { Salimans2022ProgressiveDF ,
title = { Progressive Distillation for Fast Sampling of Diffusion Models } ,
author = { Tim Salimans and Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.00512 }
} @article { Ho2022ImagenVH ,
title = { Imagen Video: High Definition Video Generation with Diffusion Models } ,
author = { Jonathan Ho and William Chan and Chitwan Saharia and Jay Whang and Ruiqi Gao and Alexey A. Gritsenko and Diederik P. Kingma and Ben Poole and Mohammad Norouzi and David J. Fleet and Tim Salimans } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02303 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Hang2023EfficientDT ,
title = { Efficient Diffusion Training via Min-SNR Weighting Strategy } ,
author = { Tiankai Hang and Shuyang Gu and Chen Li and Jianmin Bao and Dong Chen and Han Hu and Xin Geng and Baining Guo } ,
year = { 2023 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
}

