eye in the sky
1.0.0
衛星画像分類、InterIIT Techmeet 2018、IIT ボンベイ。
チーム: マニディープ・コラ、アニケット・マンドル、アプールヴァ・クマール
このリポジトリには、U-Net という 2 つのアルゴリズムの実装が含まれています。生物医学画像セグメンテーション用の畳み込みネットワークと、衛星画像の分類の問題のために修正されたピラミッド シーン解析ネットワークです。
main_unet.py : グラウンド トゥルースのエンコードを含む、U-Net アーキテクチャでアルゴリズムをトレーニングするための Python コード。unet.py : U-Net レイヤーの実装が含まれています。test_unet.py : テスト、精度の計算、トレーニングと検証のための混同行列の計算、およびトレーニング、検証、テスト画像に対する U-Net モデルによる予測の保存のためのコード。Inter-IIT-CSRE : すべてのトレーニング、検証、広告テスト データが含まれます。Comparison_Test.pdf : テスト データとそのデータに対する U-Net モデルの予測を並べて比較します。train_predictions : トレーニング画像と検証画像に対する U-Net モデルの予測。plots : U-Net アーキテクチャのトレーニングと検証のための精度と損失のプロット。Test_images 、 Test_outputs : U-Net モデルによるテスト イメージとその予測が含まれます。class_masks 、 compare_pred_to_gt 、 images_for_doc : ドキュメント用のいくつかのイメージが含まれています。PSPNet : 衛星画像分類に対する PSPNet アルゴリズムの実装のためのトレーニング ファイルが含まれています。 リポジトリのクローンを作成し、現在の作業ディレクトリをクローン作成したディレクトリに変更します。 train_predictionsおよびtest_outputsという名前のフォルダーを作成し、モデルの予測出力をトレーニング イメージとテスト イメージに保存します (リポジトリにはこれらのフォルダーが既に含まれているため、現時点では必要ありません)。
$ git clone https://github.com/manideep2510/eye-in-the-sky.git
$ cd eye-in-the-sky
$ mkdir train_predictions
$ mkdir test_outputs
U-Net モデルをトレーニングして重みを保存するには、以下のコマンドを実行します。
$ python3 main_unet.py
U-Net モデルをテストするには、精度の計算、トレーニングと検証のための混同行列の計算、およびトレーニング、検証、テスト画像に対するモデルによる予測の保存を行います。
$ python3 test_unet.py
コードの実行中に、 xrange is not definedエラーが発生する可能性があります。このエラーは、コード内のエラーが原因ではなく、データセットを読み取るために使用したlibtiffという名前の Python パッケージが最新ではないことが原因です (パッケージのソース コードの一部は python2 にあり、一部は python3 にあります)。画像は .tif 形式です。 openCV や PIL などの他のライブラリは、4 チャネル .tif イメージの読み取りを適切にサポートしていないため、イメージを読み取るために使用できませんでした。
このエラーは、 libtiffライブラリのソース コードを編集することで解決できます。
エラーが発生したライブラリのソース コード内のファイルに移動し (エラーが表示されているときにファイル名がターミナルに表示されます)、ファイル内のすべてのxrange() (python2) 関数をrange() (Python3)。
ここでは、ユーザーが最初からトレーニングする必要がないように、適切な事前トレーニング済みのウェイトをいくつか提供しています。
| 説明 | タスク | データセット | モデル |
|---|---|---|---|
| UNet アーキテクチャ | 衛星画像の分類 | IITB データセット ( Inter-IIT-CSREフォルダーを参照) | ダウンロード (.h5) |
事前トレーニングされた重みを使用するには、必要に応じて、 test_unet.pyに記載されている .h5 (重みファイル) ファイルの名前を、ダウンロードした重みファイルの名前と一致するように変更します。
さあ、話し合いましょう
1. このプロジェクトの内容
2. 私たちが使用し、実験したアーキテクチャと
3. プロジェクトで使用したいくつかの新しいトレーニング戦略
リモート センシングは、通常は航空機や衛星など、離れた場所から物体や領域に関する情報を取得する科学です。
私たちは衛星画像の分類の問題をセマンティック セグメンテーションの問題として認識し、これに取り組むために深層学習でセマンティック セグメンテーション アルゴリズムを構築しました。
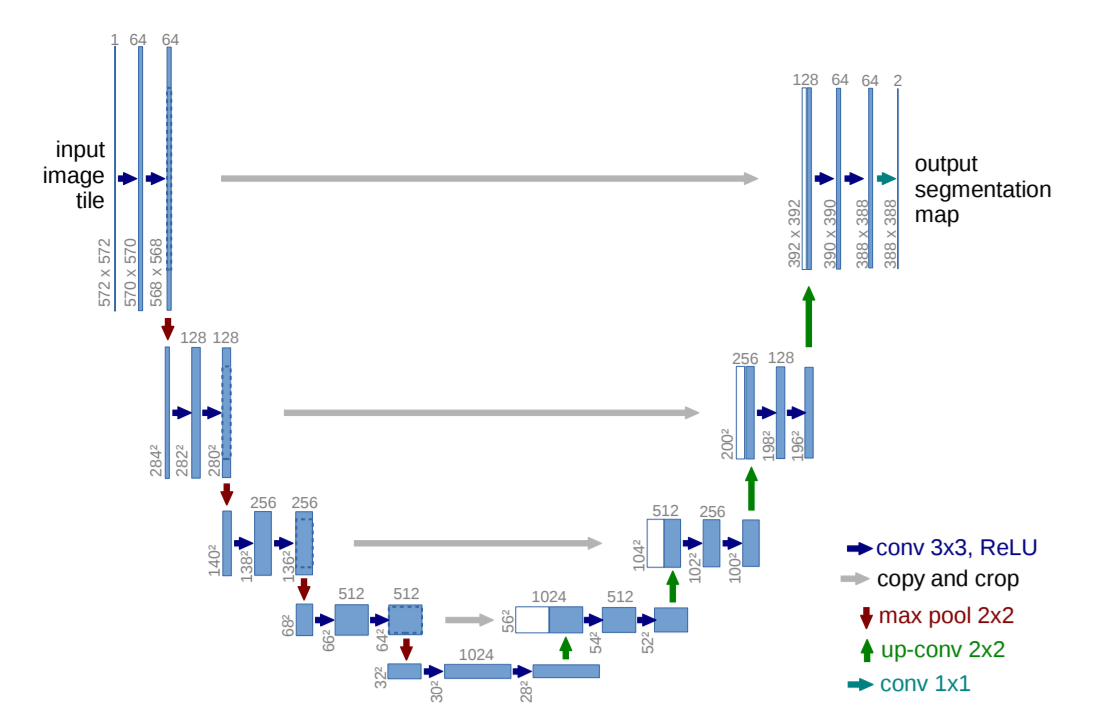
U-Net: 生物医学画像セグメンテーションのための畳み込みネットワーク
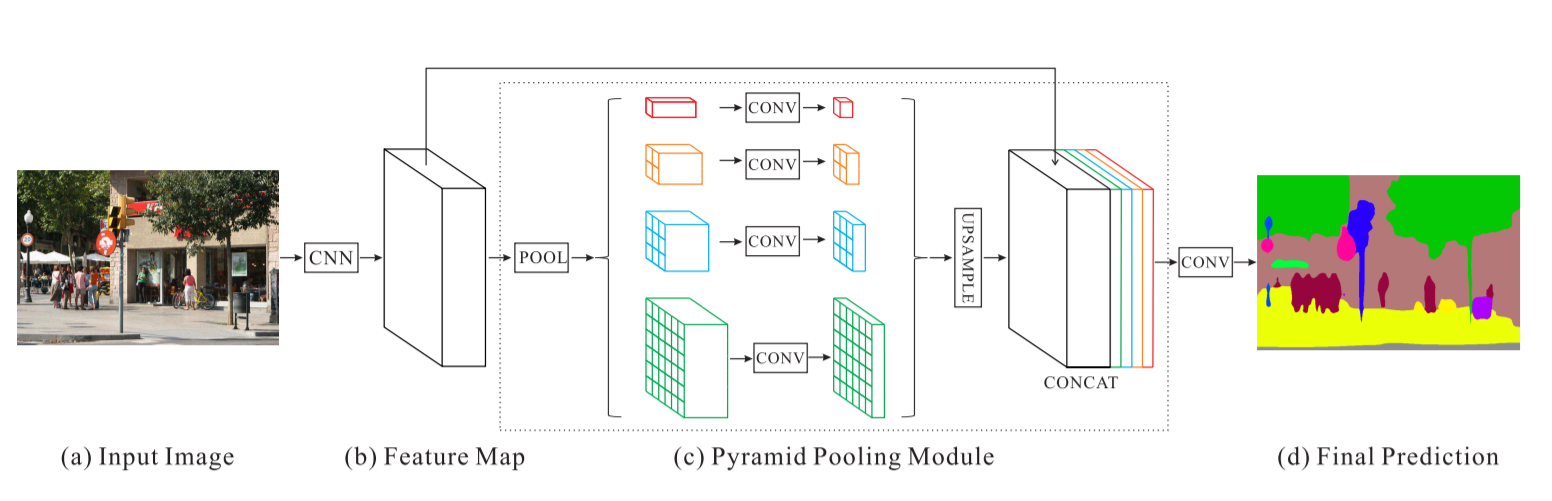
ピラミッドシーン解析ネットワーク - PSPNet
提供されるグラウンド トゥルースは 3 チャネル RGB 画像です。現在のデータセットでは、分類されるクラスが 9 つあるため、グラウンド トゥルースには 9 つの一意の RGB 値しかありません。これらの 9 つの異なる RGB 値はワンホット エンコードされ、各チャネルが特定のクラスを表す 9 チャネル エンコードされたグラウンド トゥルースを生成します。
以下はエンコードスキームです
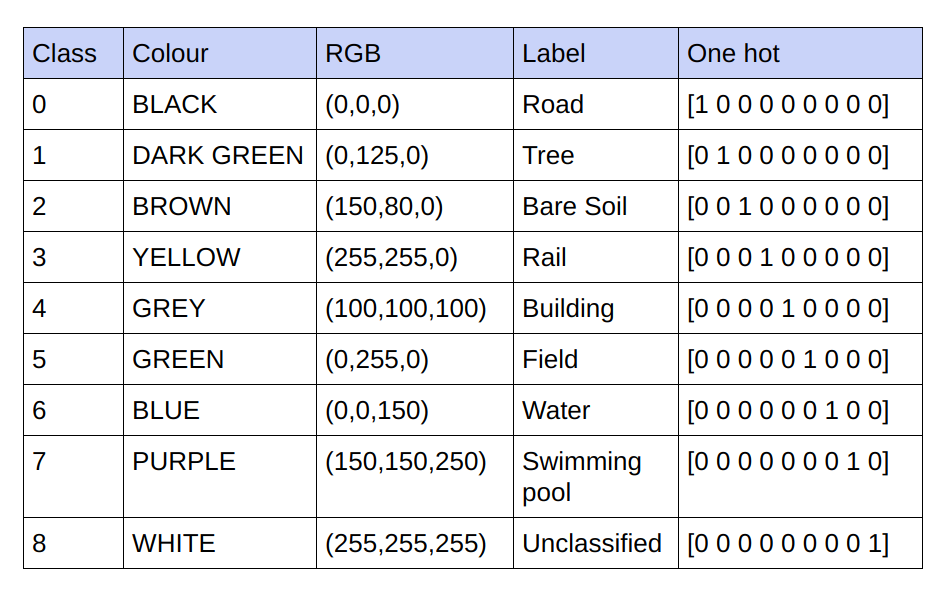
エンコードされたグラウンド トゥルース内の各チャネルをクラスとして実現

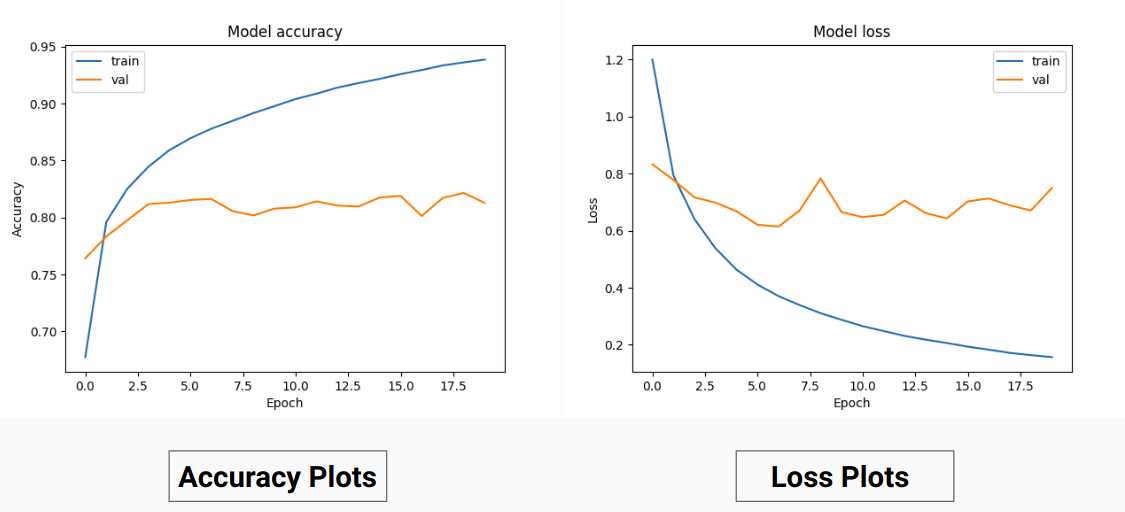
したがって、グラウンド トゥルースの RGB 値でトレーニングする代わりに、それらをさまざまなクラスのワンホット値に変換しました。このアプローチにより、RGB グラウンド トゥルース値をトレーニングに使用した場合の検証精度 71%、トレーニング精度 65% と比較して、検証精度 85%、トレーニング精度 92% が得られました。
これは、トレーニング データが効果的な正規化手法として機能するため、トレーニング データのグランド トゥルースの分散と平均が減少するためである可能性があります。このトレーニング手法のパフォーマンスが向上しているのは、モデルがクラスを示す 9 つの特徴マップを含む出力を提供しているためでもあります。つまり、このトレーニング手法は、モデルが 9 つのクラスのそれぞれである程度個別にトレーニングされているかのように動作します(ただし、ここでは明らかに、特定のクラスに対応する 1 つのチャネルの予測が他のチャネルに依存します) 。
PSPNet による衛星画像分類の結果:
トレーニングの精度 - 49% 検証の精度 - 60%
理由:
ユーネット:
修正された U-Net:
トレーニングと検証にはInter-IIT-CSRE/The-Eye-in-the-Sky-datasetフォルダー内の 14 個の「.tif」イメージを使用しました。
トレーニングにはデータセット内の最初の 13 個の画像を使用し、検証には 14 番目の画像を使用しました。
satフォルダー内の各衛星画像には、R (バンド 1)、G (バンド 2)、B (バンド 3)、NIR (バンド 4) の 4 つのチャンネルが含まれています。
gtディレクトリ内のグラウンド トゥルース画像は RGB 画像であり、道路、建物、樹木、草、裸地、水、鉄道、プールの 8 つのクラスを示しています。
検証セットとして 1 つの画像 (14 番目の画像) のみを考慮した理由は、それがデータセット内で最も小さい画像の 1 つであり、データセットが非常に小さいため、トレーニング用に残すデータを少なくしたくないためです。私たちが検討した検証セット (14 番目の画像) には、かなり高いトレーニング精度を持つ 3 つのクラス (裸の土壌、レール、水泳投票) が含まれていません。すべてのクラスを含む画像を考慮していれば、検証精度はさらに向上したでしょう (データセット内の画像にすべてのクラスが含まれていないため、すべての画像に少なくとも 1 つのクラスが欠落しています)。
ストライドクロップ:
指定された高解像度画像から十分なトレーニング データを取得するには、U-Net 実装の約 3,100 万のパラメーターを持つ分類器をトレーニングするためにトリミングが必要です。 64x64 のトリミング サイズでは、個々のクラスが過小表現されており、オブジェクトのジオメトリと連続性が失われ、畳み込みの視野が減少します。
128x128 ピクセルのトリミング ウィンドウを 32 のストライドで使用すると、15887 個のトレーニング 414 個の検証画像の結果が得られます。
画像の寸法:
トリミング前に、トレーニング画像の寸法は、ストライドのトリミング中に便利なようにストライドの倍数に変換されます。
いいえの場合。クロップの数は、最初にゼロ パディングを試した画像サイズの倍数ではありません。パディングを追加すると、トレーニング画像とテスト画像に黒ピクセルの形で不要なアーティファクトが追加され、偽のデータと画像境界でのトレーニングにつながることがわかりました。
あるいは、画像の右端と下部に余分なピクセルを追加することで、画像の寸法を正しく変更しました。そこで、画像の左端から右端までの差を埋め込み、画像の上部と下部についても同様に埋め込みました。
トレーニング例 1: トレーニング データからの画像「2.tif」
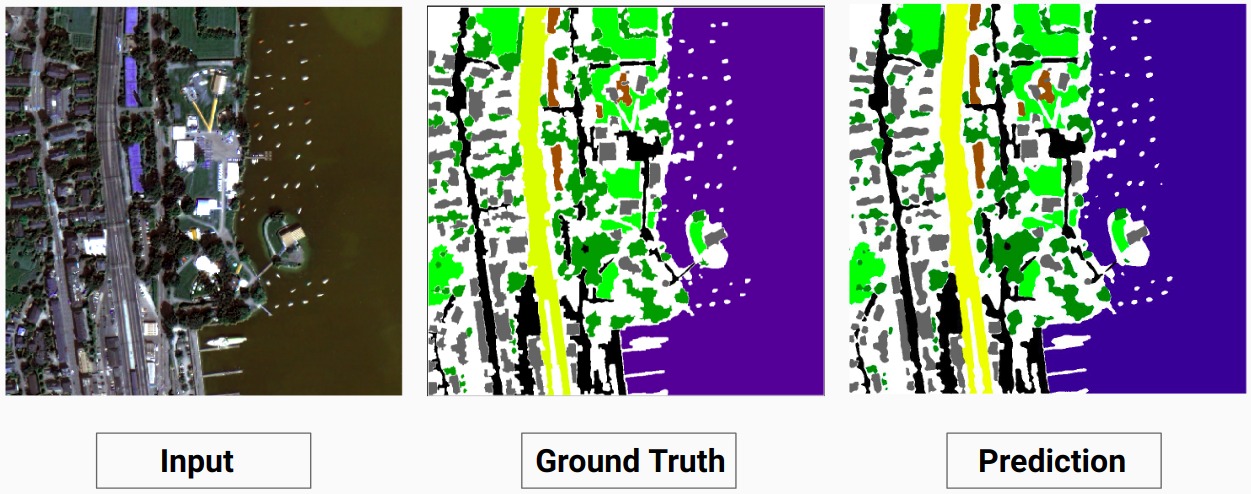
トレーニング例 2: トレーニング データからの画像「4.tif」
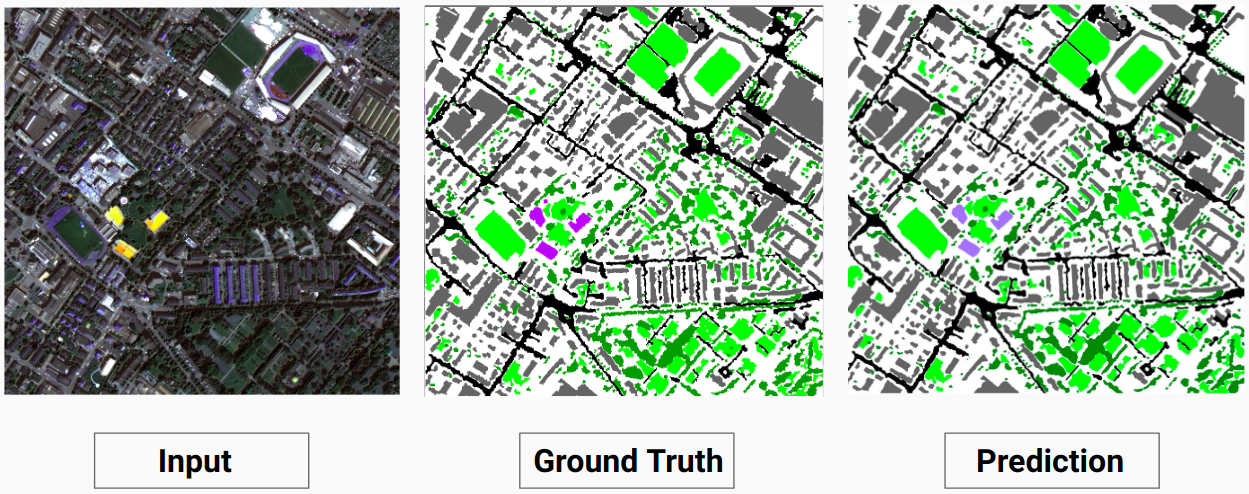
検証例: データセットからの画像「14.tif」

私たちのモデルは、人間のアノテーターでは予測できなかったいくつかのクラスを予測できます。画像内の識別できないクラスは、ヒューマン アノテーターによって白いピクセルとしてラベル付けされます。私たちのモデルは、これらの白いピクセルの一部を何らかのクラスとして正しく予測できますが、モデルによって白いピクセルが別のクラスとしてみなされるため、全体的な精度が低下します。
ここで、モデルは白いピクセルを建物として正確に予測でき、入力画像ではっきりと見ることができます。
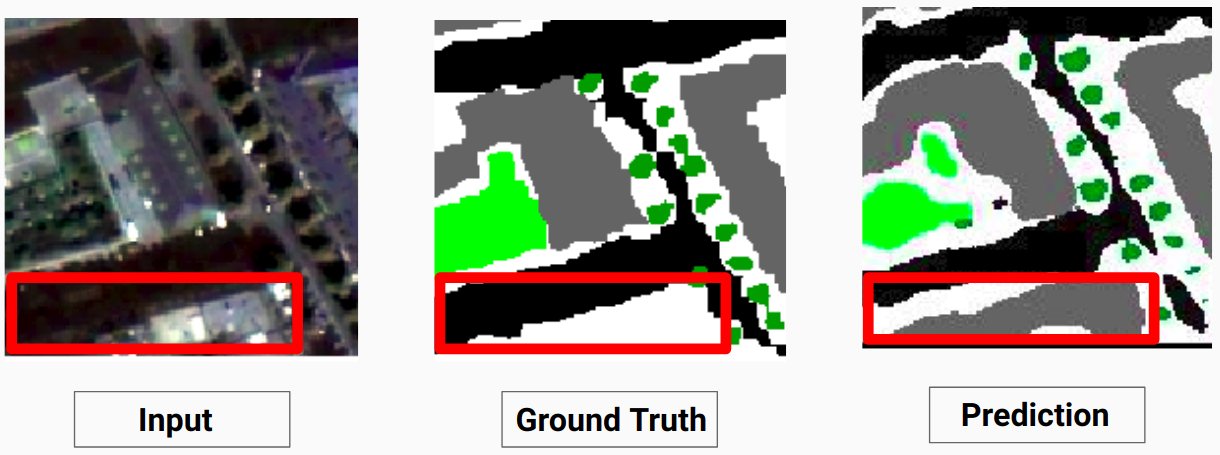
テスト画像とモデルによる予測出力の比較については、 Comparison_Test.pdf確認してください。
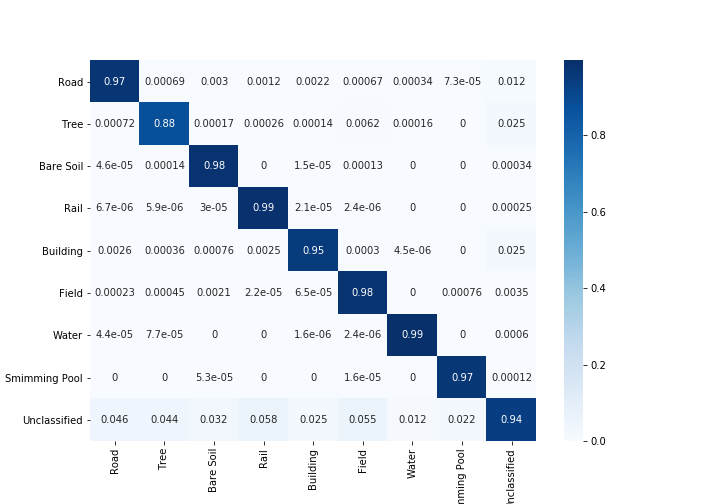
未分類のピクセルを考慮した場合と考慮しない場合のカッパ係数
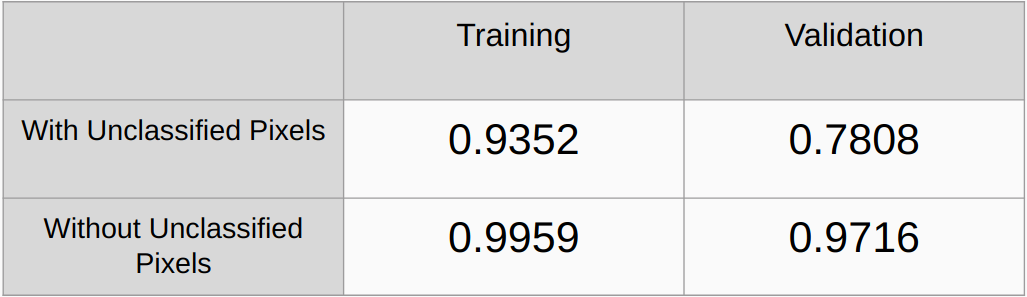
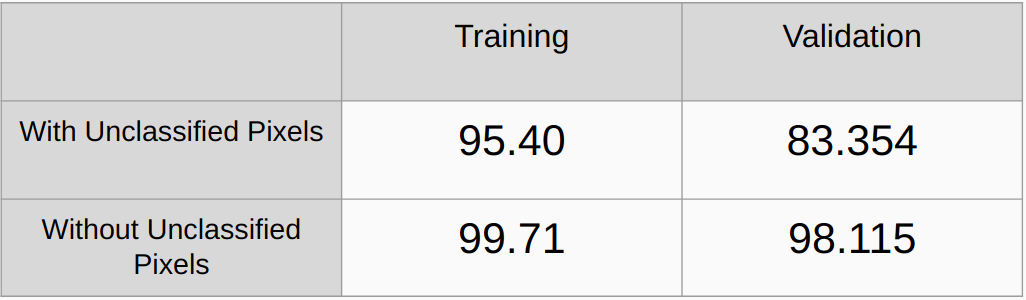
未分類のピクセルを考慮した場合と考慮しない場合の全体的な精度
L2正則化やドループアウトなどの正則化メソッドを追加してパフォーマンスを確認する必要がある
手動で RGB 値を見つけるのではなく、グラウンド トゥルース内のすべての一意の RGB 値を自動的に検出し、それらをワンホット エンコードするアルゴリズムを実装します。
[1] U-Net: 生物医学画像セグメンテーションのための畳み込みネットワーク、Olaf Ronneberger、Philipp Fischer、Thomas Brox
[2] ピラミッド シーン解析ネットワーク、Hengshuang Zhao、Jianping Shi、Xiaojuan Qi、Xiaogang Wang、Jiaya Jia
[3] 深層学習によるセマンティック セグメンテーションの 2017 年ガイド、Sasank Chilamkurthy


