PaLM rlhf pytorch
0.3.9
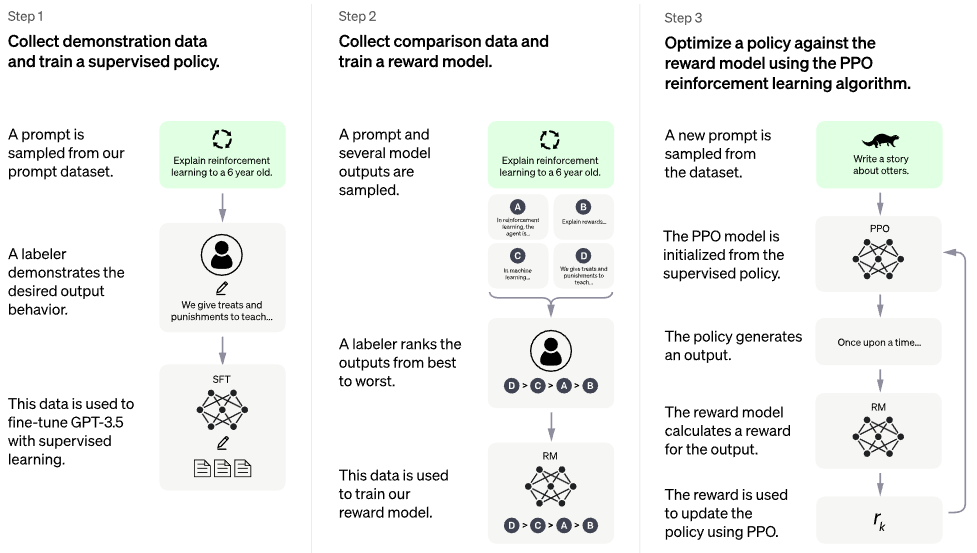
公式Chatgptブログ投稿
PaLM アーキテクチャ上での RLHF (ヒューマン フィードバックによる強化学習) の実装。レトロ風に検索機能も追加するかも知れません
ChatGPT のようなものを公開して複製することに興味がある場合は、Laion への参加を検討してください。
後継となる可能性のあるもの: Direct Preference Optimization - このリポジトリ内のすべてのコードは、バイナリ クロス エントロピー損失、< 5 loc になります。報酬モデルと PPO についてはこれくらいです
トレーニング済みのモデルはありません。これは船と全体のマップのみです。高次元パラメータ空間の正しいポイントに到達するには、依然として数百万ドルの計算とデータが必要です。それでも、実際にその地点まで激動の時代を経て船を導くプロの船員(Stable Diffusionで有名なロビン・ロンバックのような)が必要です。
CarperAI は、ChatGPT のリリースに先立つ何ヶ月もの間、大規模言語モデル用の RLHF フレームワークに取り組んできました。
ヤニック・キルチャー氏はオープンソースの実装にも取り組んでいます
AI コーヒーブレイク with レティシア |コードエンポリアム |コードエンポリアムパート2
Stability.ai は最先端の人工知能研究に取り組むための寛大なスポンサーシップを提供しています
? Hugging Face と CarperAI はブログ投稿「Illustrated Reinforcement Learning from Human Feedback (RLHF)」の執筆に協力し、前者は加速ライブラリにも協力しました
@kisseternity と @taynoel84 (コードレビューとバグ発見)
Enrico 氏、Pytorch 2.0 から Flash Attendant を統合
$ pip install palm-rlhf-pytorch他の自己回帰変換器と同様に、最初にPaLM訓練します
import torch
from palm_rlhf_pytorch import PaLM
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
flash_attn = True # https://arxiv.org/abs/2205.14135
). cuda ()
seq = torch . randint ( 0 , 20000 , ( 1 , 2048 )). cuda ()
loss = palm ( seq , return_loss = True )
loss . backward ()
# after much training, you can now generate sequences
generated = palm . generate ( 2048 ) # (1, 2048)次に、厳選された人間のフィードバックを使用して報酬モデルをトレーニングします。元の論文では、事前学習済みのトランスフォーマーから過剰適合せずに報酬モデルを微調整することはできませんでしたが、まだ未公開の研究であるため、とにかくLoRAで微調整するオプションを与えました。
import torch
from palm_rlhf_pytorch import PaLM , RewardModel
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
causal = False
)
reward_model = RewardModel (
palm ,
num_binned_output = 5 # say rating from 1 to 5
). cuda ()
# mock data
seq = torch . randint ( 0 , 20000 , ( 1 , 1024 )). cuda ()
prompt_mask = torch . zeros ( 1 , 1024 ). bool (). cuda () # which part of the sequence is prompt, which part is response
labels = torch . randint ( 0 , 5 , ( 1 ,)). cuda ()
# train
loss = reward_model ( seq , prompt_mask = prompt_mask , labels = labels )
loss . backward ()
# after much training
reward = reward_model ( seq , prompt_mask = prompt_mask )次に、トランスフォーマーと報酬モデルをRLHFTrainerに渡します。
import torch
from palm_rlhf_pytorch import PaLM , RewardModel , RLHFTrainer
# load your pretrained palm
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12
). cuda ()
palm . load ( './path/to/pretrained/palm.pt' )
# load your pretrained reward model
reward_model = RewardModel (
palm ,
num_binned_output = 5
). cuda ()
reward_model . load ( './path/to/pretrained/reward_model.pt' )
# ready your list of prompts for reinforcement learning
prompts = torch . randint ( 0 , 256 , ( 50000 , 512 )). cuda () # 50k prompts
# pass it all to the trainer and train
trainer = RLHFTrainer (
palm = palm ,
reward_model = reward_model ,
prompt_token_ids = prompts
)
trainer . train ( num_episodes = 50000 )
# then, if it succeeded...
# generate say 10 samples and use the reward model to return the best one
answer = trainer . generate ( 2048 , prompt = prompts [ 0 ], num_samples = 10 ) # (<= 2048,) クローンベーストランスと批評家用の別のローラ
非 LoRA ベースの微調整も可能
マスクされたバージョンを使用できるように再実行を正規化します。トークンごとの報酬/値を使用する人がいるかどうかはわかりませんが、実装するのは良い方法です。
最善の注意を払う
ハグフェイスアクセラレーションを追加し、wandb インストルメンテーションをテストします
RL 分野がまだ進歩していると仮定して、PPO 用の最新の SOTA が何かを知るために文献を検索してください。
事前にトレーニングされた感情ネットワークを報酬モデルとして使用してシステムをテストする
PPO 内のメモリを memmapped numpy ファイルに書き込みます
人間のフィードバックがボトルネックになっている場合でも、可変長のプロンプトを使用してサンプリングを機能させる
事前トレーニングされている場合を想定して、アクターまたは批評家のいずれかでのみ最後から 2 番目の N レイヤーの微調整を許可します。
Letitia のビデオを考慮して、Sparrow からのいくつかの学習ポイントを組み込む
人間のフィードバックを収集するための django + htmx を使用したシンプルな Web インターフェイス
RLAIFを検討する
@article { Stiennon2020LearningTS ,
title = { Learning to summarize from human feedback } ,
author = { Nisan Stiennon and Long Ouyang and Jeff Wu and Daniel M. Ziegler and Ryan J. Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul Christiano } ,
journal = { ArXiv } ,
year = { 2020 } ,
volume = { abs/2009.01325 }
} @inproceedings { Chowdhery2022PaLMSL ,
title = { PaLM: Scaling Language Modeling with Pathways } ,
author = {Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam M. Shazeer and Vinodkumar Prabhakaran and Emily Reif and Nan Du and Benton C. Hutchinson and Reiner Pope and James Bradbury and Jacob Austin and Michael Isard and Guy Gur-Ari and Pengcheng Yin and Toju Duke and Anselm Levskaya and Sanjay Ghemawat and Sunipa Dev and Henryk Michalewski and Xavier Garc{'i}a and Vedant Misra and Kevin Robinson and Liam Fedus and Denny Zhou and Daphne Ippolito and David Luan and Hyeontaek Lim and Barret Zoph and Alexander Spiridonov and Ryan Sepassi and David Dohan and Shivani Agrawal and Mark Omernick and Andrew M. Dai and Thanumalayan Sankaranarayana Pillai and Marie Pellat and Aitor Lewkowycz and Erica Oliveira Moreira and Rewon Child and Oleksandr Polozov and Katherine Lee and Zongwei Zhou and Xuezhi Wang and Brennan Saeta and Mark Diaz and Orhan Firat and Michele Catasta and Jason Wei and Kathleen S. Meier-Hellstern and Douglas Eck and Jeff Dean and Slav Petrov and Noah Fiedel},
year = { 2022 }
} @article { Hu2021LoRALA ,
title = { LoRA: Low-Rank Adaptation of Large Language Models } ,
author = { Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09685 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Yuan2024FreePR ,
title = { Free Process Rewards without Process Labels } ,
author = { Lifan Yuan and Wendi Li and Huayu Chen and Ganqu Cui and Ning Ding and Kaiyan Zhang and Bowen Zhou and Zhiyuan Liu and Hao Peng } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:274445748 }
}

