linformer pytorch
version
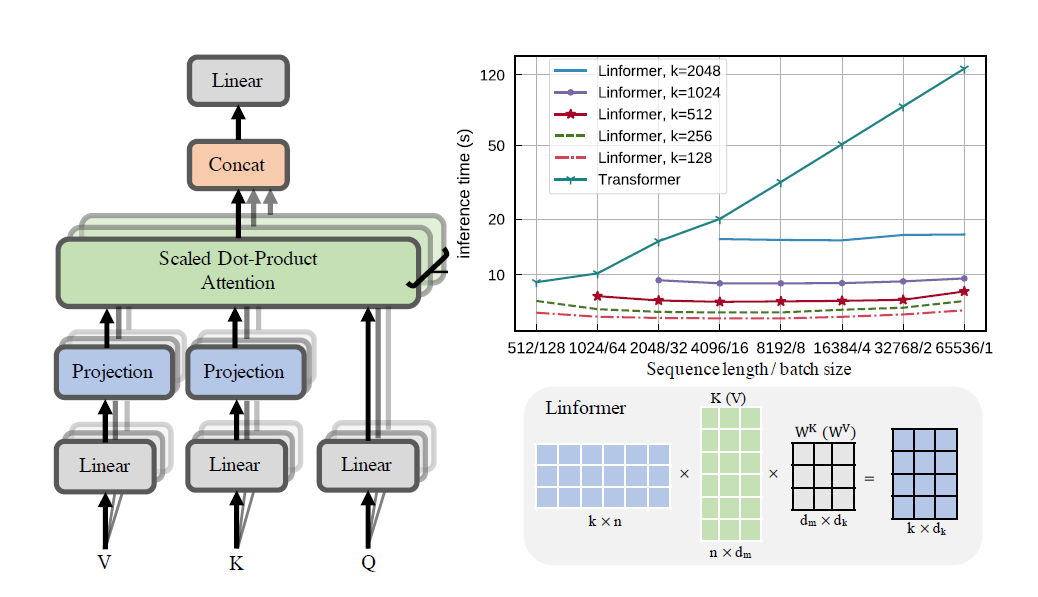
リンフォーマー論文の実践的な実装。これは、n の線形複雑さのみに注目し、最新のハードウェアで非常に長いシーケンス長 (1mil+) に対応できるようにします。
このリポジトリは、エンコーダーとデコーダー モジュールを備えた、Attending Is All You Need スタイルのトランスフォーマーです。ここでの目新しい点は、注意を直線的に向けることができることです。使用方法は以下をご覧ください。
これは wikitext-2 で検証中です。現時点では、Sinkhorn Transformer などの他のスパース アテンション メカニズムと同じレベルで動作しますが、最適なハイパーパラメータを見つける必要があります。
ヘッドの可視化も可能です。詳細については、以下の「視覚化」セクションをご覧ください。
私はその論文の著者ではありません。
123万トークン
pip install linformer-pytorch
あるいは、
git clone https://github.com/tatp22/linformer-pytorch.git
cd linformer-pytorch
リンフォーマー言語モデル
from linformer_pytorch import LinformerLM
import torch
model = LinformerLM (
num_tokens = 10000 , # Number of tokens in the LM
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
use_pos_emb = True , # Whether or not to use positional embeddings
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
emb_dim = 128 , # If you want the embedding dimension to be different than the channels for the Linformer
causal = False , # If you want this to be a causal Linformer, where the upper right of the P_bar matrix is masked out.
method = "learnable" , # The method of how to perform the projection. Supported methods are 'convolution', 'learnable', and 'no_params'
ff_intermediate = None , # See the section below for more information
). cuda ()
x = torch . randint ( 1 , 10000 ,( 1 , 512 )). cuda ()
y = model ( x )
print ( y ) # (1, 512, 10000) Linformer セルフ アテンション、 MHAttentionおよびFeedForwardのスタック
from linformer_pytorch import Linformer
import torch
model = Linformer (
input_size = 262144 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
). cuda ()
x = torch . randn ( 1 , 262144 , 64 ). cuda ()
y = model ( x )
print ( y ) # (1, 262144, 64)リンフォーマー マルチヘッドの注意
from linformer_pytorch import MHAttention
import torch
model = MHAttention (
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim = 8 , # Dim of each attn head
dim_k = 128 , # What to sample the input length down to
nhead = 8 , # Number of heads
dropout = 0 , # Dropout for each of the heads
activation = "gelu" , # Activation after attention has been concat'd
checkpoint_level = "C2" , # If C2, checkpoint each of the heads
parameter_sharing = "layerwise" , # What level of parameter sharing to do
E_proj , F_proj , # The E and F projection matrices
full_attention = False , # Use full attention instead
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x )
print ( y ) # (1, 512, 64)リニアアテンションヘッド、紙の斬新さ
from linformer_pytorch import LinearAttentionHead
import torch
model = LinearAttentionHead (
dim = 64 , # Dim 2 of the input
dropout = 0.1 , # Dropout of the P matrix
E_proj , F_proj , # The E and F layers
full_attention = False , # Use Full Attention instead
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x , x , x )
print ( y ) # (1, 512, 64)エンコーダ/デコーダ モジュール。
注: 因果シーケンスの場合、 LinformerLMでcausal=Trueフラグをオンに設定して、 (n,k)アテンション行列の右上をマスクすることができます。
import torch
from linformer_pytorch import LinformerLM
encoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
k_reduce_by_layer = 1 ,
return_emb = True ,
)
decoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
decoder_mode = True ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
x_mask = torch . ones_like ( x ). bool ()
y_mask = torch . ones_like ( y ). bool ()
enc_output = encoder ( x , input_mask = x_mask )
print ( enc_output . shape ) # (1, 512, 128)
dec_output = decoder ( y , embeddings = enc_output , input_mask = y_mask , embeddings_mask = x_mask )
print ( dec_output . shape ) # (1, 512, 10000) E行列とF行列を取得する簡単な方法は、 get_EF関数を呼び出すことで実行できます。例として、 nが1000 、 kが100の場合:
from linfromer_pytorch import get_EF
import torch
E = get_EF ( 1000 , 100 )methodフラグを使用すると、リンフォーマーがダウンサンプリングを実行する方法を設定できます。現在、次の 3 つの方法がサポートされています。
learnable : このダウンサンプリング手法は、学習可能なn,k nn.Linearモジュールを作成します。convolution : このダウンサンプリング手法は、ストライド長とカーネル サイズn/kで 1d コンボリューションを作成します。no_params : N(0,1/k) の値を持つ固定n,k行列を作成します。将来的には、プーリングなどを含める可能性があります。しかし今のところ、これらが存在する選択肢です。
メモリ節約をさらに導入する試みとして、チェックポイント レベルの概念が導入されました。現在の 3 つのチェックポイント レベルは、 C0 、 C1 、およびC2です。チェックポイント レベルを上げるときは、メモリを節約するために速度を犠牲にします。つまり、チェックポイント レベルC0最も高速ですが、GPU 上で最も多くのスペースを占有し、 C2最も低速ですが、GPU 上で最も少ないスペースを占有します。各チェックポイント レベルの詳細は次のとおりです。
C0 : チェックポイント設定はありません。モデルは、すべてのアテンション ヘッドと ff レイヤーを GPU メモリに保持したまま実行されます。C1 : 各マルチヘッド アテンションと各 ff レイヤーをチェックポイントします。これにより、 depth増やしてもメモリへの影響は最小限になるはずです。C2 : C1レベルでの最適化に加えて、各マルチヘッド アテンション レイヤーの各ヘッドにチェックポイントを付けます。これにより、 nhead増やしてもメモリへの影響が少なくなるはずです。ただし、 torch.catを使用してヘッドを連結すると依然として多くのメモリが消費されるため、将来的には最適化されることが期待されます。パフォーマンスの詳細はまだ不明ですが、試してみたいユーザーのためにオプションが存在します。
この論文でメモリ節約を導入するもう 1 つの試みは、投影間のパラメータ共有を導入することでした。これについては、この論文のセクション 4 で説明されています。特に、著者らが議論したパラメータ共有には 4 つの異なるタイプがあり、すべてがこのリポジトリに実装されています。最初のオプションは最も多くのメモリを使用し、その後のオプションごとに必要なメモリ要件が減ります。
none : これはパラメータ共有ではありません。すべてのヘッドおよびすべての層について、新しいEおよび新しいFマトリックスが各層のすべてのヘッドに対して計算されます。headwise : 各レイヤーには固有のEおよびFマトリックスがあります。レイヤー内のすべてのヘッドがこのマトリックスを共有します。kv : 各層には一意の射影行列Pがあり、各層のE = F = Pです。すべてのヘッドがこの射影行列Pを共有します。layerwise : 1 つの射影行列Pがあり、すべての層のすべてのヘッドがE = F = P使用します。論文で始めたように、これは、12 層、12 ヘッドのネットワークの場合、それぞれ288 、 24 、 12 、および1異なる射影行列が存在することを意味します。
k_reduce_by_layerオプションでは、最初の層にkの次元が使用されるため、 layerwiseオプションは無効になることに注意してください。したがって、 k_reduce_by_layerの値が0より大きい場合は、 layerwise共有オプションを使用しないほうがよいでしょう。
また、著者によれば、図 3 では、このパラメータの共有は最終結果にあまり影響を与えないことに注意してください。したがって、すべてをlayerwiseごとに共有することに固執するのが最善かもしれませんが、ユーザーがそれを試してみるオプションも存在します。
Linformer の現在の実装に関するわずかな問題の 1 つは、シーケンスの長さがモデルのinput_sizeフラグと一致する必要があることです。パダーは、テンソルをネットワークに供給できるように入力サイズをパディングします。例:
from linformer_pytorch import Linformer , Padder
import torch
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_d = 32 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 6 ,
depth = 3 ,
checkpoint_level = "C1" ,
)
model = Padder ( model )
x = torch . randn ( 1 , 500 , 16 ) # This does not match the input size!
y = model ( x )
print ( y ) # (1, 500, 16) 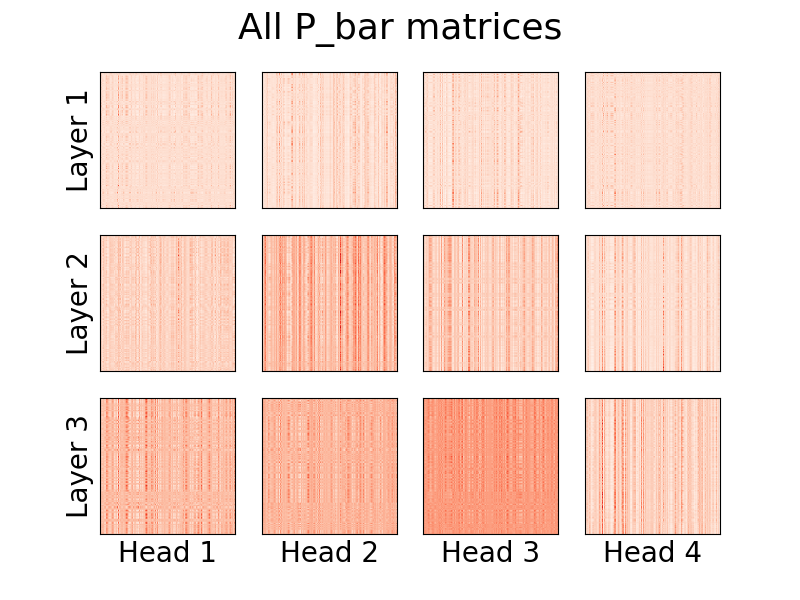
バージョン0.8.0からは、リンフォーマーのアテンションヘッドを視覚化できるようになりました。これを実際に確認するには、 Visualizerクラスをインポートし、 plot_all_heads()関数を実行して、各レベルのサイズ (n,k) のすべてのアテンション ヘッドの画像を表示します。フォワード パスでvisualize=Trueを指定していることを確認してください。これによりP_bar行列が保存され、 Visualizerクラスが頭部を適切に視覚化できるようになります。
コードの実際の例は以下にあり、同じコードは./examples/example_vis.pyにあります。
import torch
from linformer_pytorch import Linformer , Visualizer
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_k = 128 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
checkpoint_level = "C0" ,
parameter_sharing = "layerwise" ,
k_reduce_by_layer = 1 ,
)
# One can load the model weights here
x = torch . randn ( 1 , 512 , 16 ) # What input you want to visualize
y = model ( x , visualize = True )
vis = Visualizer ( model )
vis . plot_all_heads ( title = "All P_bar matrices" , # Change the title if you'd like
show = True , # Show the picture
save_file = "./heads.png" , # If not None, save the picture to a file
figsize = ( 8 , 6 ), # How big the figure should be
n_limit = None # If not None, limit how much from the `n` dimension to show
)これらの頭の意味の詳細な説明は #15 にあります。
Reformer と同様に、トレーニングを簡素化できるように Encoder/Decoder モジュールを作成しようとします。これは 2 つのLinformerLMクラスのように機能します。エンコーダはすべてのハイパーパラメータに対してenc_プレフィックスを持ち、デコーダは同様の方法でdec_プレフィックスを持ち、パラメータはそれぞれ個別に調整できます。これまでのところ、実装されているものは次のとおりです。
import torch
from linformer_pytorch import LinformerEncDec
encdec = LinformerEncDec (
enc_num_tokens = 10000 ,
enc_input_size = 512 ,
enc_channels = 16 ,
dec_num_tokens = 10000 ,
dec_input_size = 512 ,
dec_channels = 16 ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
output = encdec ( x , y )このためのテキストシーケンスを生成する方法を計画しています。
ff_intermediateチューニング現在、モデルの次元は中間層で異なる場合があります。この変更は ff モジュールに適用され、エンコーダーにのみ適用されます。ここで、フラグff_intermediateが None でない場合、レイヤーは次のようになります。
channels -> ff_dim -> ff_intermediate (For layer 1)
ff_intermediate -> ff_dim -> ff_intermediate (For layers 2 to depth-1)
ff_intermediate -> ff_dim -> channels (For layer depth)
とは対照的に、
channels -> ff_dim -> channels (For all layers)
input_sizeとdim_kで編集可能です。apexのようなライブラリはこれで動作するはずですが、実際にはテストされていません。input_size 、k= dim_k 、および d= dim_dの場合、メモリと時間の要件は O(nkd) 程度であることがわかりました。 LinformerEncDecクラスを完了する論文の結果を再現するのは初めてなので、間違っている点もあるかもしれません。問題が見つかった場合は、問題を開いてください。問題に対処してみます。
lucidrains に感謝します。この Linformer リポジトリの設計では、彼の他のスパース アテンション リポジトリが私を助けてくれました。
@misc { wang2020linformer ,
title = { Linformer: Self-Attention with Linear Complexity } ,
author = { Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma } ,
year = { 2020 } ,
eprint = { 2006.04768 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { vaswani2017attention ,
title = { Attention is all you need } ,
author = { Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {L}ukasz and Polosukhin, Illia } ,
booktitle = { Advances in neural information processing systems } ,
pages = { 5998--6008 } ,
year = { 2017 }
}「注意して聞いてください…」


