intelligent trading bot
1.0.0
___ _ _ _ _ _ _____ _ _ ____ _
|_ _|_ __ | |_ ___| | (_) __ _ ___ _ __ | |_ |_ _| __ __ _ __| (_)_ __ __ _ | __ ) ___ | |_
| || '_ | __/ _ | | |/ _` |/ _ '_ | __| | || '__/ _` |/ _` | | '_ / _` | | _ / _ | __|
| || | | | || __/ | | | (_| | __/ | | | |_ | || | | (_| | (_| | | | | | (_| | | |_) | (_) | |_
|___|_| |_|_____|_|_|_|__, |___|_| |_|__| |_||_| __,_|__,_|_|_| |_|__, | |____/ ___/ __|
|___/ |___/
₿ Ξ ₳ ₮ ✕ ◎ ● Ð Ł Ƀ Ⱥ ∞ ξ ◈ ꜩ ɱ ε ɨ Ɓ Μ Đ ⓩ Ο Ӿ Ɍ ȿ
?インテリジェントな取引シグナル? https://t.me/intelligent_trading_signals
このプロジェクトは、最先端の機械学習 (ML) アルゴリズムと特徴量エンジニアリングを使用して、自動取引暗号通貨用のインテリジェント取引ボットを開発することを目的としています。このプロジェクトは、次の主要な機能を提供します。
シグナリング サービスはクラウドで実行されており、そのシグナルを次の Telegram チャネルに送信します。
?インテリジェントな取引シグナル? https://t.me/intelligent_trading_signals
誰でもチャンネルに登録して、このボットが生成するシグナルについての印象を得ることができます。
現在、ボットは次のパラメーターを使用して構成されています。
スコアがしきい値を下回り、チャネルに通知が送信されないサイレント期間が存在します。スコアがしきい値より大きい場合は、次のような通知が 1 分ごとに送信されます。
₿ 24.518 ???スコア: -0.26
最初の数字は最新の終値です。スコア -0.26 は、価格が現在の終値よりも安くなる可能性が非常に高いことを意味します。
スコアがモデルで指定されたしきい値を超えた場合、売買シグナルが生成され、取引を行うのに良い時期であることを意味します。このような通知は次のようになります。
?購入: ₿ 24,033 スコア: +0.34
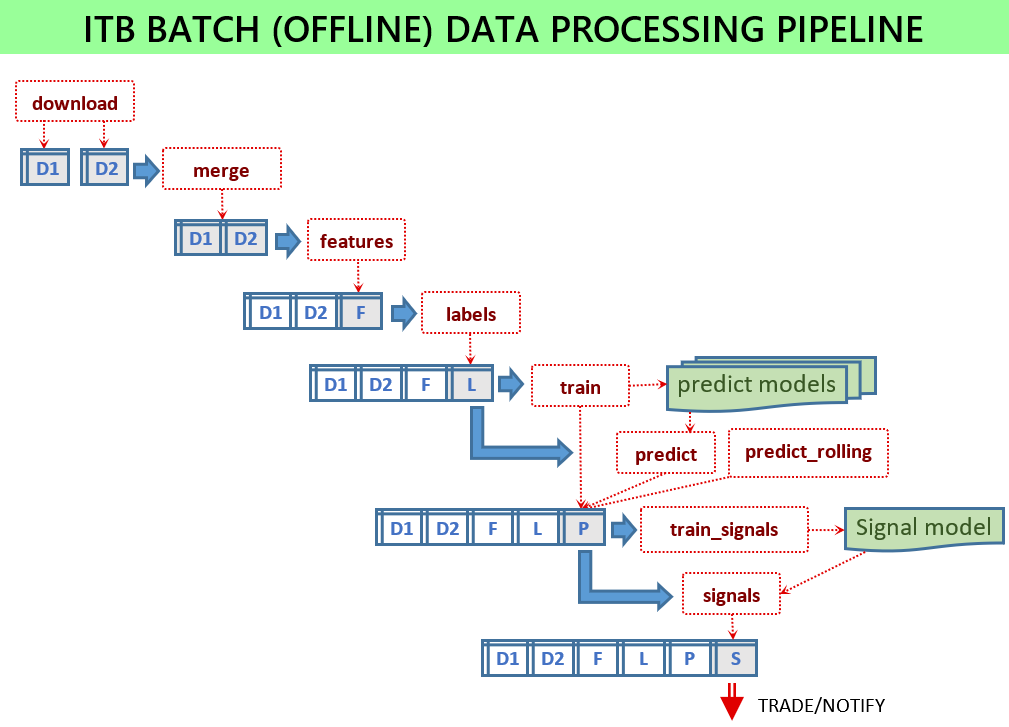
Signaler サービスが機能するには、多数の ML モデルがトレーニングされ、サービスで使用できるモデル ファイルが必要です。すべてのスクリプトは、いくつかの入力データをロードし、いくつかの出力ファイルを保存することにより、バッチ モードで実行されます。バッチ スクリプトはscriptsモジュールにあります。
すべてが設定されている場合は、次のスクリプトを実行する必要があります。
python -m scripts.download_binance -c config.jsonpython -m scripts.merge -c config.jsonpython -m scripts.features -c config.jsonpython -m scripts.labels -c config.jsonpython -m scripts.train -c config.jsonpython -m scripts.signals -c config.jsonpython -m scripts.train_signals -c config.json構成ファイルがないと、スクリプトはデフォルトのパラメータを使用します。これはテスト目的に役立ちますが、良好なパフォーマンスを示すことを目的としたものではありません。 config-sample-v0.6.0.jsoncなど、リリースごとに提供されるサンプル構成ファイルを使用します。
両方のスクリプトの主な構成パラメータは、 data_sources内のソースのリストです。このリストの 1 つのエントリは、データ ソースと、異なるソースからの同じ名前の列を区別するために使用されるcolumn_prefix指定します。
最新の履歴データをダウンロードします: python -m scripts.download_binance -c config.json
複数の履歴データセットを 1 つのデータセットにマージします: python -m scripts.merge -c config.json
このスクリプトは、派生機能を計算することを目的としています。
python -m scripts.features -c config.json生成される機能のリストは、構成ファイル内のfeature_setsリストを介して構成されます。フィーチャがどのように生成されるかは、config セクションで指定されたいくつかのパラメータを持つフィーチャ ジェネレータによって定義されます。
talib特徴ジェネレーターは、TA-lib 技術分析ライブラリに依存しています。以下はその構成の例です"config": {"columns": ["close"], "functions": ["SMA"], "windows": [5, 10, 15]}itbstats特徴ジェネレーターは、 scipy_skew 、 scipy_kurtosis 、 lsbm (平均値を下回る最長ストライク)、 fmax (最大値の最初の位置)、 mean 、 std 、 area 、 slopeなどの tsfresh にある関数を実装します。一般的なパラメータは次のとおりです: "config": {"columns": ["close"], "functions": ["skew", "fmax"], "windows": [5, 10, 15]}itblib特徴ジェネレーターは ITB に実装されていますが、その機能のほとんどは talib 経由で (はるかに高速に) 生成できます。tsfresh tsfresh ライブラリから関数を生成しますこのスクリプトは、入力ファイルに新しい列を追加するため、フィーチャ生成に似ています。ただし、これらの列は、予測したいことと、オンライン モードで実行するときに不明なことを説明します。たとえば、将来の価格上昇が考えられます。
python -m scripts.labels -c config.json生成されるラベルのリストは、構成内のlabel_setsリストを介して構成されます。 1 つのラベル セットは、追加の列を生成する関数を指します。それらの構成は機能の構成と非常に似ています。
highlowラベル ジェネレーターは、価格が将来の期間内に指定されたしきい値よりも高い場合に True を返します。highlow2それ以前に大きな減少(増加)がないことを条件として、将来の増加(減少)を計算します。その典型的な構成は次のとおりです"config": {"columns": ["close", "high", "low"], "function": "high", "thresholds": [1.0, 1.5, 2.0], "tolerance": 0.2, "horizon": 10080, "names": ["first_high_10", "first_high_15", "first_high_20"]}topbot非推奨になりましたtopbot2最大値と最小値を計算します (True としてラベル付けされます)。ラベル付きのすべての最大値 (最小値) は、指定されたレベルよりも低い (高い) 最小値 (最大値) に囲まれることが保証されます。隣接する最小値と最大値の間の必要な最小差は、 levelパラメーターによって指定されます。許容値パラメーターを使用すると、最大/最小に近い点も含めることができます。一般的な構成は次のとおりです"config": {"columns": "close", "function": "bot", "level": 0.02, "tolerances": [0.1, 0.2], "names": ["bot2_1", "bot2_2"]} このスクリプトは、指定された入力特徴とラベルを使用して、いくつかの ML モデルをトレーニングします。
python -m scripts.train -c config.jsonprediction-metrics.txtファイルも生成します。構成:
model_store.pyに記述されていますtrain_featuresで指定しますlabelsで指定しますalgorithmsで指定されますこのステップの目的は、さまざまなラベルに対してさまざまなアルゴリズムによって生成された予測スコアを集計することです。結果は 1 つのスコアとなり、次のステップの信号ルールによって消費されることになります。集計パラメータは、 score_aggregationセクションで指定します。 buy_labelsとsell_labels集計手順によって処理される入力予測スコアを指定します。 windowローリング集計に使用される前のステップの数であり、 combine 2 つのスコア タイプ (購入とラベル) を 1 つの出力スコアに結合する方法です。
集計手順によって生成されるスコアは何らかの数値であり、シグナル ルールの目的は、売買の決定 (買うか売るか何もしない) を行うことです。シグナルルールのパラメータはtrade_modelに記述されます。
このスクリプトは、多くの売買シグナル パラメーターを使用して取引をシミュレートし、最もパフォーマンスの高いシグナル パラメーターを選択します。
python -m scripts.train_signals -c config.jsonこのスクリプトは、最新のデータの読み込み、特徴の生成、予測の実行、シグナルの生成、サブスクライバーへの通知という同じタスクを定期的に実行するサービスを開始します。
python -m service.server -c config.json次の 2 つの問題があります。
python -m scripts.predict_rolling -c config.jsonpython -m scripts.train_signals -c config.json構成パラメータは、次の 2 つのファイルで指定されます。
Appクラスのconfigフィールドのservice.App.py-c config.jsom引数。このファイルがスクリプトまたはサービスに読み込まれると、この構成ファイルの値がApp.config内の値を上書きします。以下に最も重要なフィールドをいくつか示します ( App.pyとconfig.jsonの両方)。
data_folder - バッチオフラインスクリプトにのみ必要なデータファイルの場所symbolはBTCUSDTのような取引ペアですlabels 。トレーニングと予測に使用する新しいラベルを定義する場合は、ここでその名前を指定する必要がありますalgorithmsトレーニングに使用されるアルゴリズム名のリストtrain_featuresトレーニングと予測の入力特徴として使用されるすべての列名のリスト。buy_labelsおよびsell_labelsシグナルに使用される予測列のリストtrade_modelシグナラーのパラメーター (主にいくつかのしきい値)traderトレーダーパラメータのセクションです。現時点では完全にテストされていません。collectorこれらのパラメーター セクションは、データ収集サービスを目的としています。データ収集サービスには、データ プロバイダーへの定期的なリクエストと同期するサービスと、データ プロバイダーに登録して新しいデータが利用可能になるとすぐに通知を受け取る非同期ストリーミング サービスの 2 種類があります。これらは動作していますが、十分にテストされておらず、メイン サービスに統合されていません。現在の主な使用パターンは、手動のバッチ データ更新、特徴生成、モデル トレーニングに依存しています。これらのデータ収集サービスを使用する理由の 1 つは、1) 更新を高速化するため、2) オーダーブックなどの通常の API では利用できないデータを取得するためです (このデータを使用する機能がいくつかありますが、それらはメインのワークフローには統合されていません)。詳細については、App.config のサンプル構成ファイルとコメントを参照してください。
シグナラーは 1 分ごとに次の手順を実行して、価格が上昇する可能性があるか下落する可能性があるかを予測します。
注:
サービスの開始: python3 -m service.server -c config.json
トレーダーは動作していますが、完全にはデバッグされておらず、特に安定性と信頼性についてはテストされていません。したがって、これは基本的な機能を備えたプロトタイプと考える必要があります。現在、Signaler と統合されていますが、より良い設計では別のサービスにする必要があります。
バックテスト
外部統合


