make a video pytorch
0.4.0
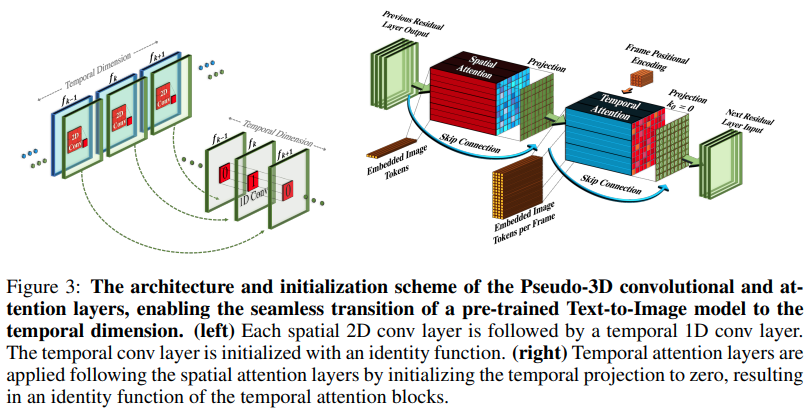
Meta AI による新しい SOTA テキストからビデオへのジェネレーターである Make-A-Video を Pytorch に実装します。これらは、擬似 3D 畳み込み (軸方向畳み込み) と時間的注意を組み合わせ、より優れた時間的融合を示します。
擬似 3D 畳み込みは新しい概念ではありません。これは、他の文脈、たとえば「次元ハイブリッド残差ネットワーク」としてのタンパク質接触予測などで以前に研究されてきました。
この論文の要点は、SOTA テキストから画像へのモデル (ここでは DALL-E2 を使用していますが、同じ学習ポイントが Imagen にも簡単に適用できます) を採用し、時間の経過やその他の方法で注目を集めるためにいくつかの小さな変更を加えるということです。計算コストを節約し、フレーム補間を正しく実行し、優れたビデオ モデルを取得します。
AIコーヒーブレイクの説明
Stability.ai は最先端の人工知能研究に取り組むための寛大なスポンサーシップを提供しています
ジョナサン・ホー氏、独創的な論文を通じて生成人工知能に革命をもたらした功績
Alex の einops は、まさに天才的な抽象化です。それ以外の言葉はありません。
$ pip install make-a-video-pytorchビデオ機能を渡す
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
conv_out = conv ( video ) # (1, 256, 8, 16, 16)
attn_out = attn ( video ) # (1, 256, 8, 16, 16)画像を渡すと (最初に画像で事前学習した場合)、時間的畳み込みと注意の両方が自動的にスキップされます。言い換えれば、これを 2D Unet で直接使用し、トレーニングのその段階が完了したら 3D Unet に移植することができます。一時モジュールは、論文で行われたように ID を出力するように初期化されます。
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
images = torch . randn ( 1 , 256 , 16 , 16 ) # (batch, features, height, width)
conv_out = conv ( images ) # (1, 256, 16, 16)
attn_out = attn ( images ) # (1, 256, 16, 16)2 つのモジュールを制御して、3 次元の特徴が与えられたときに空間的なトレーニングのみを行うようにすることもできます。
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
# below it will not train across time
conv_out = conv ( video , enable_time = False ) # (1, 256, 8, 16, 16)
attn_out = attn ( video , enable_time = False ) # (1, 256, 8, 16, 16)画像やビデオ トレーニングに依存せず、ビデオが渡された場合でも時間を無視できる完全なSpaceTimeUnet
import torch
from make_a_video_pytorch import SpaceTimeUnet
unet = SpaceTimeUnet (
dim = 64 ,
channels = 3 ,
dim_mult = ( 1 , 2 , 4 , 8 ),
resnet_block_depths = ( 1 , 1 , 1 , 2 ),
temporal_compression = ( False , False , False , True ),
self_attns = ( False , False , False , True ),
condition_on_timestep = False ,
attn_pos_bias = False ,
flash_attn = True
). cuda ()
# train on images
images = torch . randn ( 1 , 3 , 128 , 128 ). cuda ()
images_out = unet ( images )
assert images . shape == images_out . shape
# then train on videos
video = torch . randn ( 1 , 3 , 16 , 128 , 128 ). cuda ()
video_out = unet ( video )
assert video_out . shape == video . shape
# or even treat your videos as images
video_as_images_out = unet ( video , enable_time = False )研究が提供する最良の位置埋め込みに注目してください
注目を集める
フラッシュアテンションを追加する
dalle2-pytorch がトレーニングのためにSpaceTimeUnet受け入れられることを確認してください
@misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @article { Dong2021AttentionIN ,
title = { Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth } ,
author = { Yihe Dong and Jean-Baptiste Cordonnier and Andreas Loukas } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2103.03404 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { shleifer2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Sam Shleifer and Myle Ott } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
}

