rtdl num embeddings
v0.0.11
重要
新しい表形式 DL モデル: TabM をチェックしてください。
arXiv ? Python パッケージその他の表形式 DL プロジェクト
これは、論文「表形式深層学習における数値特徴の埋め込みについて」の正式な実装です。
一言で言えば、元のスカラー連続特徴をメイン バックボーン (MLP、Transformer など) で混合する前にベクトルに変換すると、表形式ニューラル ネットワークの下流のパフォーマンスが向上します。
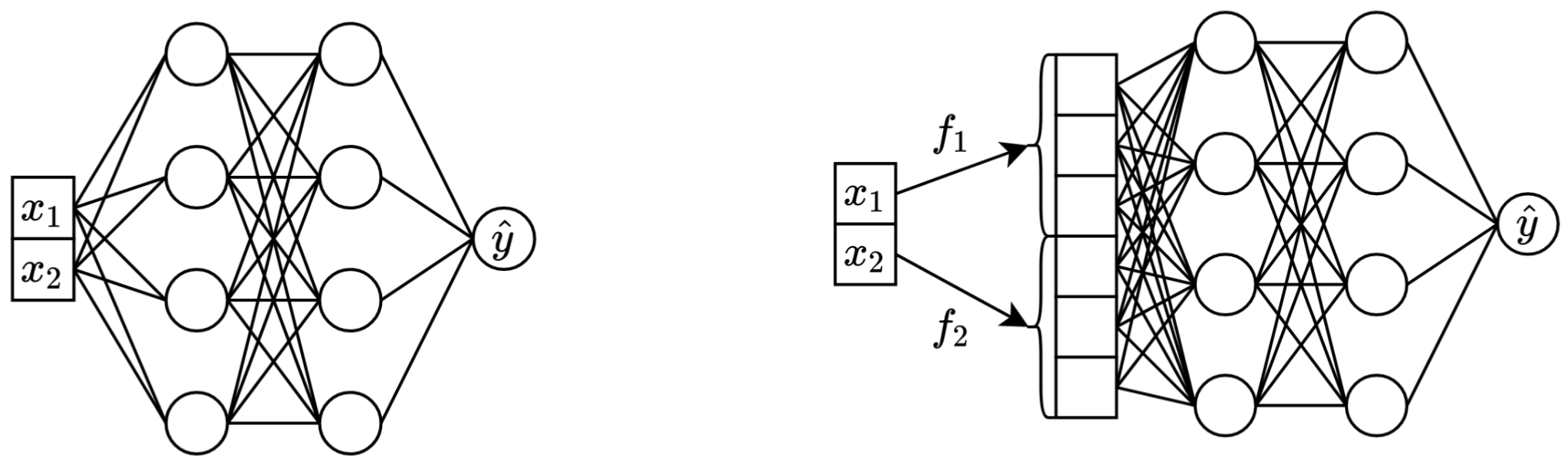
左: 2 つの連続特徴を入力として受け取るバニラ MLP。
右: 同じ MLP ですが、連続特徴の埋め込みが追加されています。
さらに詳しく:
厳密に言えば、単一の説明はありません。明らかに、埋め込みは連続特徴に関連するさまざまな課題に対処し、モデルの全体的な最適化特性を向上させるのに役立ちます。
特に、不規則に分散された連続フィーチャ (およびラベルとの不規則な結合分布) は、現実世界の表形式データではよくあることであり、従来の表形式 DL モデルにとって、根本的な最適化に関する大きな課題となっています。この課題を理解するための優れた参考文献(および入力空間を変換することでこれらの課題に対処する優れた例) は、論文「フーリエ機能によりネットワークが低次元領域で高周波関数を学習できるようにする」です。
ただし、不規則な分布だけが埋め込みが役立つ唯一の理由であるかどうかは不明です。
package/ディレクトリ内の Python パッケージは、論文を実際に使用する場合や将来の作業に使用する場合に推奨される方法です。
文書の残りの部分:
exp/ディレクトリには、論文で使用されているさまざまなモデルやデータセットの多数の結果と (調整された) ハイパーパラメータが含まれています。
たとえば、MLP モデルのメトリクスを調べてみましょう。まず、レポート ( report.jsonファイル) をロードしましょう。
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'exp' ). glob ( 'mlp/*/0_evaluation/*/report.json' )
])ここで、データセットごとに、すべてのランダム シードの平均テスト スコアを計算してみましょう。
print ( df . groupby ( 'config.data.path' )[ 'metrics.test.score' ]. mean (). round ( 3 ))出力は論文の表 3 と完全に一致します。
config.data.path
data/adult 0.854
data/california -0.495
data/churn 0.856
data/covtype 0.964
data/fb-comments -5.686
data/gesture 0.632
data/higgs-small 0.720
data/house -32039.399
data/microsoft -0.747
data/otto 0.818
data/santander 0.912
Name: metrics.test.score, dtype: float64
上記のアプローチは、さまざまなアルゴリズムの一般的なハイパーパラメーター値を直感的に把握するためにハイパーパラメーターを調査するために使用することもできます。たとえば、MLP モデルの調整された学習率の中央値を計算する方法は次のとおりです。
注記
一部のアルゴリズム (MLP、MLP-LR、MLP-PLR など) については、より最近のプロジェクトが、同様の方法で調査できるより多くの結果を提供します。たとえば、TabR に関するこの論文を参照してください。
警告
このアプローチは注意して使用してください。ハイパーパラメータ値を調べる場合:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002716544410603358重要
このセクションは長いです。このセクションの概要を理解するには、テキスト エディターで GitHub の「アウトライン」機能を使用します。
予選:
/usr/local/cuda-11.1/binが常にPATH環境変数に含まれていることを確認してください。 export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/num-embeddings
git clone https://github.com/yandex-research/tabular-dl-num-embeddings $PROJECT_DIR
cd $PROJECT_DIR
conda create -n num-embeddings python=3.9.7
conda activate num-embeddings
pip install torch==1.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
# the following command appends ":/usr/local/cuda-11.1/lib64" to LD_LIBRARY_PATH;
# if your LD_LIBRARY_PATH already contains a path to some other CUDA, then the content
# after "=" should be "<your LD_LIBRARY_PATH without your cuda path>:/usr/local/cuda-11.1/lib64"
conda env config vars set LD_LIBRARY_PATH= ${LD_LIBRARY_PATH} :/usr/local/cuda-11.1/lib64
conda env config vars set CUDA_HOME=/usr/local/cuda-11.1
conda env config vars set CUDA_ROOT=/usr/local/cuda-11.1
# (optional) get a shortcut for toggling the dark mode with cmd+y
conda install nodejs
jupyter labextension install jupyterlab-theme-toggle
conda deactivate
conda activate num-embeddingsライセンス: データセットをダウンロードすると、そのすべてのコンポーネントのライセンスに同意したことになります。これらのライセンスに加えて、新たな制限を課すことはありません。出典のリストは論文内にあります。
cd $PROJECT_DIR
wget " https://www.dropbox.com/s/r0ef3ij3wl049gl/data.tar?dl=1 " -O num_embeddings_data.tar
tar -xvf num_embeddings_data.tar以下のコードは、California Housing データセットに対する MLP の結果を再現します。他のアルゴリズムとデータセットのパイプラインはまったく同じです。
# You must explicitly set CUDA_VISIBLE_DEVICES if you want to use GPU
export CUDA_VISIBLE_DEVICES="0"
# Create a copy of the 'official' config
cp exp/mlp/california/0_tuning.toml exp/mlp/california/1_tuning.toml
# Run tuning (on GPU, it takes ~30-60min)
python bin/tune.py exp/mlp/california/1_tuning.toml
# Evaluate single models with 15 different random seeds
python bin/evaluate.py exp/mlp/california/1_tuning 15
# Evaluate ensembles (by default, three ensembles of size five each)
python bin/ensemble.py exp/mlp/california/1_evaluation
「メトリクス」セクションでは、取得した結果を要約する方法を示します。
コードは次のように構成されています。
bintrain4.py (論文に記載されているすべての埋め込みとバックボーンを実装します)xgboost_.pycatboost_.pytune.pyevaluate.pyensemble.pydatasets.pyデータセット分割の構築に使用されましたsynthetic.pytrain1_synthetic.py合成データを使用した実験用lib bin内のプログラムで使用される共通ツールが含まれていますexp実験構成と結果 (メトリクス、調整された構成など) が含まれます。ネストされたフォルダーの名前は論文の名前に従います (例: exp/mlp-plr論文の MLP-PLR モデルに対応します)。packageこの論文の Python パッケージが含まれていますCUDA_VISIBLE_DEVICES明示的に設定する必要がありますlib.dump_configとlib.load_config使用します。スクリプトを実行する一般的なパターンは次のとおりです。
python bin/my_script.py a/b/c.tomlここで、 a/b/c.tomlは入力構成ファイル (config) です。出力はa/b/cにあります。 config 構造は通常、 bin/my_script.pyのConfigクラスに従います。
構成の代わりにコマンドライン引数を取るスクリプトもあります (例: bin/{evaluate.py,ensemble.py} )。
結果を再現するにはこれらすべてが必要ですが、今後の作業にはtrain4.pyのみが必要です。理由は次のとおりです。
bin/train1.py bin/train0.pyの機能のスーパーセットを実装します。bin/train3.py bin/train1.pyの機能のスーパーセットを実装します。bin/train4.py bin/train3.pyの機能のスーパーセットを実装します。特定の実験の実行に 4 つのスクリプトのどれが使用されたかを確認するには、対応する調整構成の「プログラム」フィールドを確認します。たとえば、California Housing データセットの MLP の調整構成は次のとおりです: exp/mlp/california/0_tuning.toml 。構成は、 bin/train0.pyが使用されたことを示しています。これは、 exp/mlp/california/0_evaluationの構成が特にbin/train0.pyと互換性があることを意味します。それを確認するには、それらの 1 つを別の場所にコピーし、 bin/train0.pyに渡します。
mkdir exp/tmp
cp exp/mlp/california/0_evaluation/0.toml exp/tmp/0.toml
python bin/train0.py exp/tmp/0.toml
ls exp/tmp/0
@inproceedings{gorishniy2022embeddings,
title={On Embeddings for Numerical Features in Tabular Deep Learning},
author={Yury Gorishniy and Ivan Rubachev and Artem Babenko},
booktitle={{NeurIPS}},
year={2022},
}


