gigagan pytorch
0.2.20

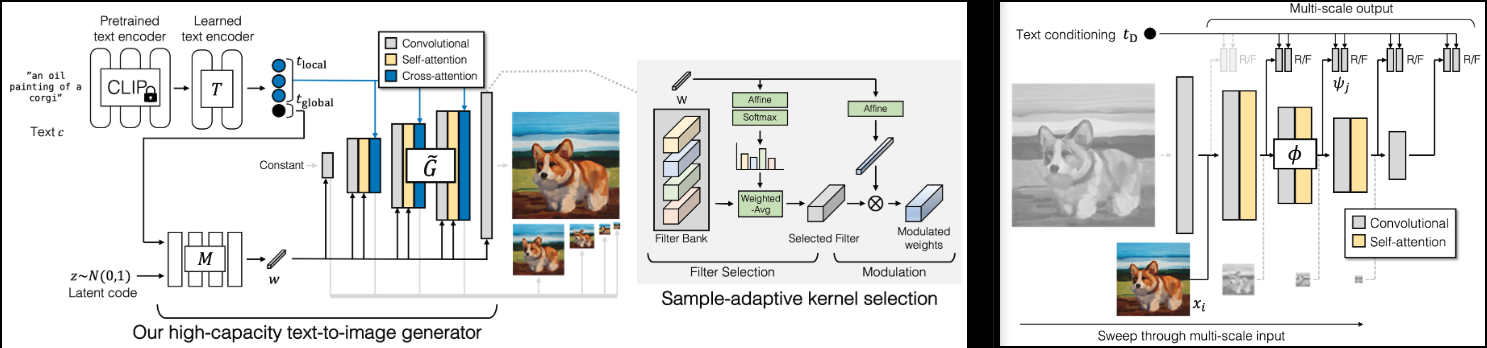
Adobe の新しい SOTA GAN、GigaGAN (プロジェクト ページ) の実装。
また、より高速な収束 (スキップ層励起) とより優れた安定性 (弁別器での再構成補助損失) のために、軽量 gan からの発見をいくつか追加します。
また、1k ~ 4k アップサンプラーのコードも含まれており、これがこのペーパーのハイライトであると思います。
LAION コミュニティでレプリケーションを支援することに興味がある場合は、ぜひご参加ください。
StabilityAIと?オープンソース人工知能への独立性を私に与えてくれた寛大なスポンサーと他のスポンサーに感謝します。
?加速ライブラリのハグフェイス
SOTA オープンソース対照学習テキスト画像モデルの OpenClip のメンテナ全員
Xavier さん、非常に役立つコードレビューと、弁別器のスケール不変性をどのように構築するかについて議論してくれました。
@CerebralSeed は、ジェネレーターとアップサンプラーの両方の初期サンプリング コードをプル リクエストしました。
Keerth はコードレビューに協力し、論文とのいくつかの矛盾を指摘してくれました。
$ pip install gigagan-pytorchシンプルな無条件 GAN、初心者向け
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
generator = dict (
dim_capacity = 8 ,
style_network = dict (
dim = 64 ,
depth = 4
),
image_size = 256 ,
dim_max = 512 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
amp = True
). cuda ()
# dataset
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
# you must then set the dataloader for the GAN before training
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
images = gan . generate ( batch_size = 4 ) # (4, 3, 256, 256)無条件 Unet アップサンプラーの場合
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
train_upsampler = True , # set this to True
generator = dict (
style_network = dict (
dim = 64 ,
depth = 4
),
dim = 32 ,
image_size = 256 ,
input_image_size = 64 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
multiscale_input_resolutions = ( 128 ,),
unconditional = True
),
amp = True
). cuda ()
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
lowres = torch . randn ( 1 , 3 , 64 , 64 ). cuda ()
images = gan . generate ( lowres ) # (1, 3, 256, 256) G - ジェネレーターMSG - マルチスケール ジェネレーターD - 弁別子MSD - マルチスケール弁別器GP - 勾配ペナルティSSL - Discriminator での補助再構成 (軽量 GAN から)VD - 視覚支援ディスクリミネーターVG - 視覚支援ジェネレーターCL - 発電機のコントラスト損失MAL - マッチング認識損失正常な実行では、 G 、 MSG 、 D 、 MSD値は0から10の間で変動し、通常はほぼ一定に保たれます。 1,000 トレーニング ステップ後のいずれかの時点で、これらの値が 3 桁を維持する場合、それは何かが間違っていることを意味します。ジェネレーターとディスクリミネーターの値が時折マイナスに下がっても問題ありませんが、上記の範囲まで戻るはずです。
GPとSSL 0に向かってプッシュする必要があります。 GP時折スパイクすることがあります。ネットワークが何らかのひらめきを経験しているように想像してみたいと思います
GigaGANクラスに?が搭載されました。アクセル。 accelerate CLI を使用すると、2 つのステップでマルチ GPU トレーニングを簡単に実行できます。
トレーニング スクリプトがあるプロジェクトのルート ディレクトリで、次のコマンドを実行します。
$ accelerate config次に、同じディレクトリ内に
$ accelerate launch train . py 無条件でトレーニングできるようにする
関連する論文を読み、3 つの補助損失をすべてノックアウトします。
unet アップサンプラー
論文が少し曖昧だったので、マルチスケールの入力と出力のコード レビューを取得します。
アップサンプリング ネットワーク アーキテクチャを追加する
ベースジェネレーターとアップサンプラーの両方で無条件に動作するようにします
テキスト条件付きトレーニングをベースとアップサンプラーの両方で機能させる
パッチをランダムにサンプリングすることで偵察をより効率的にする
ジェネレーターとディスクリミネーターが事前にエンコードされたCLIPテキストエンコーディングも受け入れられることを確認してください
補助損失を見直す
古い GAN 時代から実証済みの技術である微分可能な拡張を追加します。
すべての変調投影を適応型 conv2d クラスに移動します。
追加加速
クリップはすべてのモジュールでオプションであり、 GigaGANによって管理され、テキスト -> テキスト埋め込みは 1 回処理される必要があります
効率性を高めるために、マルチスケール ディメンションからランダムなサブセットを選択する機能を追加します
Lightweight|stylegan2-pytorch からの CLI 経由のポート
テキスト画像用の laion データセットを接続する
@misc { https://doi.org/10.48550/arxiv.2303.05511 ,
url = { https://arxiv.org/abs/2303.05511 } ,
author = { Kang, Minguk and Zhu, Jun-Yan and Zhang, Richard and Park, Jaesik and Shechtman, Eli and Paris, Sylvain and Park, Taesung } ,
title = { Scaling up GANs for Text-to-Image Synthesis } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @article { Liu2021TowardsFA ,
title = { Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis } ,
author = { Bingchen Liu and Yizhe Zhu and Kunpeng Song and A. Elgammal } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2101.04775 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Karras2020ada ,
title = { Training Generative Adversarial Networks with Limited Data } ,
author = { Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila } ,
booktitle = { Proc. NeurIPS } ,
year = { 2020 }
} @article { Xu2024VideoGigaGANTD ,
title = { VideoGigaGAN: Towards Detail-rich Video Super-Resolution } ,
author = { Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2404.12388 } ,
url = { https://api.semanticscholar.org/CorpusID:269214195 }
}

