byol pytorch
0.8.2
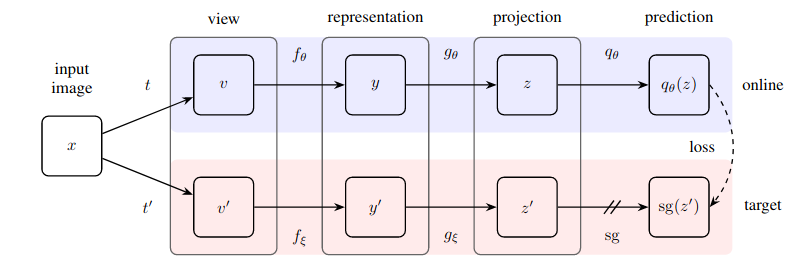
対照学習を必要とせず、ネガティブペアを指定する必要もなく、新しい最先端 (SimCLR を超える) を達成する自己教師あり学習のための驚くほど簡単な方法の実用的な実装。
このリポジトリは、任意の画像ベースのニューラル ネットワーク (残差ネットワーク、弁別器、ポリシー ネットワーク) を簡単にラップして、ラベルのない画像データからすぐにメリットを享受できるモジュールを提供します。
アップデート 1: この手法をうまく機能させるにはバッチ正規化が鍵であるという新たな証拠があります。
更新 2: 新しい論文はバッチ基準をグループ基準 + 重みの標準化に置き換えることに成功し、BYOL が機能するにはバッチ統計が必要であると反論しました。
アップデート 3: 最後に、これが機能する理由についていくつかの分析を行いました。
ヤニック・キルチャー氏の素晴らしい解説
さあ、あなたの組織がラベルの代金を支払わなくて済むようにしましょう :)
$ pip install byol-pytorchニューラル ネットワークをプラグインするだけで、(1) 画像の寸法と (2) 隠れ層の名前 (またはインデックス) を指定します。隠れ層の出力は、自己教師ありトレーニングに使用される潜在表現として使用されます。
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of target encoder
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )それだけです。多くのトレーニングを行った後、残差ネットワークは下流の教師ありタスクでより適切に実行できるようになります。
Kaiming He の新しい論文は、BYOL ではターゲット エンコーダがオンライン エンコーダの指数移動平均である必要さえないことを示唆しています。 use_momentumフラグをFalseに設定するだけで、そのバリアントをトレーニングに簡単に使用できるように、このオプションを組み込むことにしました。以下の例に示すように、このルートに進む場合は、 update_moving_averageを呼び出す必要はなくなります。
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
use_momentum = False # turn off momentum in the target encoder
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )ハイパーパラメータは、論文が最適であると判断した値にすでに設定されていますが、基本ラッパー クラスへの追加のキーワード引数を使用して変更できます。
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
projection_size = 256 , # the projection size
projection_hidden_size = 4096 , # the hidden dimension of the MLP for both the projection and prediction
moving_average_decay = 0.99 # the moving average decay factor for the target encoder, already set at what paper recommends
)デフォルトでは、このライブラリは SimCLR 論文 (BYOL 論文でも使用されている) の拡張を使用します。ただし、独自の拡張パイプラインを指定したい場合は、 augment_fnキーワードを使用して独自のカスタム拡張関数を渡すだけです。
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn
)論文では、拡張の 1 つが他の拡張よりもガウス ブラーの確率が高いことを保証しているようです。好みに合わせて調整することもできます。
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
augment_fn2 = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip (),
kornia . filters . GaussianBlur2d (( 3 , 3 ), ( 1.5 , 1.5 ))
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn ,
augment_fn2 = augment_fn2 ,
)埋め込みまたは投影をフェッチするには、 return_embeddings = TrueフラグをBYOL学習者インスタンスに渡すだけです。
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
imgs = torch . randn ( 2 , 3 , 256 , 256 )
projection , embedding = learner ( imgs , return_embedding = True )リポジトリでは、? を使用した分散トレーニングが提供されるようになりました。ハグフェイス加速。独自のDatasetをインポートされたBYOLTrainerに渡すだけです。
まず、加速 CLI を呼び出して、分散トレーニングの構成をセットアップします。
$ accelerate config次に、以下に示すように、たとえば./train.py内でトレーニング スクリプトを作成します。
from torchvision import models
from byol_pytorch import (
BYOL ,
BYOLTrainer ,
MockDataset
)
resnet = models . resnet50 ( pretrained = True )
dataset = MockDataset ( 256 , 10000 )
trainer = BYOLTrainer (
resnet ,
dataset = dataset ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
learning_rate = 3e-4 ,
num_train_steps = 100_000 ,
batch_size = 16 ,
checkpoint_every = 1000 # improved model will be saved periodically to ./checkpoints folder
)
trainer ()次に、アクセラレーション CLI を再度使用してスクリプトを起動します。
$ accelerate launch ./train.pyダウンストリーム タスクにセグメンテーションが含まれる場合は、BYOL を「ピクセル」レベルの学習に拡張する次のリポジトリを参照してください。
https://github.com/lucidrains/pixel-level-contrastive-learning
@misc { grill2020bootstrap ,
title = { Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning } ,
author = { Jean-Bastien Grill and Florian Strub and Florent Altché and Corentin Tallec and Pierre H. Richemond and Elena Buchatskaya and Carl Doersch and Bernardo Avila Pires and Zhaohan Daniel Guo and Mohammad Gheshlaghi Azar and Bilal Piot and Koray Kavukcuoglu and Rémi Munos and Michal Valko } ,
year = { 2020 } ,
eprint = { 2006.07733 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { chen2020exploring ,
title = { Exploring Simple Siamese Representation Learning } ,
author = { Xinlei Chen and Kaiming He } ,
year = { 2020 } ,
eprint = { 2011.10566 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

