atari
1.0.0

OpenAI の Atari Gym の上に構築された Research Playground は、さまざまな強化学習アルゴリズムを実装するために準備されています。
次のゲームのいずれかをエミュレートできます。
[「アステリックス」、「アステロイド」、「ミズパックマン」、「カブーム」、「バンクハイスト」、「カンガルー」、「スキー」、「フィッシングダービー」、「クルル」、「バーザーク」、「ツタンカーム」、「ザクソン」、ベンチャー」、「リバーレイド」、「ムカデ」、 「アドベンチャー」、「ビームライダー」、「クレイジークライマー」、「タイムパイロット」、「カーニバル」、「テニス」、「シークエスト」、「ボウリング」、「スペースインベーダー」、「フリーウェイ」、「ヤーズリベンジ」、「ロードランナー」、「ジャーニーエスケープ」 '、'WizardOfWor'、'ゴーファー'、 「ブレイクアウト」、「スターガンナー」、「アトランティス」、「ダブルダンク」、「ヒーロー」、「バトルゾーン」、「ソラリス」、「アップNDダウン」、「フロストバイト」、「カンフーマスター」、「プーヤン」、「ピットフォール」、「モンテズマリベンジ」 '、'プライベートアイ'、'エアレイド'、 「Amidar」、「Robotank」、「Demon Attack」、「Defender」、「NameThisGame」、「Phoenix」、「Gravitar」、「ElevatorAction」、「Pong」、「VideoPinball」、「IceHockey」、「Boxing」、「Assault」 、「エイリアン」、「Qbert」、「エンデューロ」、 「チョッパーコマンド」、「ジェームズボンド」]
対応する Medium の記事をチェックしてください: Atari - 強化学習の詳細 ? (パート 1: DDQN)
このプロジェクトの最終目標は、atari ゲームを共通点としてさまざまな RL アプローチを実装し、比較することです。
pip install -r requirements.txtをインストールします。python atari.py --help 。 * GAMMA = 0.99
* MEMORY_SIZE = 900000
* BATCH_SIZE = 32
* TRAINING_FREQUENCY = 4
* TARGET_NETWORK_UPDATE_FREQUENCY = 40000
* MODEL_PERSISTENCE_UPDATE_FREQUENCY = 10000
* REPLAY_START_SIZE = 50000
* EXPLORATION_MAX = 1.0
* EXPLORATION_MIN = 0.1
* EXPLORATION_TEST = 0.02
* EXPLORATION_STEPS = 850000
DeepMind によるディープ畳み込みニューラル ネットワーク
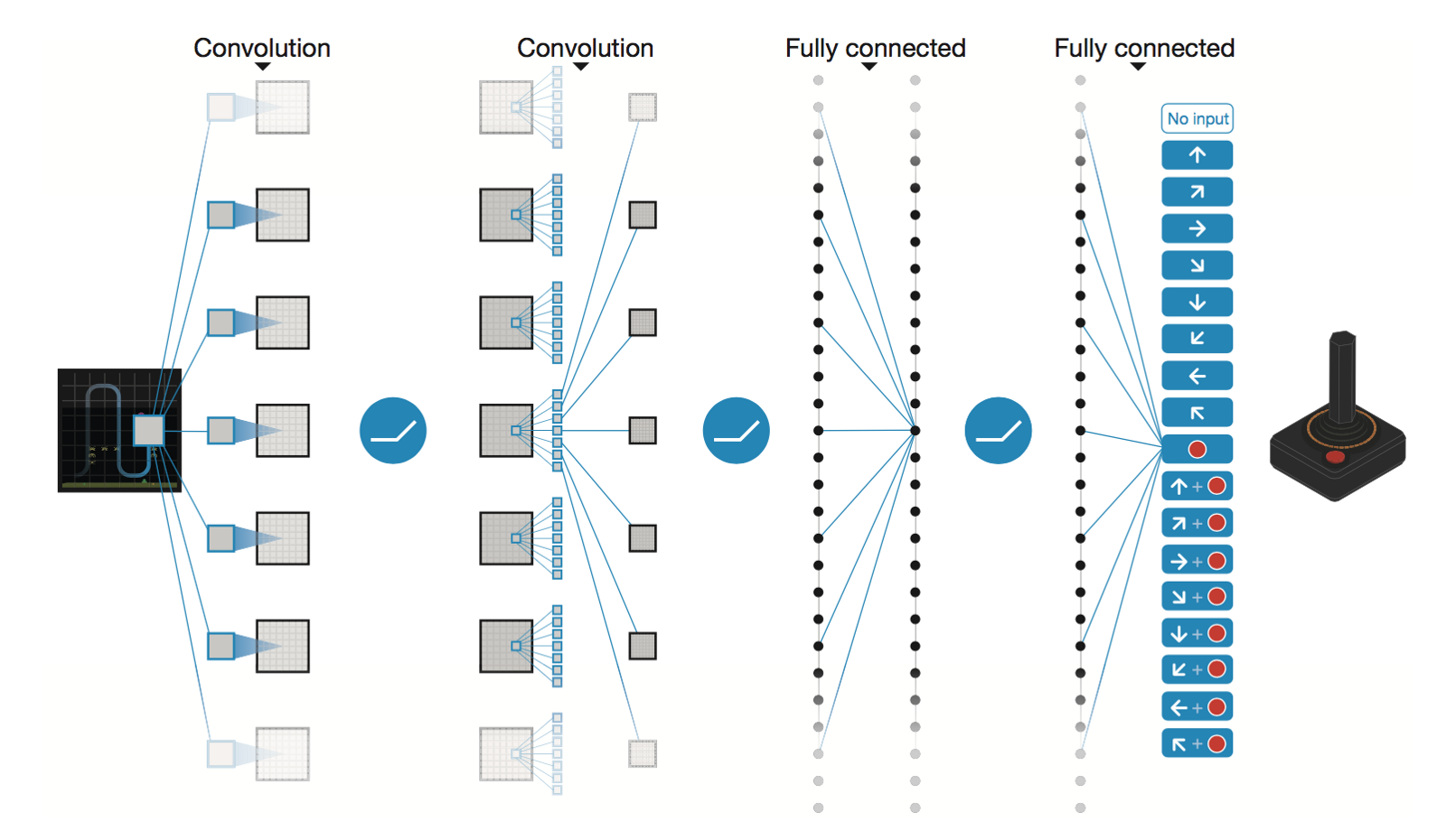
* Conv2D (None, 32, 20, 20)
* Conv2D (None, 64, 9, 9)
* Conv2D (None, 64, 7, 7)
* Flatten (None, 3136)
* Dense (None, 512)
* Dense (None, 4)
Trainable params: 1,686,180
500 万のステップ後 (Tesla K80 GPU で約 40 時間、または 2.9 GHz Intel i7 クアッドコア CPU で約 90 時間):
トレーニング:
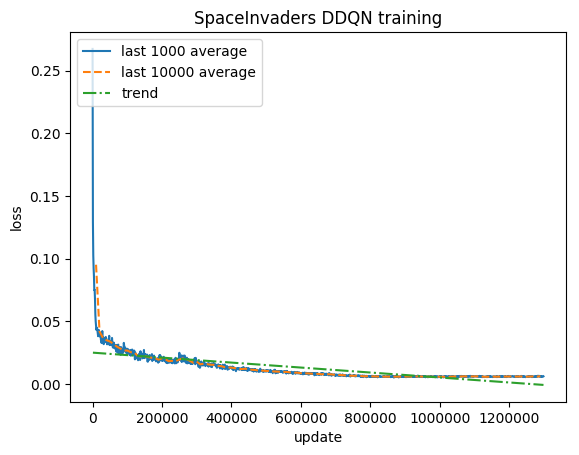
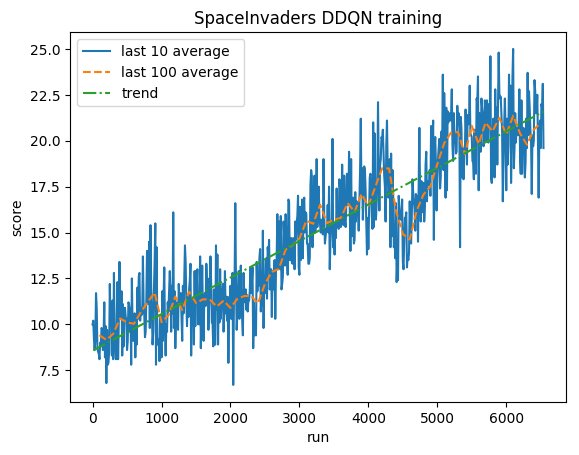
正規化されたスコア - 各報酬は (-1, 1) にクリップされます
テスト:
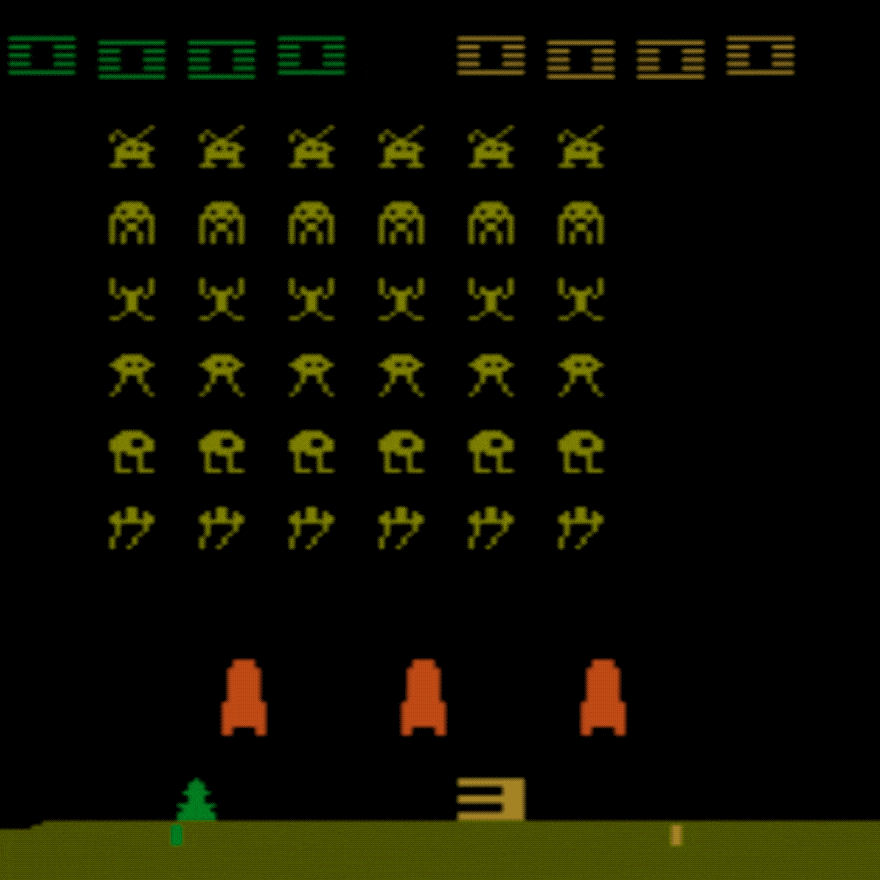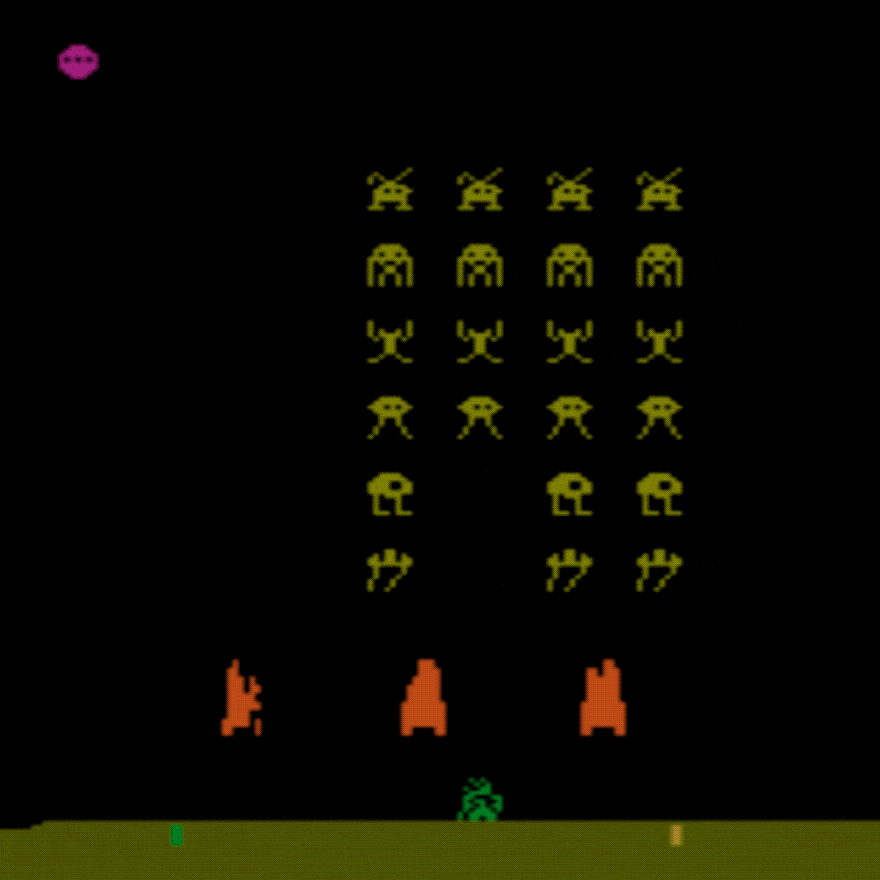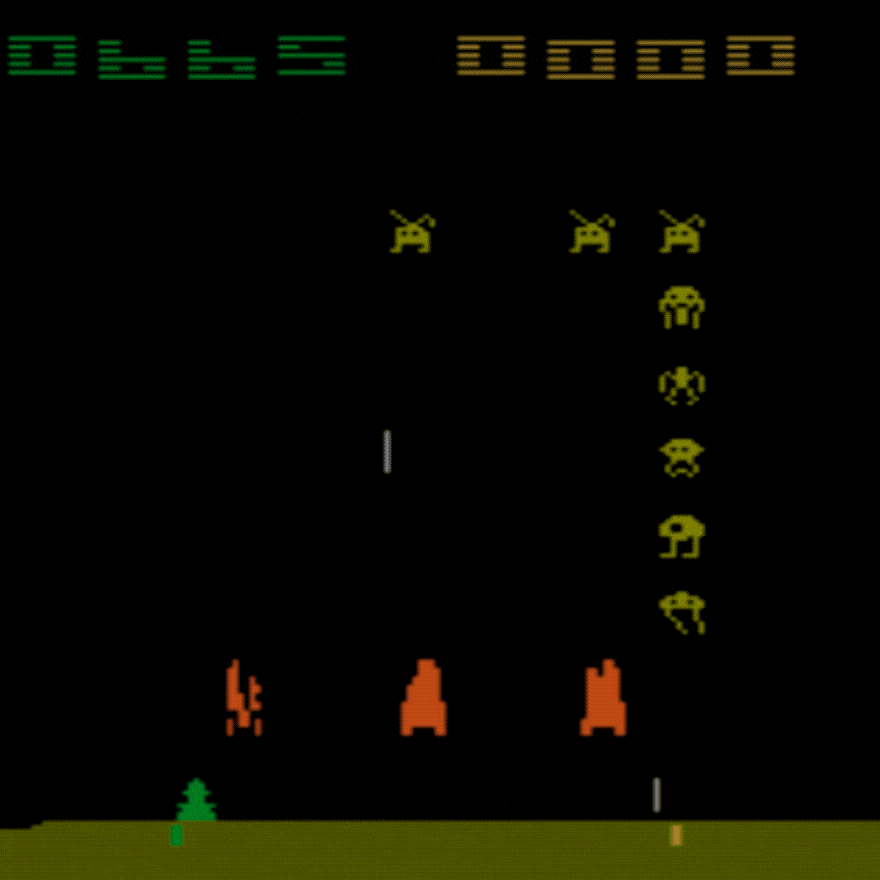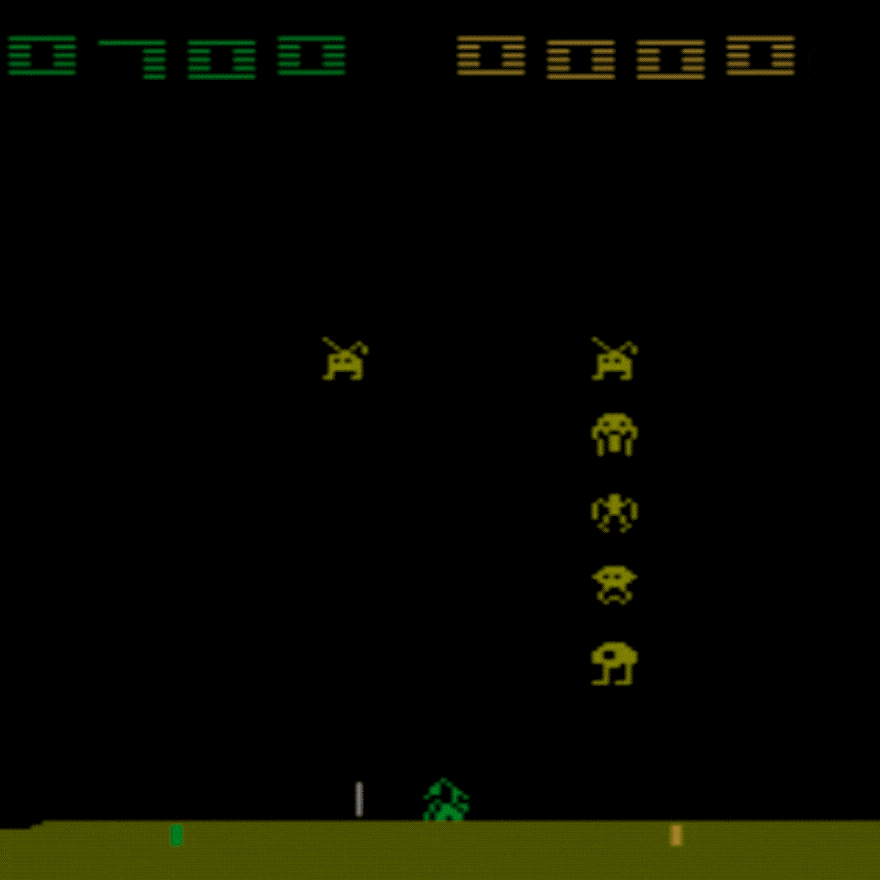
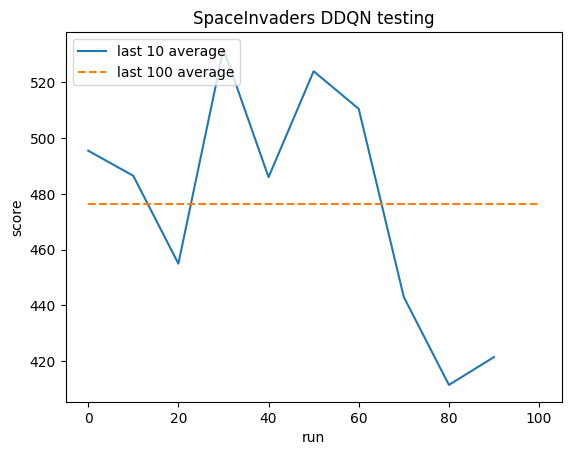
人間の平均: ~372
DDQN 平均: ~479 (128%)
トレーニング:
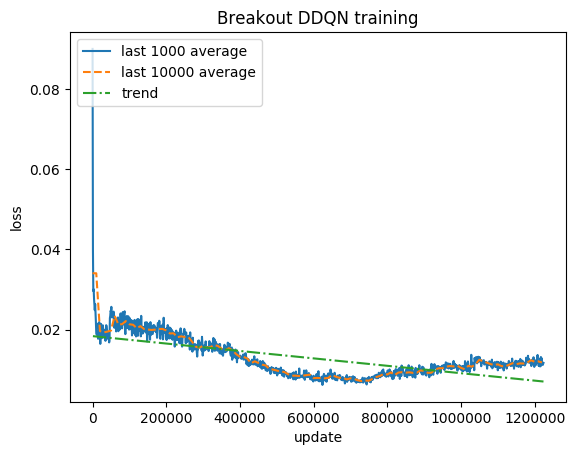
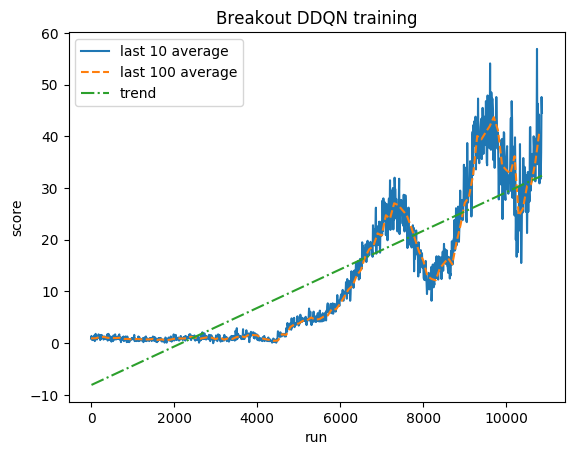
正規化されたスコア - 各報酬は (-1, 1) にクリップされます
テスト:
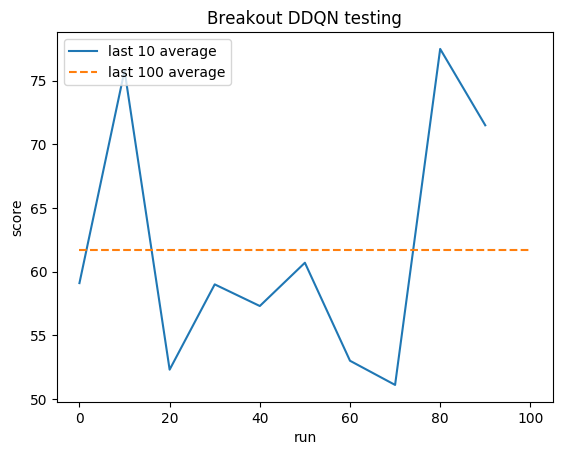
人間の平均: ~28
DDQN 平均: ~62 (221%)
トレーニング:
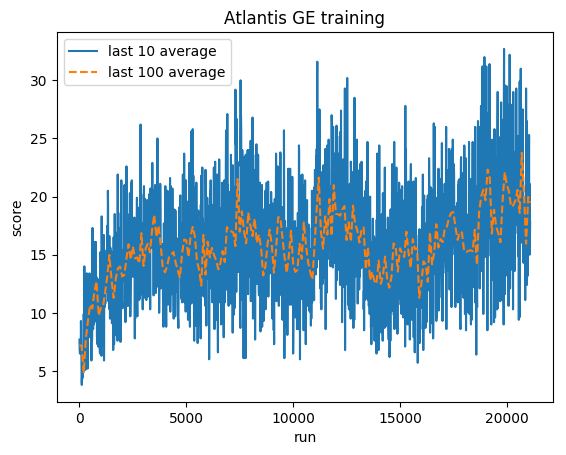
正規化されたスコア - 各報酬は (-1, 1) にクリップされます
テスト:

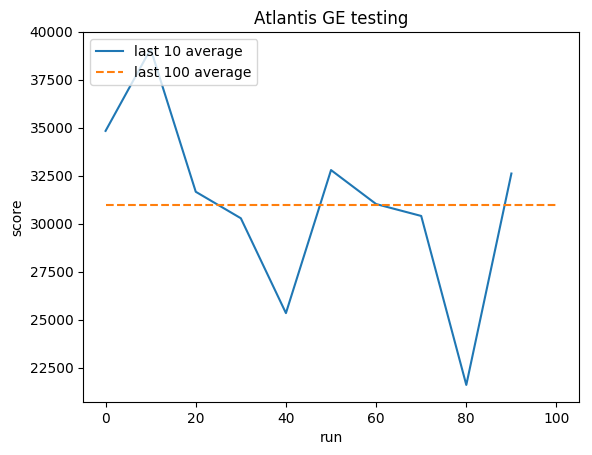
人間の平均: ~29,000
GE 平均: 31,000 (106%)
グレッグ (グゼゴシュ) スルマ
ポートフォリオ
ギットハブ
ブログ


