sinkhorn transformer
0.11.4
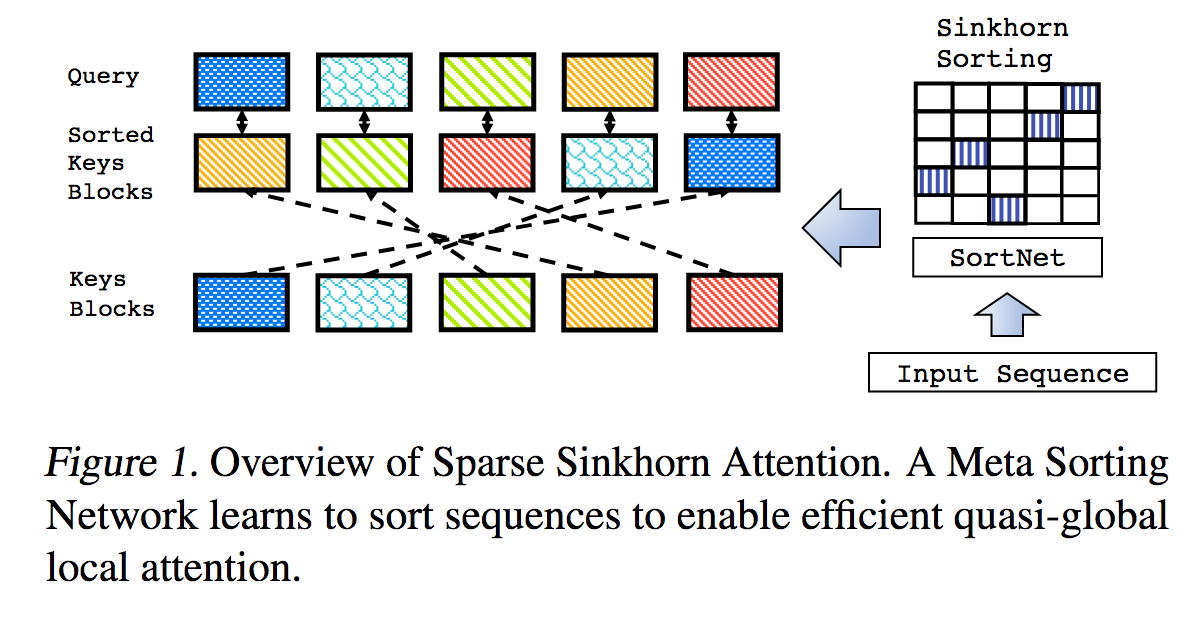
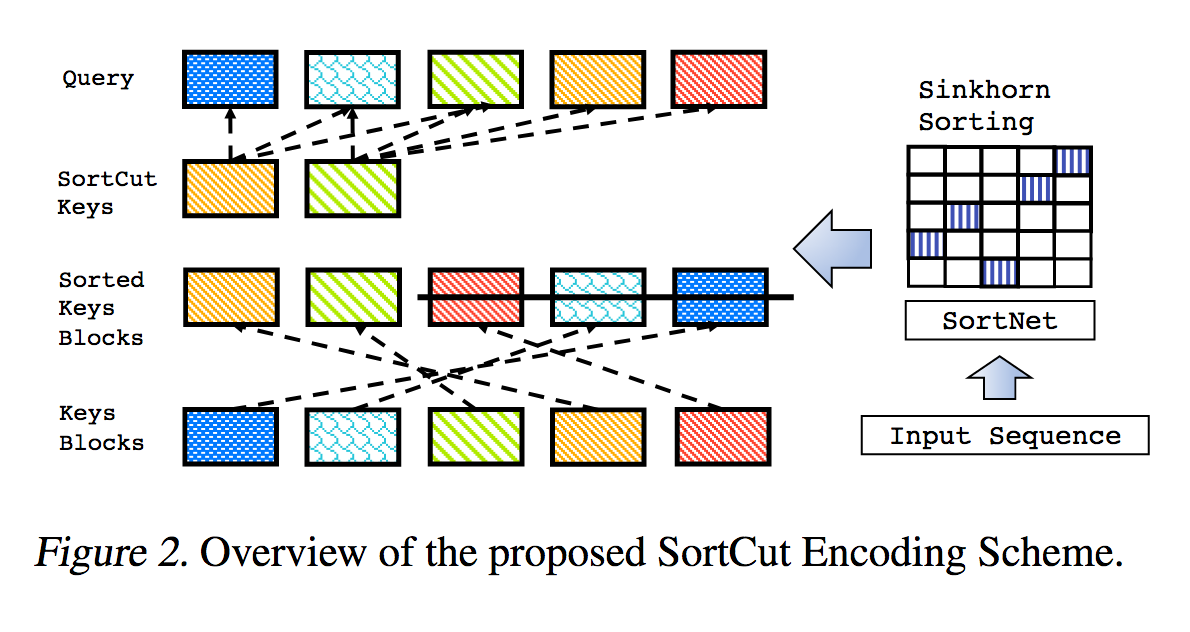
これは、「スパース・シンホーン・アテンション」で概説されている作品を、追加の機能拡張を加えて再現したものです。
これには、シンクホーン正規化を使用して、最も関連性の高いキーのバケットをクエリのバケットに一致させる順列行列をサンプリングする、パラメーター化された並べ替えネットワークが含まれています。
この取り組みでは、可逆ネットワークとフィード フォワード チャンキング (Reformer から導入された概念) も導入し、メモリをさらに節約します。
204k トークン (デモンストレーション目的)
$ pip install sinkhorn_transformerSinkhorn Transformer ベースの言語モデル
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 8192 ,
bucket_size = 128 , # size of the buckets
causal = False , # auto-regressive or not
n_sortcut = 2 , # use sortcut to reduce memory complexity to linear
n_top_buckets = 2 , # sort specified number of key/value buckets to one query bucket. paper is at 1, defaults to 2
ff_chunks = 10 , # feedforward chunking, from Reformer paper
reversible = True , # make network reversible, from Reformer paper
emb_dropout = 0.1 , # embedding dropout
ff_dropout = 0.1 , # feedforward dropout
attn_dropout = 0.1 , # post attention dropout
attn_layer_dropout = 0.1 , # post attention layer dropout
layer_dropout = 0.1 , # add layer dropout, from 'Reducing Transformer Depth on Demand' paper
weight_tie = True , # tie layer parameters, from Albert paper
emb_dim = 128 , # embedding factorization, from Albert paper
dim_head = 64 , # be able to fix the dimension of each head, making it independent of the embedding dimension and the number of heads
ff_glu = True , # use GLU in feedforward, from paper 'GLU Variants Improve Transformer'
n_local_attn_heads = 2 , # replace N heads with local attention, suggested to work well from Routing Transformer paper
pkm_layers = ( 4 , 7 ), # specify layers to use product key memory. paper shows 1 or 2 modules near the middle of the transformer is best
pkm_num_keys = 128 , # defaults to 128, but can be increased to 256 or 512 as memory allows
)
x = torch . randint ( 0 , 20000 , ( 1 , 2048 ))
model ( x ) # (1, 2048, 20000)シンプルな Sinkhorn Transformer、Sinkhorn の注目のレイヤー
import torch
from sinkhorn_transformer import SinkhornTransformer
model = SinkhornTransformer (
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128
)
x = torch . randn ( 1 , 2048 , 1024 )
model ( x ) # (1, 2048, 1024)シンクホーンエンコーダ/デコーダトランス
import torch
from sinkhorn_transformer import SinkhornTransformerLM
DE_SEQ_LEN = 4096
EN_SEQ_LEN = 4096
enc = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
heads = 8 ,
bucket_size = 128 ,
max_seq_len = DE_SEQ_LEN ,
reversible = True ,
return_embeddings = True
). cuda ()
dec = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
causal = True ,
bucket_size = 128 ,
max_seq_len = EN_SEQ_LEN ,
receives_context = True ,
context_bucket_size = 128 , # context key / values can be bucketed differently
reversible = True
). cuda ()
x = torch . randint ( 0 , 20000 , ( 1 , DE_SEQ_LEN )). cuda ()
y = torch . randint ( 0 , 20000 , ( 1 , EN_SEQ_LEN )). cuda ()
x_mask = torch . ones_like ( x ). bool (). cuda ()
y_mask = torch . ones_like ( y ). bool (). cuda ()
context = enc ( x , input_mask = x_mask )
dec ( y , context = context , input_mask = y_mask , context_mask = x_mask ) # (1, 4096, 20000) デフォルトでは、バケット サイズの倍数ではない入力が与えられた場合、モデルはエラーを出します。毎回同じパディング計算を行う必要を避けるために、ヘルパーAutopadderクラスを使用できます。 input_maskが指定されている場合は、それも処理します。コンテキストキー/値およびマスクもサポートされています。
import torch
from sinkhorn_transformer import SinkhornTransformerLM
from sinkhorn_transformer import Autopadder
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 2048 ,
bucket_size = 128 ,
causal = True
)
model = Autopadder ( model , pad_left = True ) # autopadder will fetch the bucket size and autopad input
x = torch . randint ( 0 , 20000 , ( 1 , 1117 )) # odd sequence length
model ( x ) # (1, 1117, 20000) このリポジトリは論文から分岐し、現在は元の選別ネット + ガンベル シンクホーン サンプリングの代わりに注目を集めています。パフォーマンスに目立った違いはまだ見つかっていませんが、新しいスキームにより、ネットワークを柔軟なシーケンス長に一般化することができます。 Sinkhorn を試してみたい場合は、次の設定を使用してください。これは非因果的ネットワークでのみ機能します。
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128 ,
max_seq_len = 8192 ,
use_simple_sort_net = True , # turn off attention sort net
sinkhorn_iter = 7 , # number of sinkhorn iterations - default is set at reported best in paper
n_sortcut = 2 , # use sortcut to reduce complexity to linear time
temperature = 0.75 , # gumbel temperature - default is set at reported best in paper
non_permutative = False , # allow buckets of keys to be sorted to queries more than once
)
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
model ( x ) # (1, 8192, 20000) PKM を使用する利点を確認するには、値の学習率を他のパラメーターよりも高く設定する必要があります。 ( 1e-2を推奨)
ここの手順に従って正しく設定できます https://github.com/lucidrains/product-key-memory#learning-rates
Sinkhorn は、固定長シーケンスでトレーニングされた場合、シーケンスを最初からデコードするのに苦労するようです。これは主に、バケットがパディング トークンで部分的に満たされている場合にソート ネットが一般化するのに苦労するという事実によるものです。
幸いなことに、私は簡単な解決策を見つけたと思います。トレーニング中に、因果関係ネットワークの場合、シーケンスをランダムに切り捨て、ソート ネットを強制的に一般化します。これを簡単にするために、 AutoregressiveWrapperインスタンスにフラグ ( randomly_truncate_sequence ) を提供しました。
import torch
from sinkhorn_transformer import SinkhornTransformerLM , AutoregressiveWrapper
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 75 ,
max_seq_len = 8192 ,
causal = True
)
model = AutoregressiveWrapper ( model )
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
loss = model ( x , return_loss = True , randomly_truncate_sequence = True ) # (1, 8192, 20000)誰かがより良い解決策を見つけた場合は、提案を歓迎します。
因果的ソート ネットワークには潜在的な問題があり、過去のどのキー/値バケットをバケットにソートするかの決定が、最初のトークンのみに依存し、残りのトークンには依存しません (バケット化スキームと将来のトークンの漏洩を防ぐため)。過去)。
私は、ヘッドの半分をバケット サイズ - 1 だけ左に回転させ、それによって最後のトークンが先頭になるようにすることで、この問題を軽減しようとしました。これは、シーケンス内の最後のトークンが何を取得するかを常に決定するために、 AutoregressiveWrapperトレーニング中にデフォルトで左パディングを行う理由でもあります。
誰かがよりクリーンな解決策を見つけた場合は、問題で私に知らせてください。
@misc { tay2020sparse ,
title = { Sparse Sinkhorn Attention } ,
author = { Yi Tay and Dara Bahri and Liu Yang and Donald Metzler and Da-Cheng Juan } ,
year = { 2020 } ,
url. = { https://arxiv.org/abs/2002.11296 }
} @inproceedings { kitaev2020reformer ,
title = { Reformer: The Efficient Transformer } ,
author = { Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=rkgNKkHtvB }
} @misc { lan2019albert ,
title = { ALBERT: A Lite BERT for Self-supervised Learning of Language Representations } ,
author = { Zhenzhong Lan and Mingda Chen and Sebastian Goodman and Kevin Gimpel and Piyush Sharma and Radu Soricut } ,
year = { 2019 } ,
url = { https://arxiv.org/abs/1909.11942 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=B1gjs6EtDr }
} @inproceedings { fan2020reducing ,
title = { Reducing Transformer Depth on Demand with Structured Dropout } ,
author = { Angela Fan and Edouard Grave and Armand Joulin } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=SylO2yStDr }
} @misc { lample2019large ,
title = { Large Memory Layers with Product Keys } ,
author = { Guillaume Lample and Alexandre Sablayrolles and Marc'Aurelio Ranzato and Ludovic Denoyer and Hervé Jégou } ,
year = { 2019 } ,
eprint = { 1907.05242 } ,
archivePrefix = { arXiv }
} @misc { bhojanapalli2020lowrank ,
title = { Low-Rank Bottleneck in Multi-head Attention Models } ,
author = { Srinadh Bhojanapalli and Chulhee Yun and Ankit Singh Rawat and Sashank J. Reddi and Sanjiv Kumar } ,
year = { 2020 } ,
eprint = { 2002.07028 }
}


