awesome mojo
1.0.0

Mojo — すべての開発者、AI/ML 科学者、ソフトウェア エンジニアのための新しいプログラミング言語。
素晴らしい Mojo コード、問題解決、ソリューション、そして将来のライブラリ、フレームワーク、ソフトウェア、リソースの厳選されたリスト。
ここで非常に新しいテクノロジーの知識とベストプラクティスを蓄積しましょう。
Mojo は、Python の使いやすさと C++ および Rust のパフォーマンス機能を組み合わせたプログラミング言語です。さらに、Mojo を使用すると、ユーザーは Python ライブラリの広大なエコシステムを利用できます。
簡単に言うと
Mojo は、Python 構文の優れた部分とシステム プログラミングおよびメタプログラミングを組み合わせることにより、研究と運用の間のギャップを埋める新しいプログラミング言語です。
こんにちは。 hello.mojoまたはhello.ファイル拡張子には絵文字を使用できます。
Modular がこれを行う理由について詳しくは、「なぜ Mojo を使用するのか」をご覧ください。
私たちが望んでいたのは、AI 分野で普及しているアクセラレータやその他の異種システムをターゲットにできる、革新的でスケーラブルなプログラミング モデルでした。 ... 応用 AI システムはこれらすべての問題に対処する必要があり、1 つの言語だけで解決できない理由はないと判断しました。こうしてモジョが誕生しました。
しかし、Python はその仕事を非常にうまくやっています =)
私たちは言語構文やコミュニティを革新する必要性を感じませんでした。そこで私たちは Python エコシステムを採用することにしました。Python エコシステムは非常に広く使用されており、AI エコシステムに愛されており、非常に優れた言語であると信じているからです。
モジョとは「魔法の魅力」または「魔法の力」を意味します。私たちは、これが Python :python: に魔法の力をもたらす言語にふさわしい名前だと考えました。これには、今日の AI に普及しているアクセラレータやその他の異種システムのための革新的なプログラミング モデルのロックを解除することも含まれます。
グイド・ファン・ロッサムは慈悲深い終身独裁者であり、クリストファー・アーサー・ラトナーはモジョ発音の著名な発明者、創造者、著名な指導者です =)
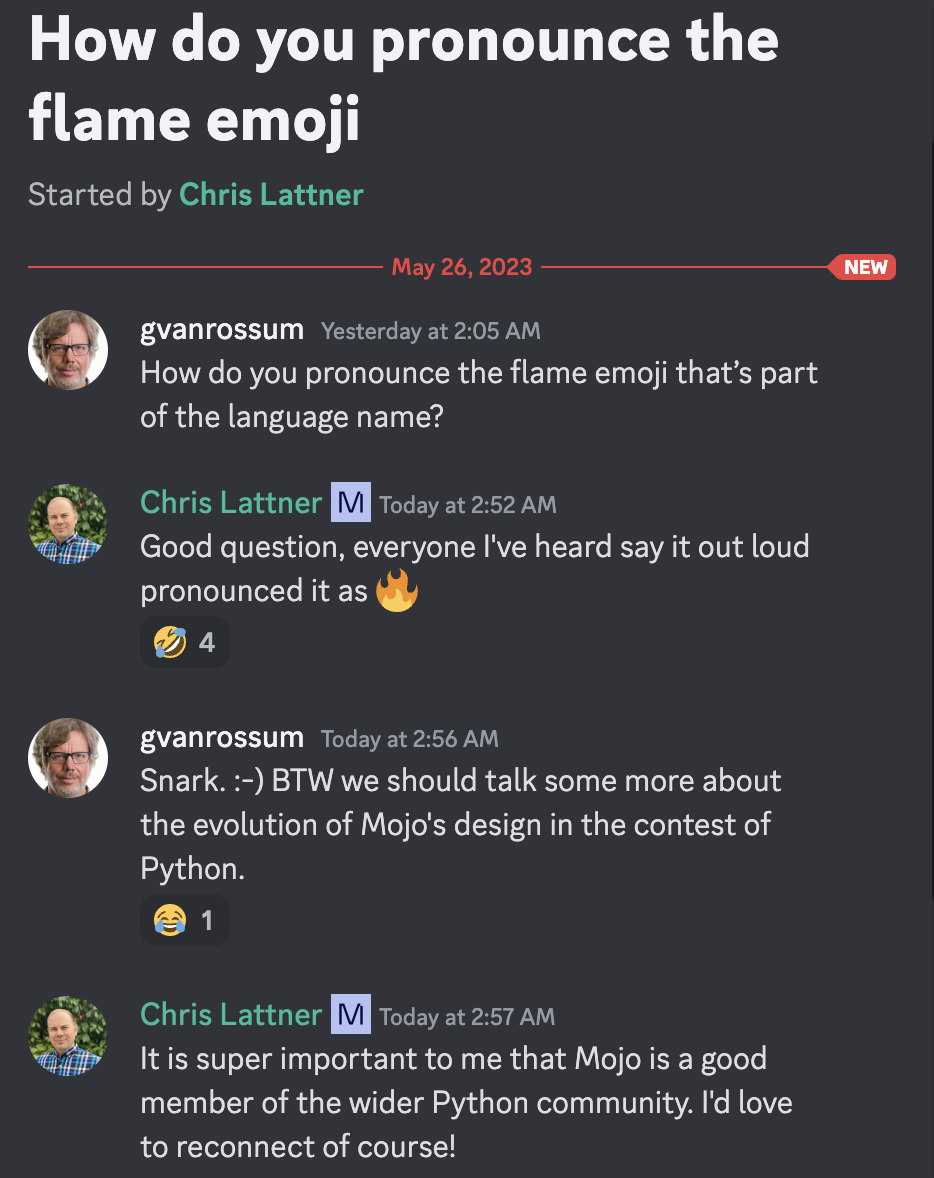
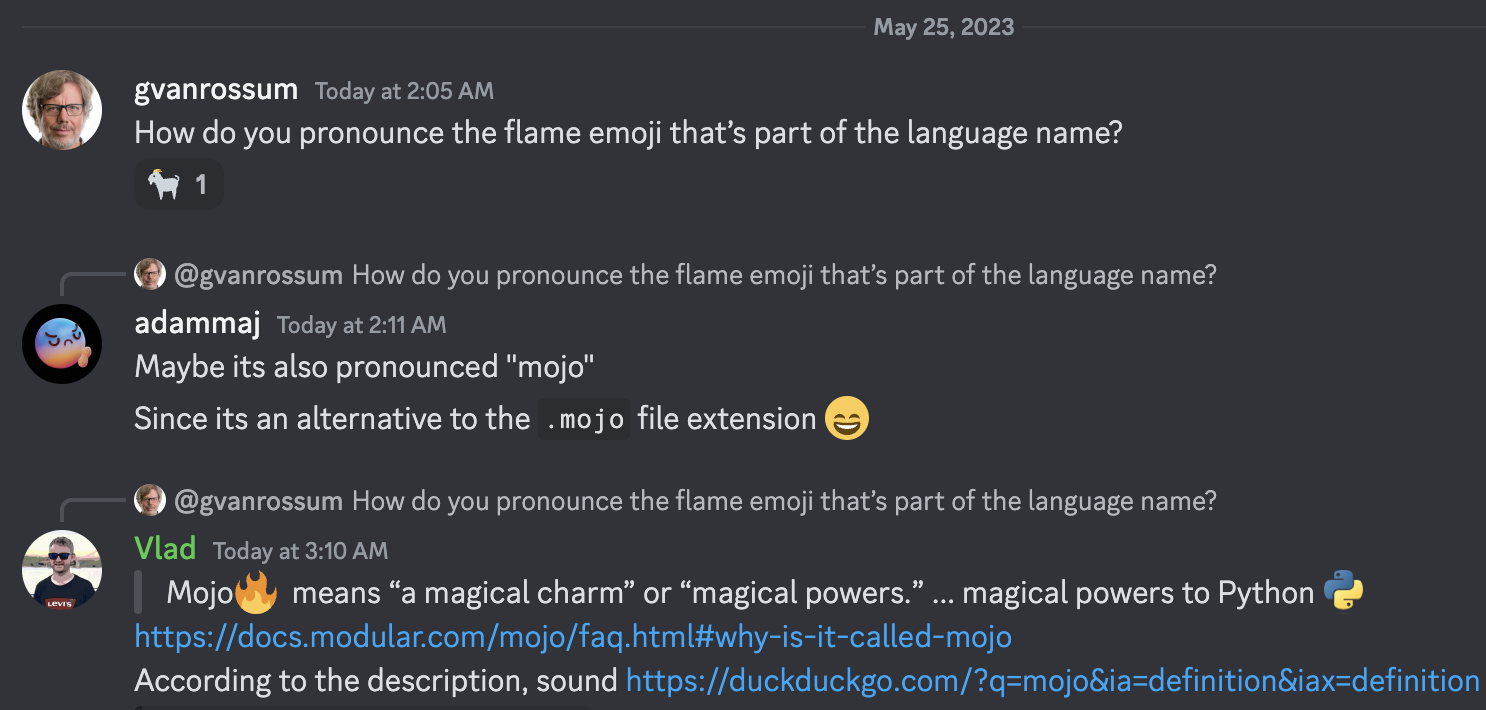
説明によると
Mojo は、Rust、Swift、Julia、Zig、Nim などの他の言語から学んだ多大な教訓から恩恵を受けているため、これらのプログラミング言語が非常に幸せになることは誰にもわかりません。
[新しい]
Github が Mojo コードを自動検出するようになりました。
Mojo 用のシンプルで高速な HTTP フレームワーク! Web サービスや単純な API の構築に最適です。モジシャン向け
LLama 実装ベンチマーク フレームワーク
Python から Mojo コードへの自動変換
プログラミング言語データベースの研究
2023 年 10 月 19 日 Mojo が Mac で利用できるようになりました。開発者コンソールを使用する
Chris Lattner: プログラミングと AI の未来 |レックス・フリッドマン ポッドキャスト #381
Mojo と Python の型システムの説明 |クリス・ラトナーとレックス・フリッドマン
Mojo は Python コードを実行できますか? |クリス・ラトナーとレックス・フリッドマン
Python から Mojo プログラミング言語への切り替え |クリス・ラトナーとレックス・フリッドマン
新しい GitHub トピック mojo-lang。それであなたはそれに従うことができます。
Guido van Rossum は Mojo = C++/GPU パフォーマンスを備えた Python について語りますか?
いくつかの基本的な演算を含む Tensor 構造体 #251
numpy を使用した行列 fn #267
mojo #244 のlambdaとparameterクロージャと高次関数に関する更新
2023 年 5 月 25 日、Python の作成者および名誉 BDFL である Guido van Rossum (gvanrossum#8415) が Mojo パブリック Discord チャットを訪問
GitHub で Mojo 構文ハイライトを待っています
新しい Mojo リリース 2023-05-24
[古い]
モジョ
brew install hyperfinebrew install macchinapip3 install numpy matplotlib scipybrew install silicon
Python / Mojo / Codon / Rustのバージョン
> python3 --version
Python 3.11.6
> mojo --version
mojo 0.4.0 (9e33b013)
> codon --version
0.16.3
> rustc --version
rustc 1.65.0-nightly (9243168fa 2022-08-31)フィボナッチ数列を見つけてみましょう。
N = 100
def fibonacci_recursion ( n ):
return n if n < 2 else fibonacci_recursion ( n - 1 ) + fibonacci_recursion ( n - 2 )
fibonacci_recursion ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json python_recursion.json ' python3 benchmarks/fibonacci_sequence/python_recursion.py '結果: タイムアウト、1 分後に計算をキャンセルしました
def fibonacci_iteration ( n ):
a , b = 0 , 1
for _ in range ( n ):
a , b = b , a + b
return a
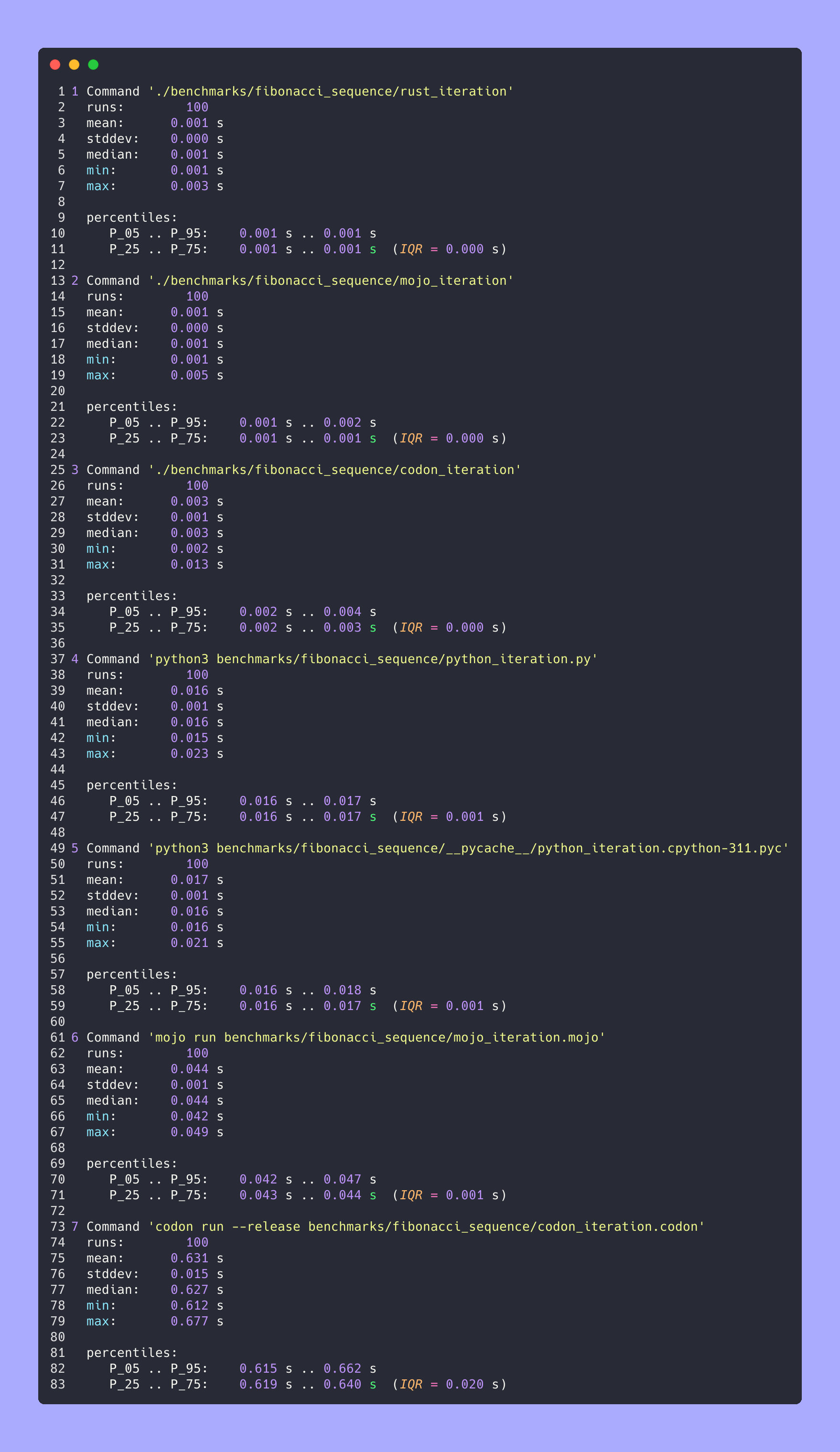
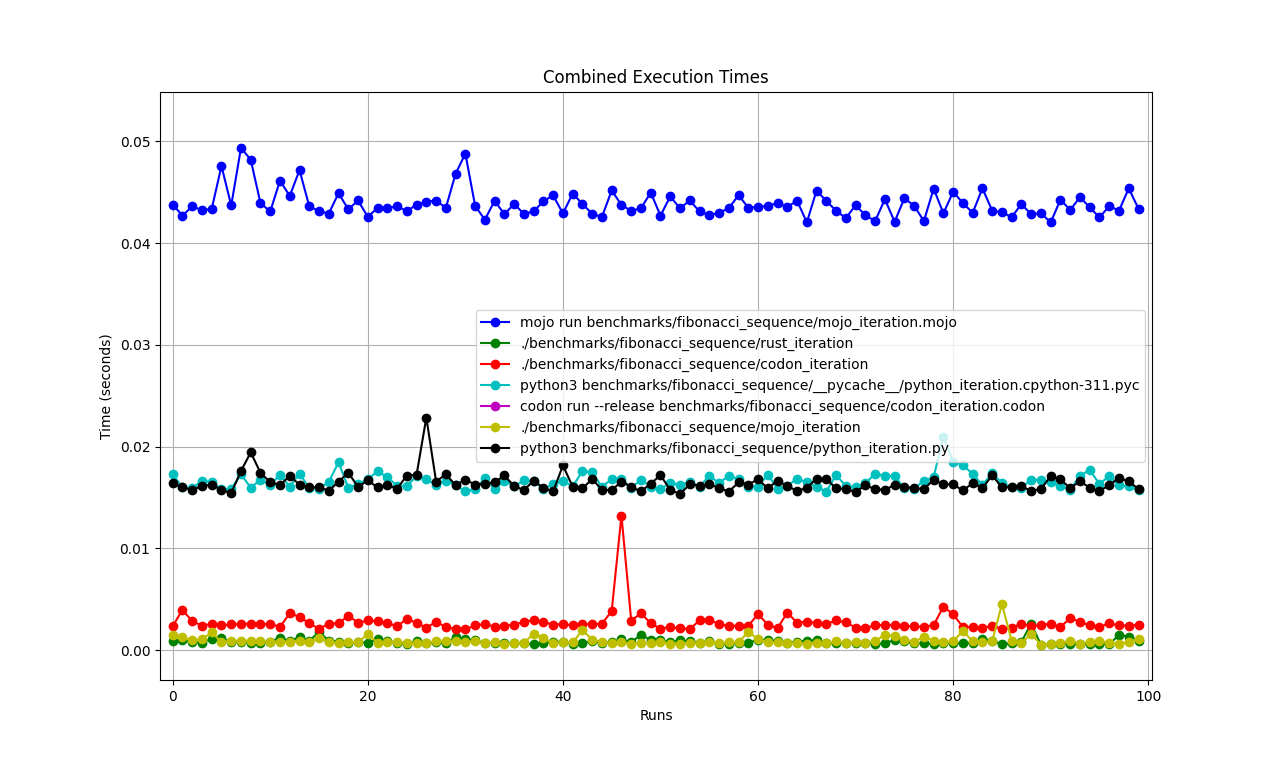
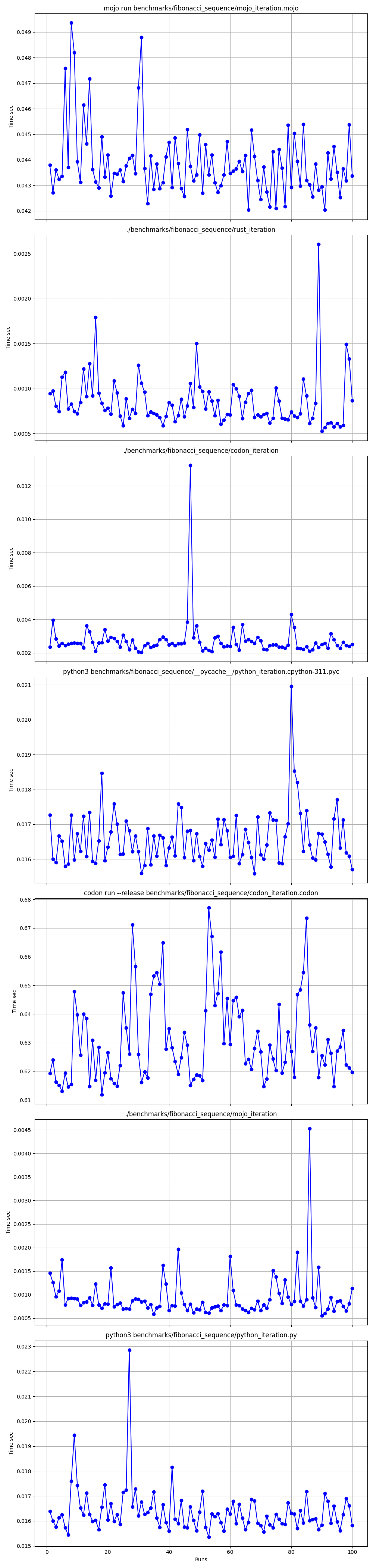
fibonacci_iteration ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.json ' python3 benchmarks/fibonacci_sequence/python_iteration.py '結果:
ベンチマーク 1: python3 ベンチマーク/fibonacci_sequence/python_iteration.py
時間 (平均 ± σ): 16374.7 μs ± 904.0 μs [ユーザー: 11483.5 μs、システム: 3680.0 μs]
範囲 (最小 … 最大): 15361.0 μs … 22863.3 μs 100 回の実行
python3 -m compileall benchmarks/fibonacci_sequence/python_recursion.py
python3 -m compileall benchmarks/fibonacci_sequence/python_iteration.pyhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_recursion.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_recursion.cpython-311.pyc '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_iteration.cpython-311.pyc '結果:
ベンチマーク 1: python3 ベンチマーク/fibonacci_sequence/ pycache /python_iteration.cpython-311.pyc
時間 (平均 ± σ): 16584.6 μs ± 761.5 μs [ユーザー: 11451.8 μs、システム: 3813.3 μs]
範囲 (最小 … 最大): 15592.0 μs … 20953.2 μs 100 回の実行
fn fibonacci_recursion ( n : Int) -> Int:
return n if n < 2 else fibonacci_recursion(n - 1 ) + fibonacci_recursion(n - 2 )
fn main ():
_ = fibonacci_recursion( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.json ' mojo run benchmarks/fibonacci_sequence/mojo_recursion.mojo '結果: タイムアウト、1 分後に計算をキャンセルしました
fn fibonacci_iteration ( n : Int) -> Int:
var a : Int = 0
var b : Int = 1
for _ in range (n):
a = b
b = a + b
return a
fn main ():
_ = fibonacci_iteration( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.json ' mojo run benchmarks/fibonacci_sequence/mojo_iteration.mojo '結果:
ベンチマーク 1: mojo 実行ベンチマーク/fibonacci_sequence/mojo_iteration.mojo
時間 (平均 ± σ): 43852.7 μs ± 1353.5 μs [ユーザー: 38156.0 μs、システム: 10407.3 μs]
範囲 (最小 … 最大): 42033.6 μs … 49357.3 μs 100 回の実行
mojo build benchmarks/fibonacci_sequence/mojo_recursion.mojo
mojo build benchmarks/fibonacci_sequence/mojo_iteration.mojohyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.exe.json ' ./benchmarks/fibonacci_sequence/mojo_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.exe.json ' ./benchmarks/fibonacci_sequence/mojo_iteration '結果:
ベンチマーク 1: ./benchmarks/fibonacci_sequence/mojo_iteration
時間 (平均 ± σ): 934.6 μs ± 468.9 μs [ユーザー: 409.8 μs、システム: 247.8 μs]
範囲 (最小 … 最大): 552.7 μs … 4522.9 μs 100 回の実行
def fibonacci_recursion(n):
return n if n < 2 else fibonacci_recursion(n - 1) + fibonacci_recursion(n - 2)
fibonacci_recursion(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_recursion.json ' codon run --release benchmarks/fibonacci_sequence/codon_recursion.codon '結果: タイムアウト、1 分後に計算をキャンセルしました
def fibonacci_iteration(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a+b
return a
fibonacci_iteration(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.json ' codon run --release benchmarks/fibonacci_sequence/codon_iteration.codon '結果:
ベンチマーク 1: コドン実行 --release benchmarks/fibonacci_sequence/codon_iteration.codon
時間 (平均 ± σ): 628060.1 μs ± 10430.5 μs [ユーザー: 584524.3 μs、システム: 39358.5 μs]
範囲 (最小 … 最大): 612742.5 μs … 662716.9 μs 100 実行
codon build --release -exe benchmarks/fibonacci_sequence/codon_recursion.codon
codon build --release -exe benchmarks/fibonacci_sequence/codon_iteration.codonhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json codon_recursion.exe.json ' ./benchmarks/fibonacci_sequence/codon_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.exe.json ' ./benchmarks/fibonacci_sequence/codon_iteration '結果:
ベンチマーク 1: ./benchmarks/fibonacci_sequence/codon_iteration
時間 (平均 ± σ): 2732.7 μs ± 1145.5 μs [ユーザー: 1466.0 μs、システム: 1061.5 μs]
範囲 (最小 … 最大): 2036.6 μs … 13236.3 μs 100 回の実行
fn fibonacci_recursive ( n : i64 ) -> i64 {
if n < 2 {
return n ;
}
return fibonacci_recursive ( n - 1 ) + fibonacci_recursive ( n - 2 ) ;
}
fn main ( ) {
let _ = fibonacci_recursive ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_recursion.rs -o benchmarks/fibonacci_sequence/rust_recursion
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_recursion.json ' ./benchmarks/fibonacci_sequence/rust_recursion '結果: タイムアウト、1 分後に計算をキャンセルしました
fn fibonacci_iteration ( n : usize ) -> usize {
let mut a = 1 ;
let mut b = 1 ;
for _ in 1 ..n {
let old = a ;
a = b ;
b += old ;
}
b
}
fn main ( ) {
let _ = fibonacci_iteration ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_iteration.rs -o benchmarks/fibonacci_sequence/rust_iteration
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_iteration.json ' ./benchmarks/fibonacci_sequence/rust_iteration '結果:
ベンチマーク 1: ./benchmarks/fibonacci_sequence/rust_iteration
時間 (平均 ± σ): 848.9 μs ± 283.2 μs [ユーザー: 371.8 μs、システム: 261.4 μs]
範囲 (最小 … 最大): 525.9 μs … 2607.3 μs 100 回の実行
# Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/fibonacci_sequence/ benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/fibonacci_sequence/benchmarks.json > benchmarks/fibonacci_sequence/benchmarks.json.md
silicon benchmarks/fibonacci_sequence/benchmarks.json.md -l python -o benchmarks/fibonacci_sequence/benchmarks.json.md.png高度な統計
みんなで一緒に
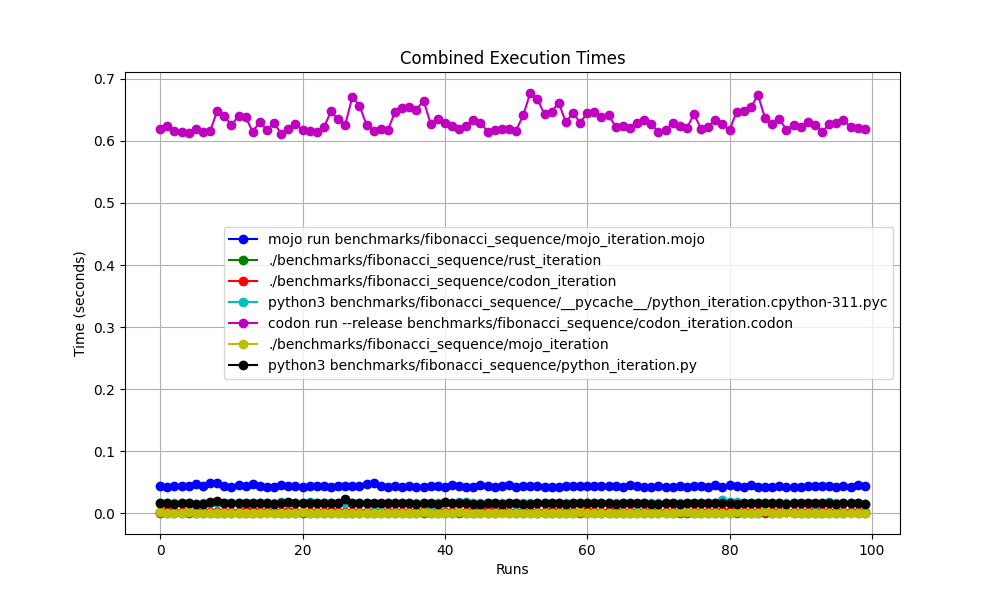
ズームした
ひとつひとつ詳しく
場所
しかし、ここで多くの疑問が生じます。
mojo run ?codon run --releaseこんなに遅いのでしょうか?runのはなぜですか?したがって、Mojo は Mac 上の Rust と同じくらい速いと言えます。
マンデルブロ集合を見つけてみましょう。
幅 = 960
高さ = 960
MAX_ITERS = 200
MIN_X = -2.0
MAX_X = 0.6
MIN_Y = -1.5
MAX_Y = 1.5
def mandelbrot_kernel ( c ):
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z . real * z . real + z . imag * z . imag > 4 :
return i
return MAX_ITERS
def compute_mandelbrot ():
t = [[ 0 for _ in range ( WIDTH )] for _ in range ( HEIGHT )] # Pixel matrix
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
for row in range ( HEIGHT ):
for col in range ( WIDTH ):
t [ row ][ col ] = mandelbrot_kernel ( complex ( MIN_X + col * dx , MIN_Y + row * dy ))
return t
compute_mandelbrot ()python3 -m compileall benchmarks/multibrot_set/multibrot.py
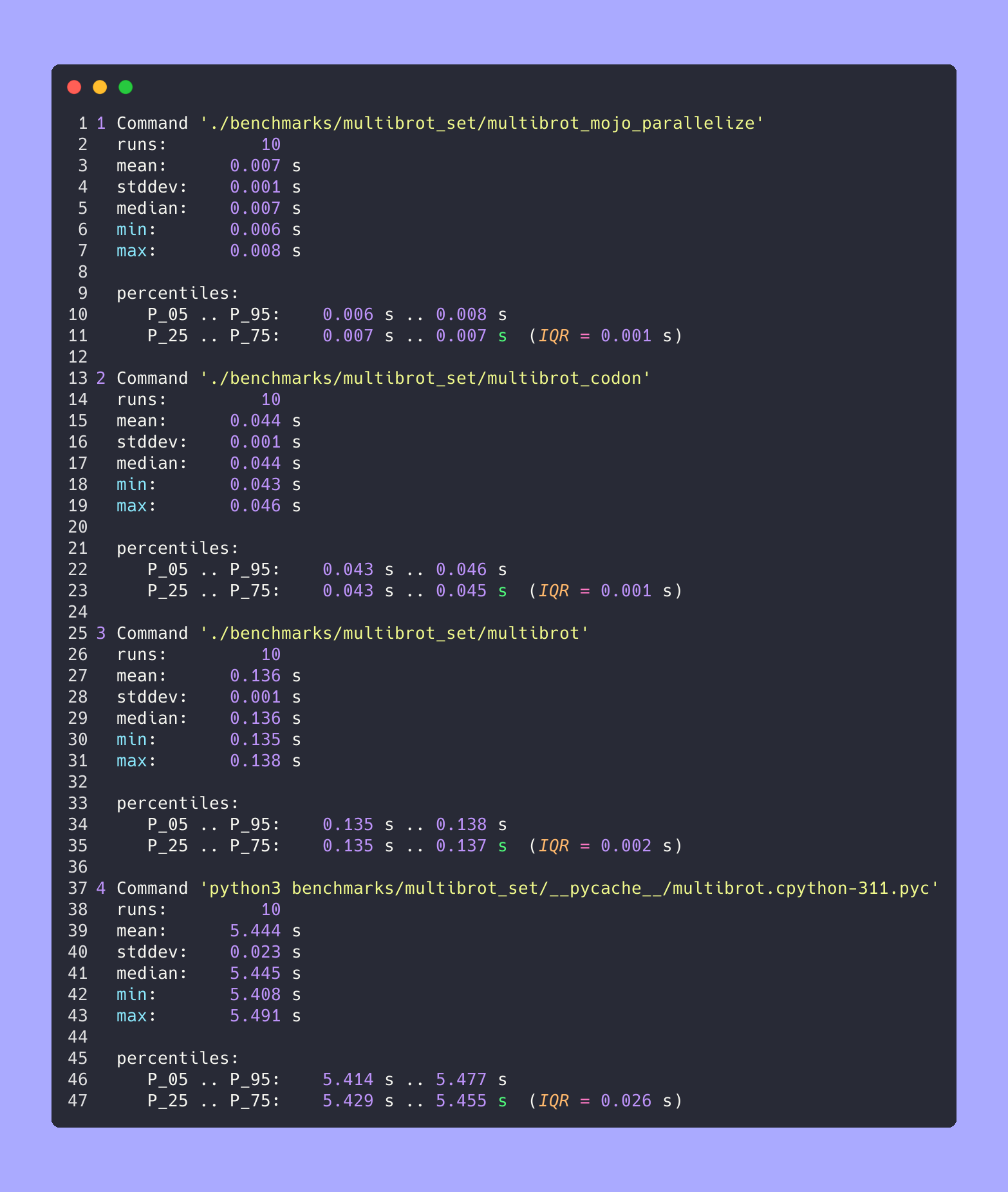
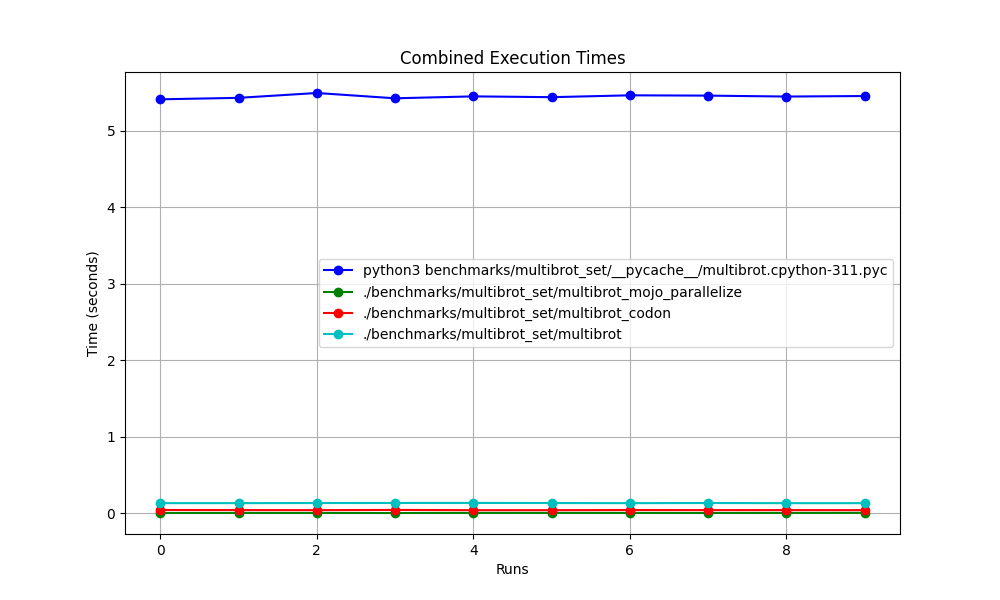
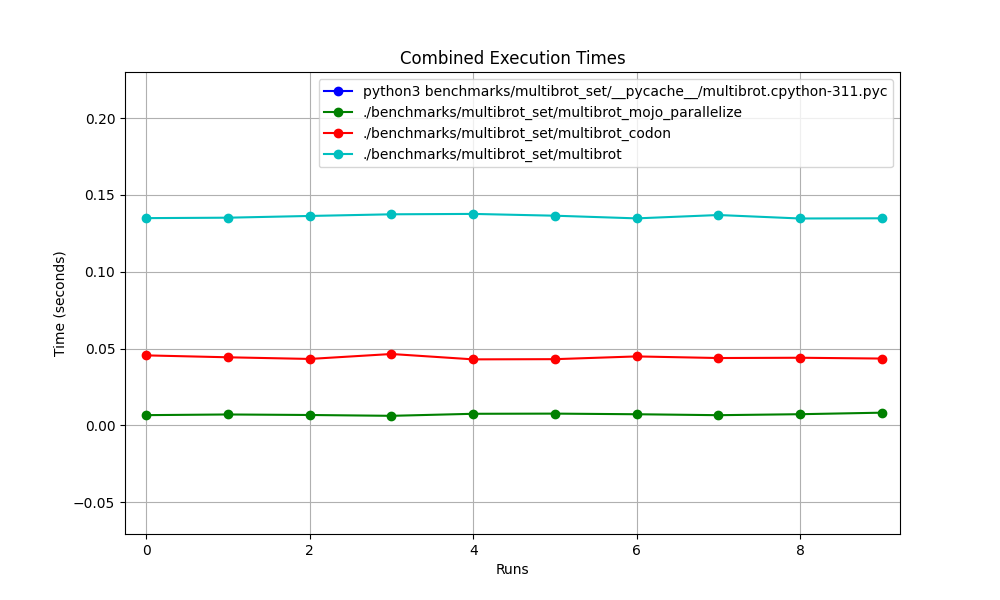
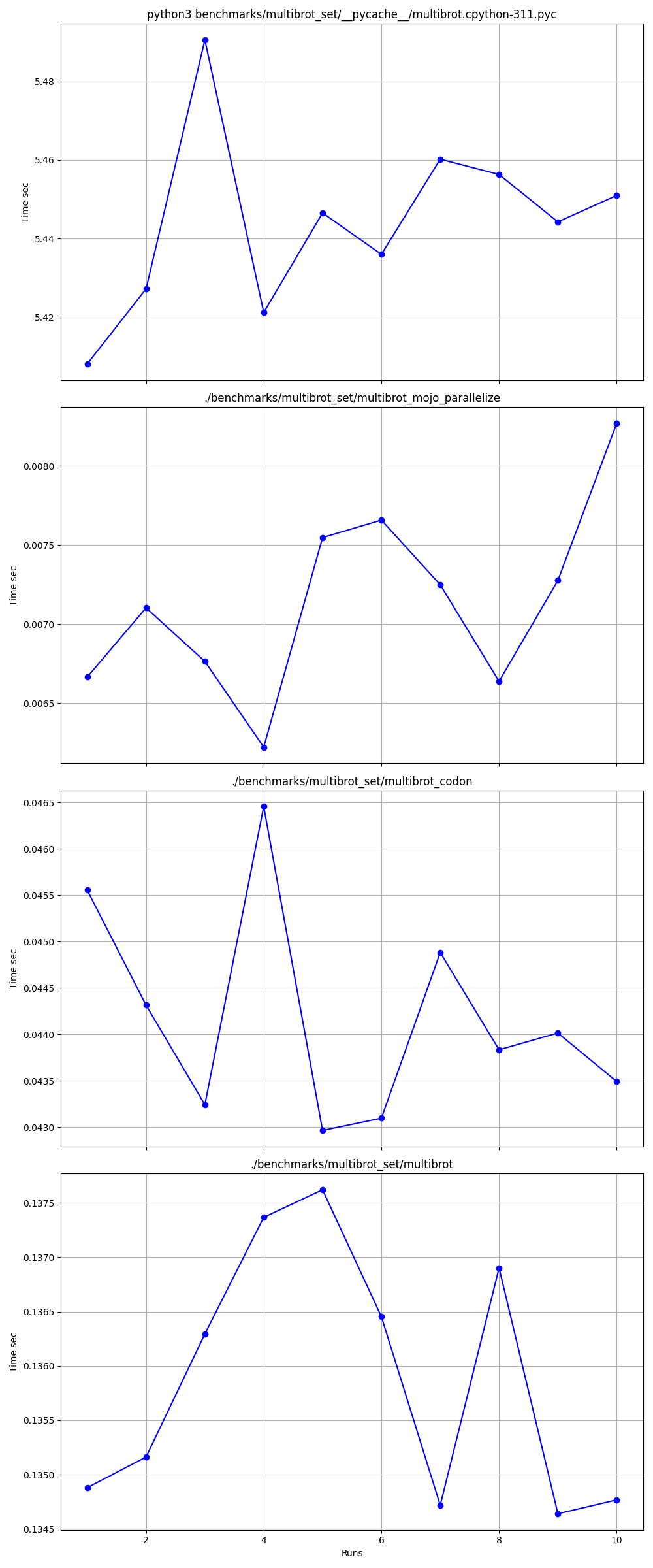
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.cpython-311.json ' python3 benchmarks/multibrot_set/__pycache__/multibrot.cpython-311.pyc '結果:
ベンチマーク 1: python3 ベンチマーク/multibrot_set/ pycache /multibrot.cpython-311.pyc
時間 (平均 ± σ): 5444155.4 μs ± 23059.7 μs [ユーザー: 5419790.1 μs、システム: 18131.3 μs]
範囲 (最小 … 最大): 5408155.3 μs … 5490548.4 μs 10 実行
最適化されていない Mojo バージョン。
# Compute the number of steps to escape.
def multibrot_kernel ( c : ComplexFloat64) -> Int:
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.squared_norm() > 4 :
return i
return MAX_ITERS
def compute_multibrot () -> Tensor[FloatType]:
# create a matrix. Each element of the matrix corresponds to a pixel
t = Tensor[FloatType]( HEIGHT , WIDTH )
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
y = MIN_Y
for row in range ( HEIGHT ):
x = MIN_X
for col in range ( WIDTH ):
t[Index(row, col)] = multibrot_kernel(ComplexFloat64(x, y))
x += dx
y += dy
return t
_ = compute_multibrot()mojo build benchmarks/multibrot_set/multibrot.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.exe.json ' ./benchmarks/multibrot_set/multibrot '結果:
ベンチマーク 1: ./benchmarks/multibrot_set/multibrot
時間 (平均 ± σ): 135880.5 μs ± 1175.4 μs [ユーザー: 133309.3 μs、システム: 1700.1 μs]
範囲 (最小 … 最大): 134639.9 μs … 137621.4 μs 10 実行
fn mandelbrot_kernel_SIMD [
simd_width : Int
]( c : ComplexSIMD[float_type, simd_width]) -> SIMD [float_type, simd_width]:
""" A vectorized implementation of the inner mandelbrot computation. """
let cx = c.re
let cy = c.im
var x = SIMD [float_type, simd_width]( 0 )
var y = SIMD [float_type, simd_width]( 0 )
var y2 = SIMD [float_type, simd_width]( 0 )
var iters = SIMD [float_type, simd_width]( 0 )
var t : SIMD [DType.bool, simd_width] = True
for i in range ( MAX_ITERS ):
if not t.reduce_or():
break
y2 = y * y
y = x.fma(y + y, cy)
t = x.fma(x, y2) <= 4
x = x.fma(x, cx - y2)
iters = t.select(iters + 1 , iters)
return iters
fn compute_multibrot_parallelized () -> Tensor[float_type]:
let t = Tensor[float_type](height, width)
@parameter
fn worker ( row : Int):
let scale_x = (max_x - min_x) / width
let scale_y = (max_y - min_y) / height
@parameter
fn compute_vector [ simd_width : Int]( col : Int):
""" Each time we operate on a `simd_width` vector of pixels. """
let cx = min_x + (col + iota[float_type, simd_width]()) * scale_x
let cy = min_y + row * scale_y
let c = ComplexSIMD[float_type, simd_width](cx, cy)
t.data().simd_store[simd_width](
row * width + col, mandelbrot_kernel_SIMD[simd_width](c)
)
# Vectorize the call to compute_vector where call gets a chunk of pixels.
vectorize[simd_width, compute_vector](width)
# Parallelized
parallelize[worker](height, height)
return t
def main ():
_ = compute_multibrot_parallelized()mojo build benchmarks/multibrot_set/multibrot_mojo_parallelize.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_mojo_parallelize.exe.json ' ./benchmarks/multibrot_set/multibrot_mojo_parallelize '結果:
ベンチマーク 1: ./benchmarks/multibrot_set/multibrot_mojo_Parallelize
時間 (平均 ± σ): 7139.4 μs ± 596.4 μs [ユーザー: 36535.2 μs、システム: 6670.1 μs]
範囲 (最小 … 最大): 6222.6 μs … 8269.7 μs 10 実行
def mandelbrot_kernel(c):
z = c
for i in range(MAX_ITERS):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.real * z.real + z.imag * z.imag > 4:
return i
return MAX_ITERS
def compute_mandelbrot():
t = [[0 for _ in range(WIDTH)] for _ in range(HEIGHT)] # Pixel matrix
dx = (MAX_X - MIN_X) / WIDTH
dy = (MAX_Y - MIN_Y) / HEIGHT
@par(collapse=2)
for row in range(HEIGHT):
for col in range(WIDTH):
t[row][col] = mandelbrot_kernel(complex(MIN_X + col * dx, MIN_Y + row * dy))
return t
compute_mandelbrot()
テスト実行またはプロットの場合 (ファイル内のコードのコメントを解除します)
CODON_PYTHON=/opt/homebrew/opt/[email protected]/Frameworks/Python.framework/Versions/3.11/lib/libpython3.11.dylib codon run --release benchmarks/multibrot_set/multibrot.codon構築して実行する
codon build --release -exe benchmarks/multibrot_set/multibrot.codon -o benchmarks/multibrot_set/multibrot_codon
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon.json ' ./benchmarks/multibrot_set/multibrot_codon '結果:
ベンチマーク 1: ./benchmarks/multibrot_set/multibrot_codon
時間 (平均 ± σ): 44184.7 μs ± 1142.0 μs [ユーザー: 248773.9 μs、システム: 72935.3 μs]
範囲 (最小 … 最大): 42963.8 μs … 46456.2 μs 10 実行
codon build --release -exe benchmarks/multibrot_set/multibrot_codon_par.codon -o benchmarks/multibrot_set/multibrot_codon_par
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon_par.json ' ./benchmarks/multibrot_set/multibrot_codon_par ' # Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/multibrot_set/ benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/multibrot_set/benchmarks.json > benchmarks/multibrot_set/benchmarks.json.md
silicon benchmarks/multibrot_set/benchmarks.json.md -l python -o benchmarks/multibrot_set/benchmarks.json.md.png高度な統計
みんなで一緒に
ズームした
ひとつひとつ詳しく
場所
リンク:
マンデルブロ = power = 2マルチブロット
z = z ** power + c # You can change this for different set枕内蔵ImagingEffectマンデルブロ
マンデルブロのエクサループ コドン バージョン
マンデルブロのモジュラー Mojo バージョン
Mojo Complex squared_norm
Matplotlib マンデルブロ
コンピューター サイエンスでは、半区間検索、対数検索、またはバイナリ チョップとも呼ばれる二分探索アルゴリズムは、ソートされた配列内でターゲット値の位置を見つける検索アルゴリズムです。
Python、Mojo、Swift、V、Julia、Nim、Zig を使ってコードを実行してみましょう。
注: PythonとMojo のバージョンについては、測定と比較のために一部の最適化を残し、コードを同様に作成します。
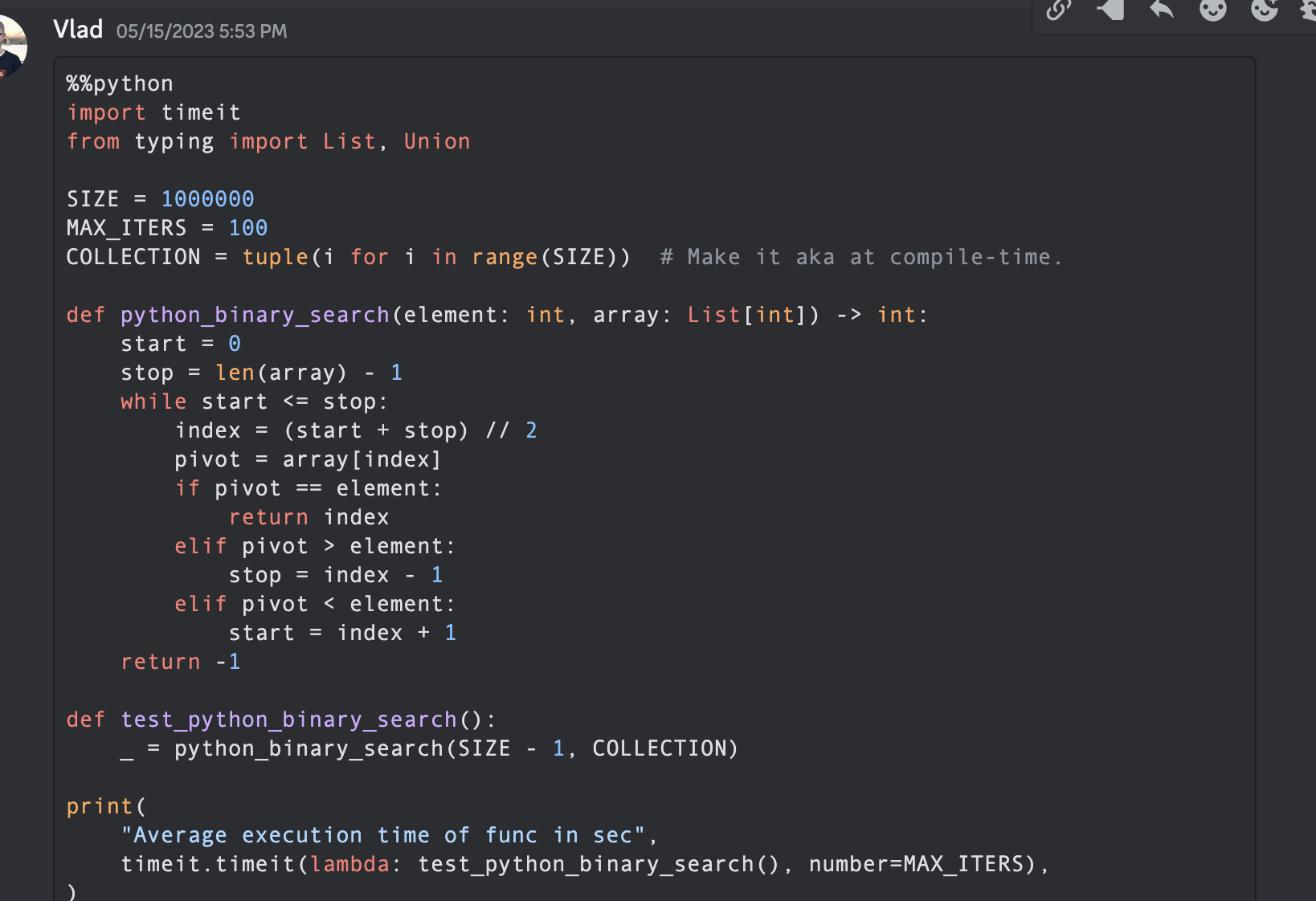
from typing import List
import timeit
SIZE = 1000000
MAX_ITERS = 100
COLLECTION = tuple ( i for i in range ( SIZE )) # Make it aka at compile-time.
def python_binary_search ( element : int , array : List [ int ]) -> int :
start = 0
stop = len ( array ) - 1
while start <= stop :
index = ( start + stop ) // 2
pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
def test_python_binary_search ():
_ = python_binary_search ( SIZE - 1 , COLLECTION )
print (
"Average execution time of func in sec" ,
timeit . timeit ( lambda : test_python_binary_search (), number = MAX_ITERS ),
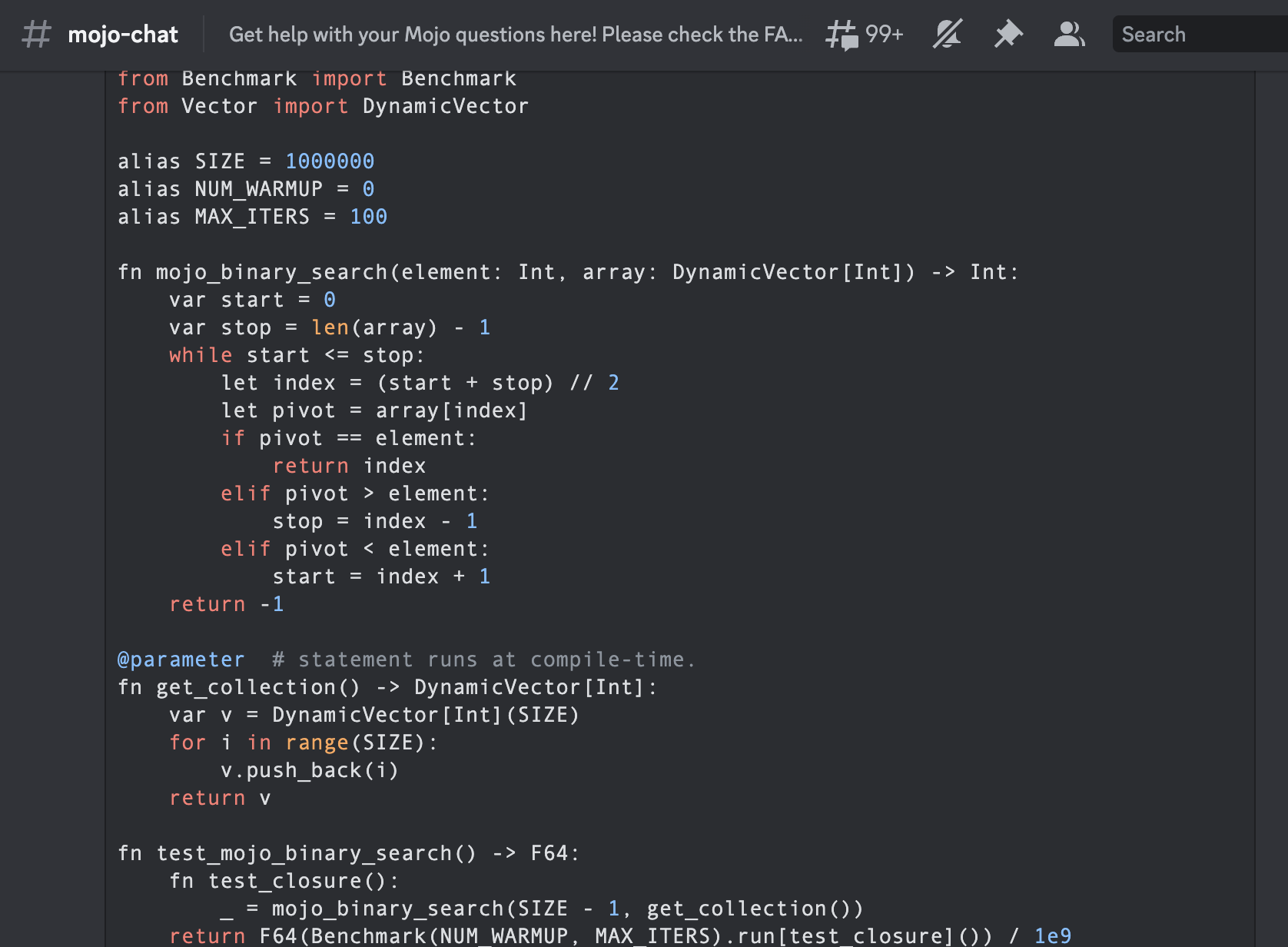
) """Implements basic binary search."""
from Benchmark import Benchmark
from Vector import DynamicVector
alias SIZE = 1000000
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn mojo_binary_search ( element : Int , array : DynamicVector [ Int ]) - > Int :
var start = 0
var stop = len ( array ) - 1
while start <= stop :
let index = ( start + stop ) // 2
let pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
@ parameter # statement runs at compile-time.
fn get_collection () - > DynamicVector [ Int ]:
var v = DynamicVector [ Int ]( SIZE )
for i in range ( SIZE ):
v . push_back ( i )
return v
fn test_mojo_binary_search () - > F64 :
fn test_closure ():
_ = mojo_binary_search ( SIZE - 1 , get_collection ())
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ test_closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
test_mojo_binary_search (),
)これは、Mojoby コミュニティ (@ego) で作成され、mojo-chat に投稿された最初のバイナリ検索です。
func binarySearch ( items : [ Int ] , elem : Int ) -> Int {
var low = 0
var high = items . count - 1
var mid = 0
while low <= high {
mid = Int ( ( high + low ) / 2 )
if items [ mid ] < elem {
low = mid + 1
} else if items [ mid ] > elem {
high = mid - 1
} else {
return mid
}
}
return - 1
}
let items = [ 1 , 2 , 3 , 4 , 0 ] . sorted ( )
let res = binarySearch ( items : items , elem : 4 )
print ( res ) function binarysearch (lst :: Vector{T} , val :: T ) where T
low = 1
high = length (lst)
while low ≤ high
mid = (low + high) ÷ 2
if lst[mid] > val
high = mid - 1
elseif lst[mid] < val
low = mid + 1
else
return mid
end
end
return 0
end proc binarySearch [T](a: openArray [T], key: T): int =
var b = len (a)
while result < b:
var mid = ( result + b) div 2
if a[mid] < key: result = mid + 1
else : b = mid
if result >= len (a) or a[ result ] != key: result = - 1
let res = @ [ 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 12 , 14 , 16 , 18 , 20 , 22 , 25 , 27 , 30 ]
echo binarySearch (res, 10 ) const std = @import ( "std" );
fn binarySearch ( comptime T : type , arr : [] const T , target : T ) ? usize {
var lo : usize = 0 ;
var hi : usize = arr . len - 1 ;
while ( lo <= hi ) {
var mid : usize = ( lo + hi ) / 2 ;
if ( arr [ mid ] == target ) {
return mid ;
} else if ( arr [ mid ] < target ) {
lo = mid + 1 ;
} else {
hi = mid - 1 ;
}
}
return null ;
} fn binary_search (a [] int , value int ) int {
mut low := 0
mut high := a.len - 1
for low < = high {
mid := (low + high) / 2
if a[mid] > value {
high = mid - 1
} else if a[mid] < value {
low = mid + 1
} else {
return mid
}
}
return - 1
}
fn main () {
search_list := [ 1 , 2 , 3 , 5 , 6 , 7 , 8 , 9 , 10 ]
println ( binary_search (search_list, 9 ))
} fn breadth_first_search_path (graph map [ string ][] string , vertex string , target string ) [] string {
mut path := [] string {}
mut visited := [] string {init: vertex}
mut queue := [][][] string {}
queue << [[vertex], path]
for queue.len > 0 {
mut idx := queue.len - 1
node := queue[idx][ 0 ][ 0 ]
path = queue[idx][ 1 ]
queue. delete (idx)
if node == target {
path << node
return path
}
for child in graph[node] {
mut tmp := path. clone ()
if child ! in visited {
visited << child
tmp << node
queue << [[child], tmp]
}
}
}
return path
}
fn main () {
graph := map {
'A' : [ 'B' , 'C' ]
'B' : [ 'A' , 'D' , 'E' ]
'C' : [ 'A' , 'F' ]
'D' : [ 'B' ]
'E' : [ 'B' , 'F' ]
'F' : [ 'C' , 'E' ]
}
println ( 'Graph: $graph ' )
path := breadth_first_search_path (graph, 'A' , 'F' )
println ( 'The shortest path from node A to node F is: $path ' )
assert path == [ 'A' , 'C' , 'F' ]
} import timeit
SIZE = 100
MAX_ITERS = 100
def _fizz_buzz (): # Make it aka at compile-time.
res = []
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
s = "FizzBuzz"
elif n % 3 == 0 :
s = "Fizz"
elif n % 5 == 0 :
s = "Buzz"
else :
s = str ( n )
res . append ( s )
return res
DATA = _fizz_buzz ()
def fizz_buzz ():
print ( " n " . join ( DATA ))
print (
"Average execution time of Python func in sec" ,
timeit . timeit ( lambda : fizz_buzz (), number = MAX_ITERS ),
)
# Average execution time of Python func in sec 0.005334990004485007 ( import '[java.io OutputStream])
( require '[clojure.java.io :as io])
( def devnull ( io/writer ( OutputStream/nullOutputStream )))
( defmacro timeit [n expr]
`(with-out-str ( time
( dotimes [_# ~( Math/pow 1 n)]
( binding [*out* devnull]
~expr)))))
( defmacro macro-fizz-buzz [n]
`( fn []
( print
~( apply str
( for [i ( range 1 ( inc n))]
( cond
( zero? ( mod i 15 )) " FizzBuzz n "
( zero? ( mod i 5 )) " Buzz n "
( zero? ( mod i 3 )) " Fizz n "
:else ( str i " n " )))))))
( print ( timeit 100 ( macro-fizz-buzz 100 )))
; ; "Elapsed time: 0.175486 msecs"
; ; Average execution time of Clojure func in sec 0.000175486 seconds from String import String
from Benchmark import Benchmark
alias SIZE = 100
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
@ parameter # statement runs at compile-time.
fn _fizz_buzz () - > String :
var res : String = ""
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
res += "FizzBuzz"
elif n % 3 == 0 :
res += "Fizz"
elif n % 5 == 0 :
res += "Buzz"
else :
res += String ( n )
res += " n "
return res
fn fizz_buzz ():
print ( _fizz_buzz ())
fn run_benchmark () - > F64 :
fn _closure ():
_ = fizz_buzz ()
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
run_benchmark (),
)
# Average execution time of func in sec 0.000104 これは、コミュニティ (@Ego) によって Mojo で書かれた最初の Fizz バズです。
アルゴリズムの有名な参考書『アルゴリズム入門 A3』のアルゴリズムを使用します。
その名声により、略語「 CLRS 」 (Cormen、Leiserson、Rivest、Stein)、または初版では「 CLR 」(Cormen、Leiserson、Rivest) が一般的に使用されるようになりました。
第 2 章「2.3.1 分割統治アプローチ」。
% % python
import timeit
MAX_ITERS = 100
def merge ( A , p , q , r ):
n1 = q - p + 1
n2 = r - q
L = [ None ] * n1
R = [ None ] * n2
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
i = 0
j = 0
k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
def merge_sort ( A , p , r ):
if p < r :
q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
def run_benchmark_merge_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
merge_sort ( A , 0 , len ( A ) - 1 )
print (
"Average execution time of Python `merge_sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_merge_sort (), number = MAX_ITERS ),
)
# Average execution time of Python `merge_sort` in sec 0.019136679999064654
def run_benchmark_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
A . sort ()
print (
"Average execution time of Python builtin `sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_sort (), number = MAX_ITERS ),
)
# Average execution time of Python builtin `sort` in sec 0.00019922800129279494 from Benchmark import Benchmark
from Vector import DynamicVector
from StaticTuple import StaticTuple
from Sort import sort
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn merge ( inout A : DynamicVector [ Int ], p : Int , q : Int , r : Int ):
let n1 = q - p + 1
let n2 = r - q
var L = DynamicVector [ Int ]( n1 )
var R = DynamicVector [ Int ]( n2 )
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
var i = 0
var j = 0
var k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
fn merge_sort ( inout A : DynamicVector [ Int ], p : Int , r : Int ):
if p < r :
let q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
@ parameter
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ MAX_ITERS , Int ]( 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
fn run_benchmark_merge_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo `merge_sort` in sec " ,
run_benchmark_merge_sort (),
)
# Average execution time of Mojo `merge_sort` in sec 1.1345999999999999e-05
fn run_benchmark_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
sort ( A )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo builtin `sort` in sec " ,
run_benchmark_sort (),
)
# Average execution time of Mojo builtin `sort` in sec 2.988e-06次のように使用できます。
# Usage: merge_sort
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
print ( len ( A ))
print ( A [ 0 ], A [ 99 ]) from Sort import sort組み込みは、実装よりも少し高速ですが、言語の深い部分で、いつものようにアルゴリズム =) とプログラミング パラダイムを使用して最適化できます。
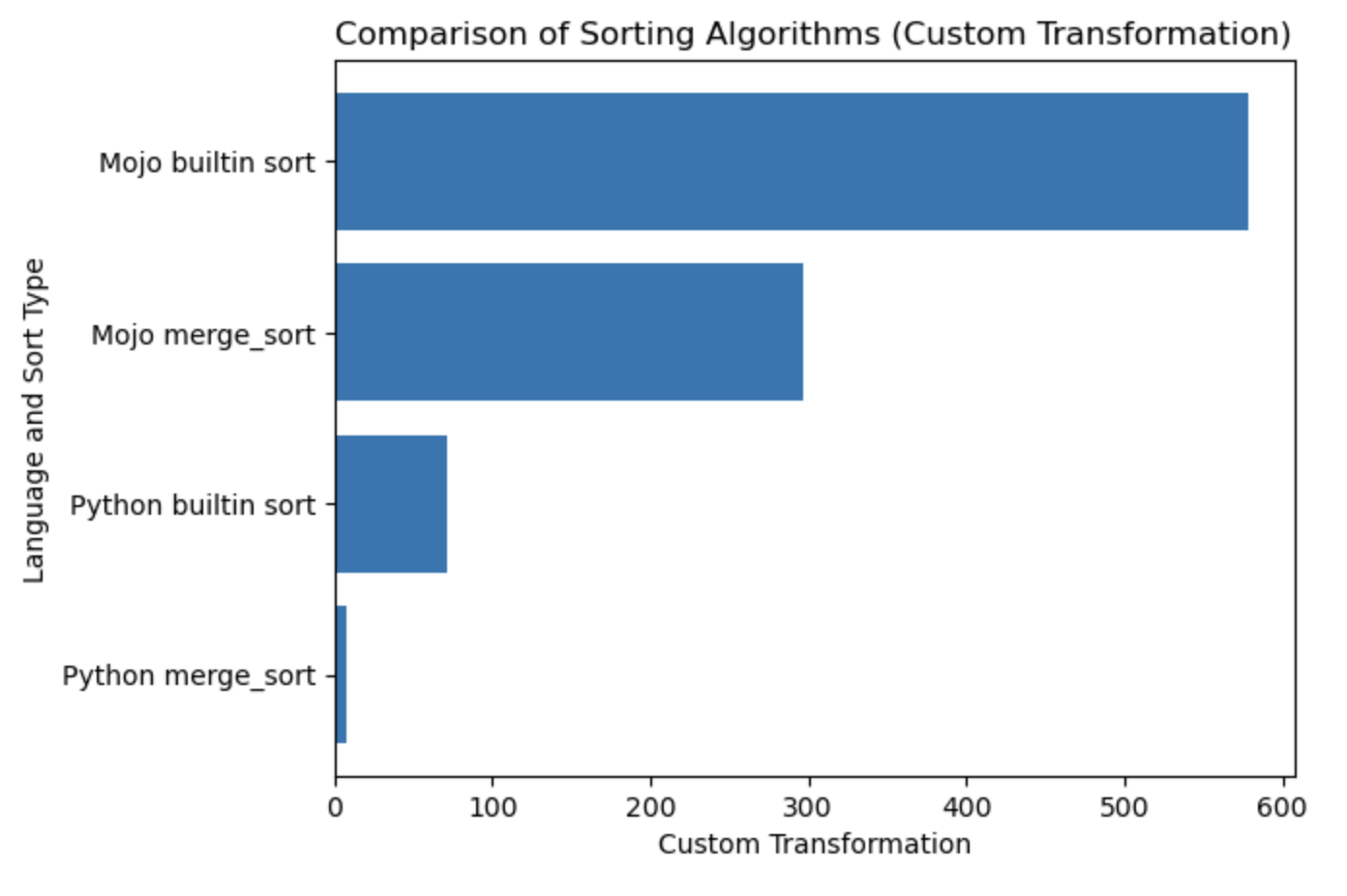
| ラング | 秒 |
|---|---|
| Python マージソート | 0.019136679 |
| Python 組み込みソート | 0.000199228 |
| Mojo マージソート | 0.000011346 |
| Mojo 組み込みソート | 0.000002988 |
このテーブルのプロットを作成しましょう。
#%%python
import matplotlib . pyplot as plt
import numpy as np
languages = [ 'Python merge_sort' , 'Python builtin sort' , 'Mojo merge_sort' , 'Mojo builtin sort' ]
seconds = [ 0.019136679 , 0.000199228 , 0.000011346 , 0.000002988 ]
# Apply a custom transformation to the values
transformed_seconds = [ np . sqrt ( 1 / x ) for x in seconds ]
plt . barh ( languages , transformed_seconds )
plt . xlabel ( 'Custom Transformation' )
plt . ylabel ( 'Language and Sort Type' )
plt . title ( 'Comparison of Sorting Algorithms (Custom Transformation)' )
plt . show ()プロットノートは、多ければ多いほど良く、速くなります。
ここから HelloMojo を開始して、 [パラメータ]と[パラメータ式]のパラメータ化を理解することを強くお勧めします。この例のように:
fn concat [ len1 : Int , len2 : Int ]( lhs : MySIMD [ len1 ], rhs : MySIMD [ len2 ]) - > MySIMD [ len1 + len2 ]:
let result = MySIMD [ len1 + len2 ]()
for i in range ( len1 ):
result [ i ] = lhs [ i ]
for j in range ( len2 ):
result [ len1 + j ] = rhs [ j ]
return result
let a = MySIMD [ 2 ]( 1 , 2 )
let x = concat [ 2 , 2 ]( a , a )
x . dump ()コンパイル時[パラメータ]: fn concat[len1: Int, len2: Int] 。
実行時(引数) : fn concat(lhs: MySIMD, rhs: MySIMD) 。
角括弧[]内のパラメータ PEP695 構文。
Python では次のようになります。
def func ( a : _T , b : _T ) -> _T :
...現在モジョでは:
def func [ T ]( a : T , b : T ) -> T :
... [パラメータ]には名前が付けられ、Mojo プログラムの通常の値と同様の型を持ちますが、 parameters[]はコンパイル時に評価されます。
パラメータはランタイム プログラムで必要になる前にコンパイル時に解決されるため、ランタイム プログラムは[parameters]の値を使用できますが、コンパイル時のパラメータ式ではランタイム値を使用できない場合があります。
PEP673からのSelfタイプ
fn __sub__ ( self , rhs : Self ) - > Self :
let result = MySIMD [ size ]()
for i in range ( size ):
result [ i ] = self [ i ] - rhs [ i ]
return resultドキュメントには、Python のクラス属性とも呼ばれるフィールドという単語があります。
したがって、それらをdotで呼び出します。
from DType import DType
let bool_type = DType . bool from DType import DType
DType . si8 from DType import DType
from SIMD import SIMD , SI8
alias MY_SIMD_DType_si8 = SIMD [ DType . si8 , 1 ]
alias MY_SI8 = SI8
print ( MY_SIMD_DType_si8 == MY_SI8 )
# true from DType import DType
from SIMD import SIMD , SI8
from Vector import DynamicVector
from String import String
alias a = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias b = DynamicVector [ SI8 ]
print ( a == b )
print ( a == String )
print ( b == String )
# all trueしたがって、 String DynamicVector[SIMD[DType.si8, 1]]のようなもののエイリアスにすぎません。
VariadicList from List import VariadicList
fn destructuring_arguments ( * args : Int ):
let my_var_list = VariadicList ( args )
for i in range ( len ( my_var_list )):
print ( "argument" , i , ":" , my_var_list [ i ])
destructuring_arguments ( 1 , 2 , 3 , 4 )これは、最初のコレクションを作成するのに非常に役立ちます。次のように書くことができます:
from Vector import DynamicVector
from StaticTuple import StaticTuple
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ 4 , Int ]( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])
# or
from List import VariadicList
fn create_vertor () - > DynamicVector [ Int ]:
let var_list = VariadicList ( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( len ( var_list ))
for i in range ( len ( var_list )):
v . push_back ( var_list [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])関数 def と fn について詳しく読む
from String import String
# String concatenation
print ( String ( "'" ) + String ( 1 ) + "' n " )
# Python's join
print ( String ( "|" ). join ( "a" , "b" , "c" ))
# String format
from IO import _printf as print
let x : Int = 1
print ( "'%i' n " , x . value )文字列の場合は、形式文字列スライス[開始:終了:ステップ]で組み込みスライスを使用できます。
from String import String
let hello_mojo = String ( "Hello Mojo!" )
print ( "Till the end:" , hello_mojo [ 0 ::])
print ( "Before last 2 chars:" , hello_mojo [ 0 : - 2 ])
print ( "From start to the end with step 2:" , hello_mojo [ 0 :: 2 ])
print ( "From start to the before last with step 3:" , hello_mojo [ 0 : - 1 : 3 ])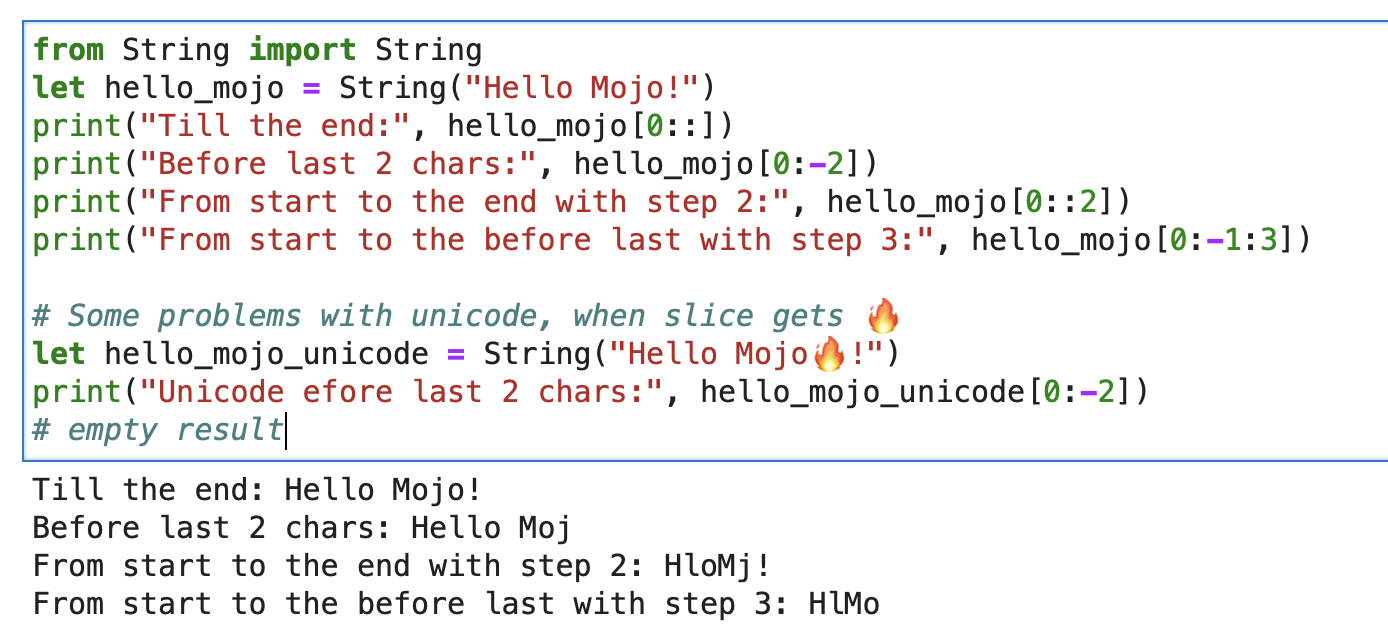
スライスするときに Unicode に問題があります。
let hello_mojo_unicode = String ( "Hello Mojo!" )
print ( "Unicode efore last 2 chars:" , hello_mojo_unicode [ 0 : - 2 ])
# no result, silentsここで説明といくつかの議論をします。
mbstowcs - マルチバイト文字列をワイド文字列に変換する
structデコレーター、別名 Python @dataclass 。メソッド__init__ 、 __copyinit__ 、 __moveinit__が自動的に生成されます。
@ value
struct dataclass :
var name : String
var age : Int @valueデコレータは、メンバーがcopyableおよび/またはmovable型に対してのみ機能することに注意してください。
些細なタイプ。このデコレータは、型がコピー可能__copyinit__および移動可能__moveinit__である必要があることを Mojo に指示します。また、Mojo に CPU レジスタで値を渡すことを優先するように指示します。 structs memoryを経由する代わりにregisterで渡されることをオプトインできるようにします。
@ register_passable ( "trivial" )
struct Int :
var value : __mlir_type . `!pop.scalar<index>`コンパイラの最適化を完全に制御するデコレータ。この関数が呼び出されたときに常にこの関数をインライン化するようにコンパイラーに指示します。
@ always_inline
fn foo ( x : Int , y : Int ) - > Int :
return x + y
fn bar ( z : Int ):
let r = foo ( z , z ) # This call will be inlinedランタイム値をキャプチャする入れ子関数に配置して、「パラメトリック」キャプチャ クロージャを作成できます。これにより、ランタイム値をキャプチャするクロージャがパラメータ値として渡されるようになります。
@ always_inline
@ parameter
fn test (): return 鋳造例
s : StringLiteral
let p = DTypePointer [ DType . si8 ]( s . data ()). bitcast [ DType . ui8 ]()
var result = 0
result += (( p . simd_load [ 64 ]( offset ) >> 6 ) != 0b10 ). cast [ DType . ui8 ](). reduce_add (). to_int ()
let rest_p : DTypePointer [ DType . ui8 ] = stack_allocation [ simd_width , UI8 , 1 ]()
from Bit import ctlz
s : String
i : Int
let code = s . buffer . data . load ( i )
let byte_length_code = ctlz ( ~ code ). to_int ()DTypePointer - 指定された DType でアドレスを保存し、SIMD 操作に簡単にアクセスしてデータの割り当て、ロード、変更を行うことができます。
from Pointer import DTypePointer
from DType import DType
from Random import rand
from Memory import memset_zero
# `heap`
var my_pointer_on_heap = DTypePointer [ DType . ui8 ]. alloc ( 8 )
memset_zero ( my_pointer_on_heap , 8 )
# `stack or register`
var data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
rand ( my_pointer_on_heap , 4 )
# `data` does not contain a reference to the `heap`, so load the data again
data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
# simd_load and simd_store
var half = my_pointer_on_heap . simd_load [ 4 ]( 0 )
half = half + 1
my_pointer_on_heap . simd_store [ 4 ]( 4 , half )
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Pointer move back
my_pointer_on_heap -= 1
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Mast free memory
my_pointer_on_heap . free ()構造体は、スクープを制限することで、ポインターの潜在的な危険性を最小限に抑えることができます。
DTypePointer に関する Mojo Dojo ブログの優れた記事はこちら
さらに彼のサンプル Matrix Struct と DTypePointer
ポインタは任意のregister_passable typeへのアドレスを格納し、 n個のそれらをheapに割り当てます。
from Pointer import Pointer
from Memory import memset_zero
from String import String
@ register_passable # for syntaxt like `let coord = p1[0]` and let it be passed through registers.
struct Coord : # memory-only type
var x : UI8
var y : UI8
var p1 = Pointer [ Coord ]. alloc ( 2 )
memset_zero ( p1 , 2 )
var coord = p1 [ 0 ] # is an identifier to memory on the stack or in a register
print ( coord . x )
# Store the value
coord . x = 5
coord . y = 5
print ( coord . x )
# We need to store the data.
p1 . store ( 0 , coord )
print ( p1 [ 0 ]. x )
# Mast free memory
p1 . free ()ポインターに関する記事全文
さらにポインターと構造体の例
モジュラー組み込み関数は、ある種の実行バックエンドです。
Mojo -> MLIR Dialects -> 最適化コードとアーキテクチャを備えた実行バックエンド。
MLIR は、さまざまなプログラミング言語およびアーキテクチャ向けのさまざまな変換および最適化パスを実装するコンパイラ インフラストラクチャです。
MLIR 自体は、オペレーティング システムの syscall と対話するための機能を直接提供しません。
オペレーティング システム サービスへの低レベル インターフェイスであり、通常はターゲット プログラミング言語またはオペレーティング システム自体のレベルで処理されます。 MLIR は言語やターゲットに依存しないように設計されており、最適化を実行するための中間表現を提供することに主な焦点を当てています。 MLIR でオペレーティング システムのシステムコールを実行するには、ターゲット固有のバックエンドを使用する必要があります。
ただし、これらのexecution backends使用すると、基本的に OS のシステムコールにアクセスできます。そして、C/LLVM/Python の世界全体が内部にあります。
実際に同じことを簡単に見てみましょう。
from OS import getenv
print ( getenv ( "PATH" ))
print ( getenv ( StringRef ( "PATH" )))
# or like this
from SIMD import SI8
from Intrinsics import external_call
var path1 = external_call [ "getenv" , StringRef ]( StringRef ( "PATH" ))
print ( path1 . data )
var path2 = external_call [ "getenv" , StringRef ]( "PATH" )
print ( path2 . data )
let abs_10 = external_call [ "abs" , SI8 , Int ]( - 10 )
print ( abs_10 )この簡単な例では、 external_call使用して、Mojo 関数と libc 関数の間のキャスト型で OS 環境変数を取得しました。かなりクールですね、はい!
このトピックからはたくさんのアイデアがあり、すぐに実行する機会を心待ちにしています。行動を起こすと素晴らしい結果が得られるかもしれません =)
何か面白いことをしてみましょう - libc function gethostname を呼び出します。
関数にはこのインターフェイスint gethostname (char *name, size_t size)があります。
そのために、 Intrinsicsモジュールのヘルパー関数 external_call を使用するか、独自の MLIR を作成できます。
コードを書いてみましょう:
from Intrinsics import external_call
from SIMD import SIMD , SI8
from DType import DType
from Vector import DynamicVector
from DType import DType
from Pointer import DTypePointer , Pointer
# We can use `from String import String` but for clarification we will use a full form.
# DynamicVector[SIMD[DType.si8, 1]] == DynamicVector[SI8] == String
# Compile time stuff.
alias cArrayOfStrings = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias capacity = 1024
var c_pointer_to_array_of_strings = DTypePointer [ DType . si8 ]( cArrayOfStrings ( capacity ). data )
var c_int_result = external_call [ "gethostname" , Int , DTypePointer [ DType . si8 ], Int ]( c_pointer_to_array_of_strings , capacity )
let mojo_string_result = String ( c_pointer_to_array_of_strings . address )
print ( "C function gethostname result code:" , c_int_result )
print ( "C function gethostname result value:" , star_hostname ( mojo_string_result ))
@ always_inline
fn star_hostname ( hostname : String ) - > String :
# [Builtin Slice](https://docs.modular.com/mojo/MojoBuiltin/BuiltinSlice.html)
# string slice[start:end:step]
return hostname [ 0 : - 1 : 2 ]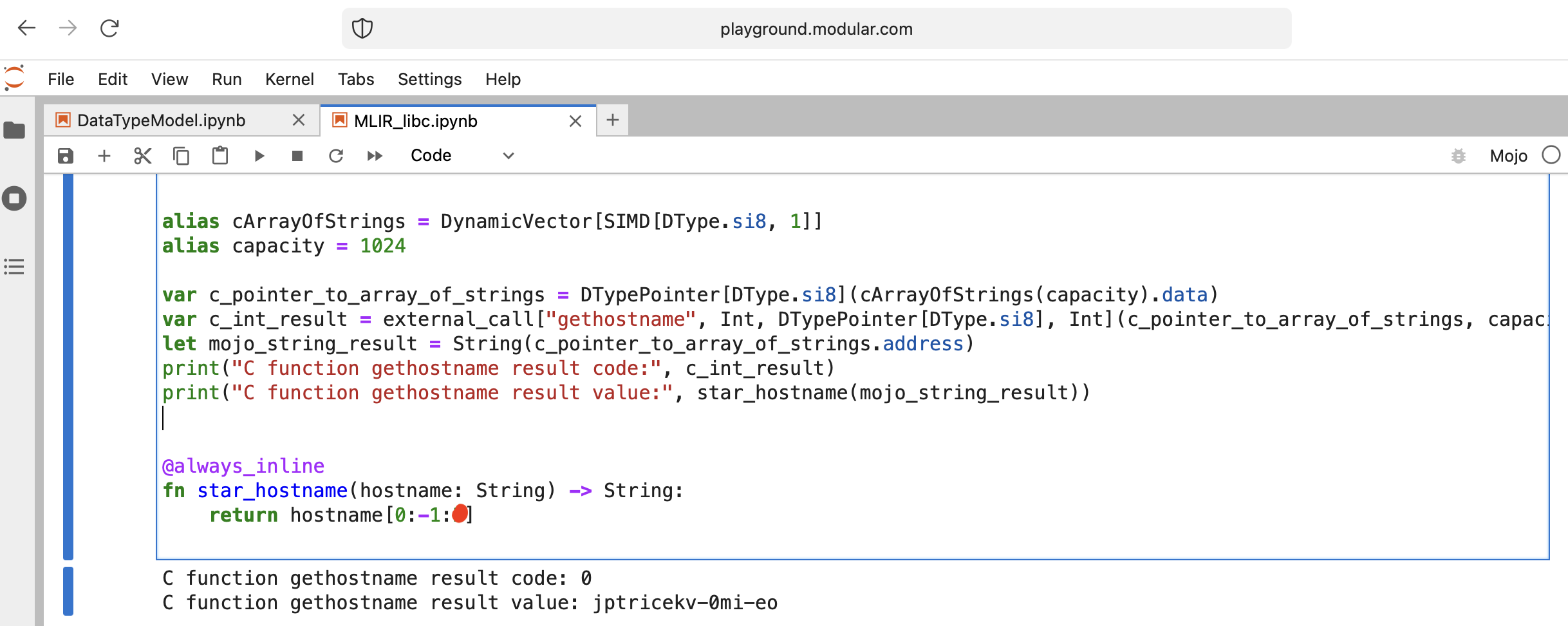
Mojo を使って WEB に関することをいくつかやってみましょう。 playground.modular.com にはインターネット アクセスがありませんが、1 台のマシン上で TCP などの興味深い機能を盗むことができます。
PythonInterface を使用して Mojo で最初の TCP クライアント/サーバー コードを書いてみましょう
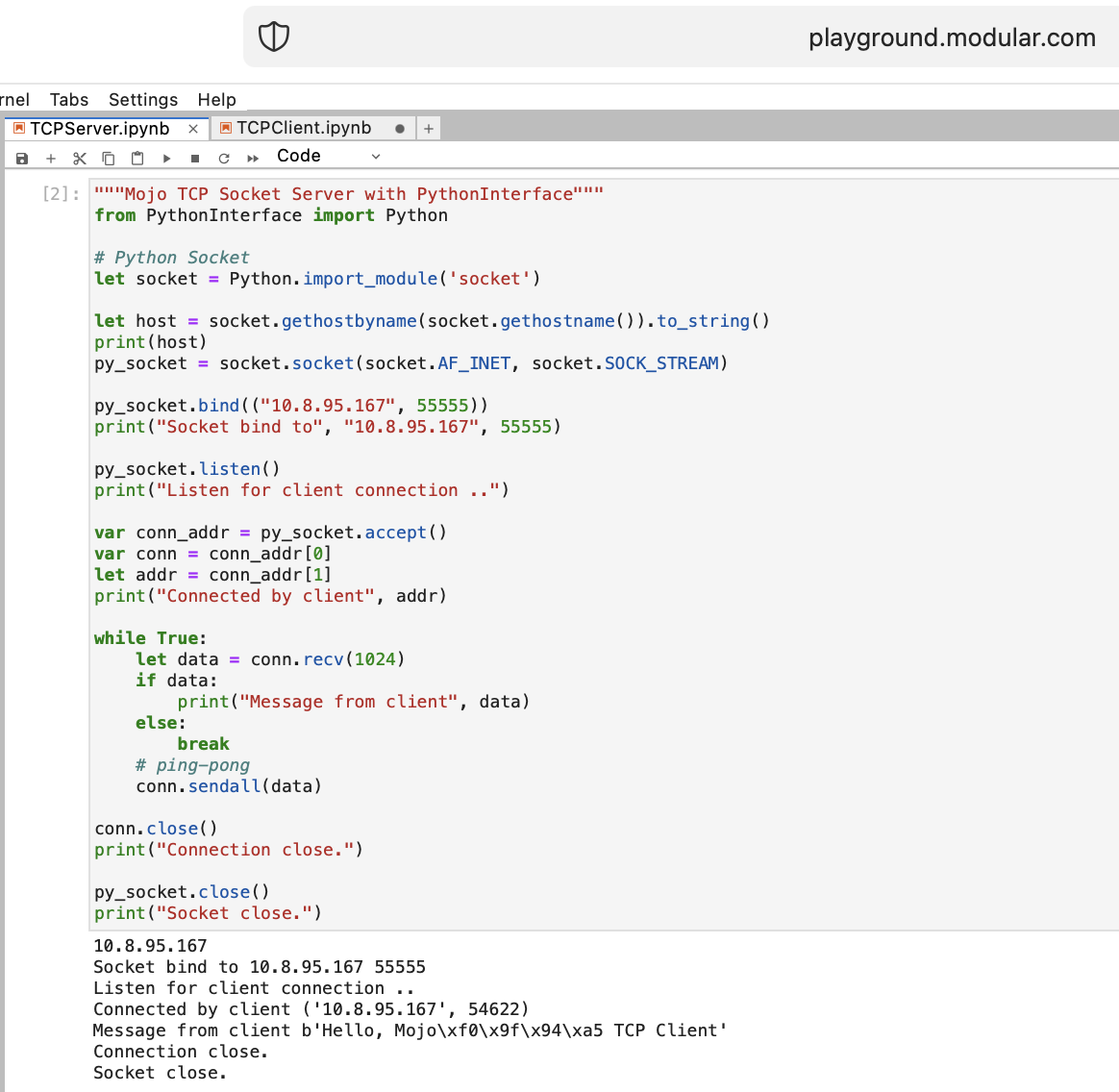
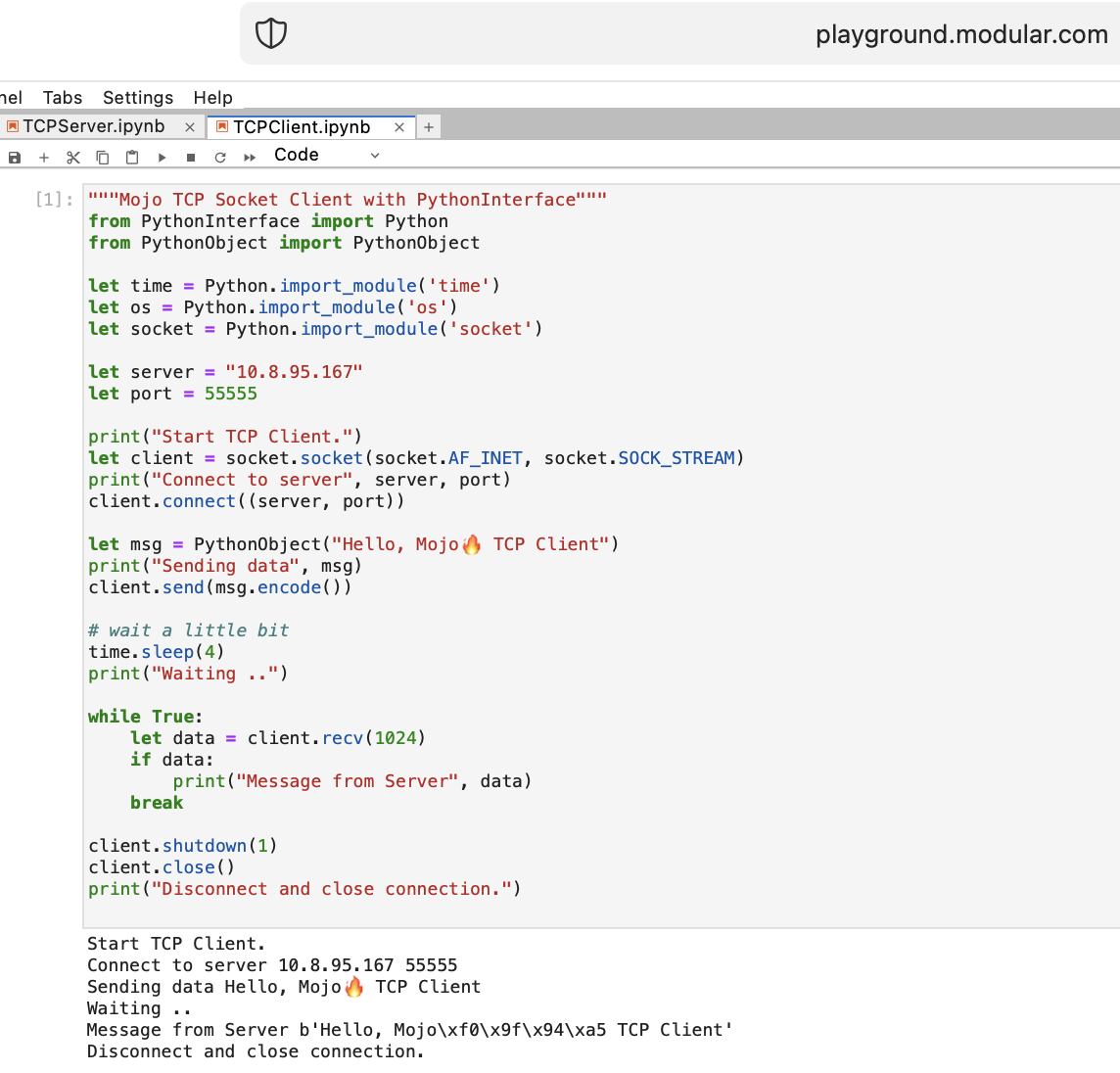
2 つの別々のノートブックを作成し、最初にTCPSocketServerを実行し、次にTCPSocketClient を実行する必要があります。
このコードのPython バージョンは、次の点を除いてほぼ同じです。
withleta, b = (1, 2)のように分割します。Mojo の TCP サーバーの後に進みます =)
クレイジーですが、最新の Python Web サーバー FastAPI を Mojo で実行してみましょう。
FastAPI コードをプレイグラウンドにアップロードする必要があります。したがって、ローカルマシンで次のようにします
pip install --target=web fastapi uvicorn
tar -czPf web.tar.gz webそして、Web インターフェイス経由でweb.tar.gzプレイグラウンドにアップロードします。
次に、それをinstall必要があります。適切なフォルダーに置くだけです。
% % python
import os
import site
site_packages_path = site . getsitepackages ()[ 0 ]
# install fastapi
os . system ( f"tar xzf web.tar.gz -C { site_packages_path } " )
os . system ( f"cp -r { site_packages_path } /web/* { site_packages_path } /" )
os . system ( f"ls { site_packages_path } | grep fastapi" )
# clean packages
os . system ( f"rm -rf { site_packages_path } /web" )
os . system ( f"rm web.tar.gz" ) from PythonInterface import Python
# Python fastapi
let fastapi = Python . import_module ( "fastapi" )
let uvicorn = Python . import_module ( "uvicorn" )
var app = fastapi . FastAPI ()
var router = fastapi . APIRouter ()
# tricky part
let py = Python ()
let py_code = """lambda: 'Hello Mojo!'"""
let py_obj = py . evaluate ( py_code )
print ( py_obj )
router . add_api_route ( "/mojo" , py_obj )
app . include_router ( router )
print ( "Start FastAPI WEB Server" )
uvicorn . run ( app )
print ( "Done" ) from PythonInterface import Python
let http_client = Python . import_module ( "http.client" )
let conn = http_client . HTTPConnection ( "localhost" , 8000 )
conn . request ( "GET" , "/mojo" )
let response = conn . getresponse ()
print ( response . status , response . reason , response . read ())いつものように、2 つの別々のノートブックを作成し、最初にFastAPI を実行し、次にFastAPIClient を実行する必要があります。
未解決の疑問はたくさんありますが、基本的には目標を達成しています。
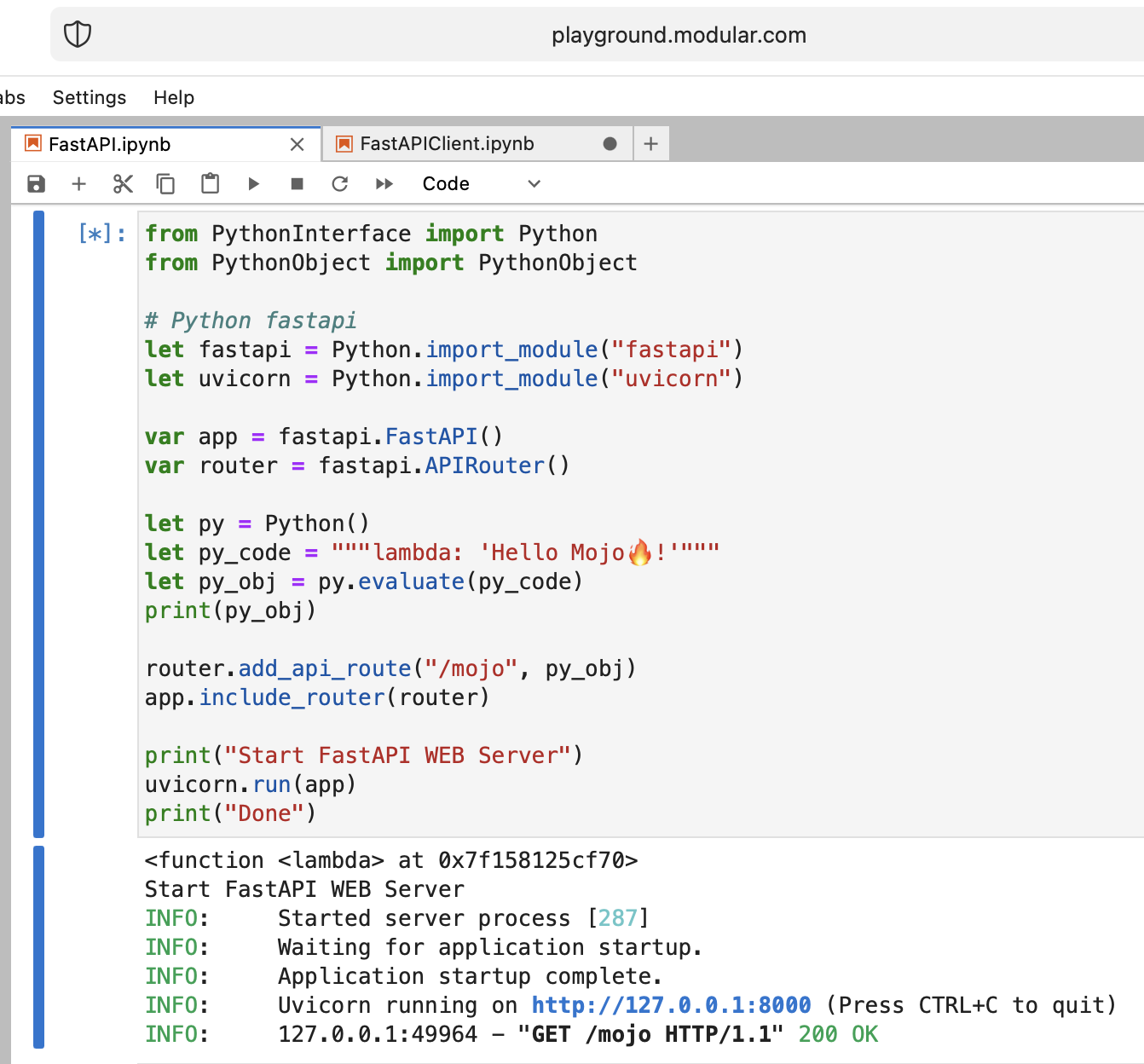
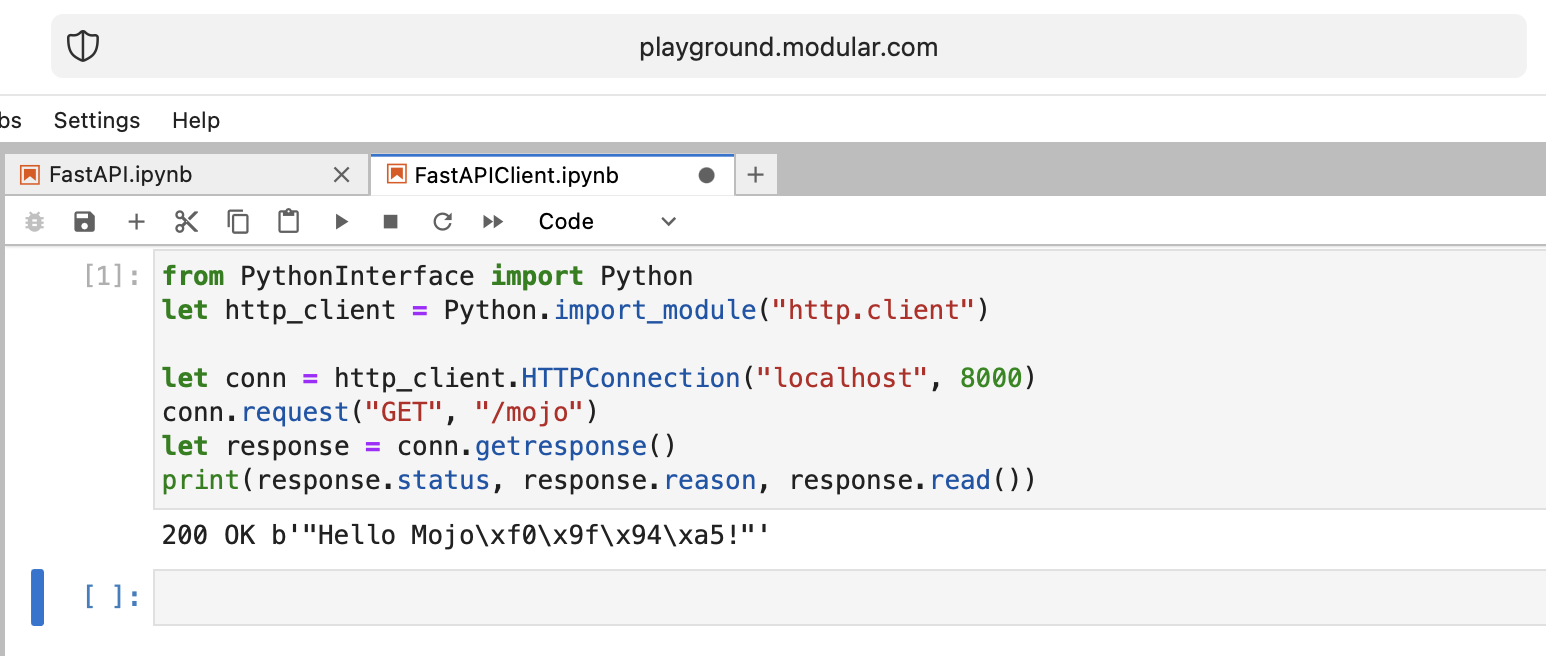
モジョ、よくやった!
いくつかの未解決の質問:
from PythonInterface import Python
let pyfn = Python . evaluate ( "lambda x, y: x+y" )
let functools = Python . import_module ( "functools" )
print ( functools . reduce ( pyfn , [ 1 , 2 , 3 , 4 ]))
# How to, without Mojo pyfn.so?
def pyfn ( x , y ):
retyrn x + y未来はとても楽観的です!
リンク:
ベンチマーク Mojo vs Numba by Nick Wogan
Samay Kapadia @Zalando による時間ユーティリティ
VSCode または DataSpell から Mojo プレイグラウンドに接続する
マキシム・ザックス著
from String import String
from PythonInterface import Python
let pathlib = Python . import_module ( 'pathlib' )
let txt = pathlib . Path ( 'nfl.csv' ). read_text ()
let s : String = txt . to_string ()libcの実装
from DType import DType
from Buffer import Buffer
from Pointer import Pointer
from String import String , chr
let hello = "hello"
let pointer = Pointer ( hello . data ())
print ( "variant 1" )
var result = String ()
for i in range ( len ( hello )):
result += chr ( pointer . bitcast [ Int8 ](). offset ( i ). load (). to_int ())
print ( result )
print ( "variant 2" )
print ( StringRef ( hello . data ()))
print ( "variant 3" )
print ( StringRef ( pointer . address ))
print ( "variant 4" )
let pm : Pointer [ __mlir_type . `!pop.scalar<si8>` ] = Pointer ( hello . data ())
print ( StringRef ( pm . address ))
print ( "variant 5" )
print ( String ( pointer . address ))
print ( "variant 6" )
let x = Buffer [ 8 , DType . int8 ]( pointer )
let array = x . simd_load [ 10 ]( 0 )
var result = String ()
for i in range ( len ( array )):
result += chr ( array [ i ]. to_int ())
print ( result )right click 、[プログラムOpen With > Editor押します。select allてcopy.ipynbのような Jupyter 拡張子を付けた名前を付けます。Github はそれを適切にレンダリングするので、プレイグラウンドでコードを試したい場合は、生のコードをコピーして貼り付けることができます。
私の個人的な見解ですので、あまり厳しい評価はしないでください。
Mojo は、例としての Python のように、学習しやすいプログラミング言語であるとは言えません。
他のプログラミング言語では多くの理解、忍耐、経験が必要です。
つまらないものではないものを作りたいなら、それは難しいけど面白いものになるでしょう!
この旅を始めてから2 週間が経ちましたが、今では Mojo についてよく知ることができたことを共有できることに興奮しています。
その構造と構文の複雑さが目の前で解き明かされ始め、新たな理解で満たされました。
私は今、この言語で自信を持ってコードを作成できるようになり、さまざまなアイデアを実現できるようになったということを誇りに思います。
Mojo は Modular Inc のプログラミング言語です。 Mojoについてここで説明した理由。会社についてはあまり知られていませんが、 Modular非常にクールな名前が付いています。以下で参照できます。
「言い換えれば、Mojo は魔法ではなく、モジュール式です。」
コンピューティング、プログラミング、AI/ML に関するすべて。会社の意味を正確に表す非常に優れたドメイン名です。
Modular のブランド ストーリーと、ブランドを通じて Modular が AI を人間化できるよう支援することに関する追加資料がいくつかあります。
今日は Python Enum の問題についてお話したいと思います。ソフトウェアエンジニアである私たちはWEB上でよく遭遇します。このデータベース スキーマ (PostgreSQL) のステータスがenumであると仮定します。
CREATE TYPE public .status_type AS ENUM (
' FIRST ' ,
' SECOND '
);Python コードでは、文字列として名前と値が必要です (フロントエンド側で ENUM 型を持つ GraphQL を使用すると仮定します)。また、それらの順序を維持し、これらの列挙型を比較する機能が必要です。
order2.status > order1.status > 'FIRST'
したがって、これはほとんどの一般的な言語にとって問題です =) しかし、 little-known Python 機能を使用して enum クラス メソッドをオーバーライドすることができます: __new__ 。
MALE -> 1 、 FEMALE -> 2 、PostgreSQL と同様です。len関数を使用してメンバーを COUNT するだけです。 import enum
from functools import total_ordering
@ total_ordering
@ enum . unique
class BaseUniqueSortedEnum ( enum . Enum ):
"""Base unique enum class with ordering."""
def __new__ ( cls , * args , ** kwargs ):
obj = object . __new__ ( cls )
obj . index = len ( cls . __members__ ) + 1 # This code line is a piece of advice, an insight and a tip!
return obj
# and then boring Python's magic methods as usual...
def __hash__ ( self ) -> int :
return hash (
f" { self . __module__ } _ { self . __class__ . __name__ } _ { self . name } _ { self . value } "
)
def __eq__ ( self , other ) -> bool :
self . _check_type ( other )
return super (). __eq__ ( other )
def __lt__ ( self , other ) -> bool :
self . _check_type ( other )
return self . index < other . index
def _check_type ( self , other ) -> None :
if type ( self ) != type ( other ):
raise TypeError ( f"Different types of Enum: { self } != { other } " )
class Dog ( BaseUniqueSortedEnum ):
# THIS ORDER MATTERS!
BLOODHOUND = "BLOODHOUND"
WEIMARANER = "WEIMARANER"
SAME = "SAME"
class Cat ( BaseUniqueSortedEnum )
# THIS ORDER MATTERS!
BRITISH = "BRITISH"
SCOTTISH = "SCOTTISH"
SAME = "SAME"
# and some tests
assert Dog . BLOODHOUND < Dog . WEIMARANER
assert Dog . BLOODHOUND <= Dog . WEIMARANER
assert Dog . BLOODHOUND != Dog . WEIMARANER
assert Dog . BLOODHOUND == Dog . BLOODHOUND
assert Dog . WEIMARANER == Dog . WEIMARANER
assert Dog . WEIMARANER > Dog . BLOODHOUND
assert Dog . WEIMARANER >= Dog . BLOODHOUND
assert Cat . BRITISH < Cat . SCOTTISH
assert Cat . BRITISH <= Cat . SCOTTISH
assert Cat . BRITISH != Cat . SCOTTISH
assert Cat . BRITISH == Cat . BRITISH
assert Cat . SCOTTISH == Cat . SCOTTISH
assert Cat . SCOTTISH > Cat . BRITISH
assert Cat . SCOTTISH >= Cat . BRITISH
assert hash ( Dog . BLOODHOUND ) == hash ( Dog . BLOODHOUND )
assert hash ( Dog . WEIMARANER ) == hash ( Dog . WEIMARANER )
assert hash ( Dog . BLOODHOUND ) != hash ( Dog . WEIMARANER )
assert hash ( Dog . SAME ) != hash ( Cat . SAME )
# raise TypeError
Dog . SAME <= Cat . SAME
Dog . SAME < Cat . SAME
Dog . SAME > Cat . SAME
Dog . SAME >= Cat . SAME
Dog . SAME != Cat . SAME物語の終わり。このPython ENUM洞察を上手にコーディングするために使用してください。


