soundstorm pytorch
0.5.0
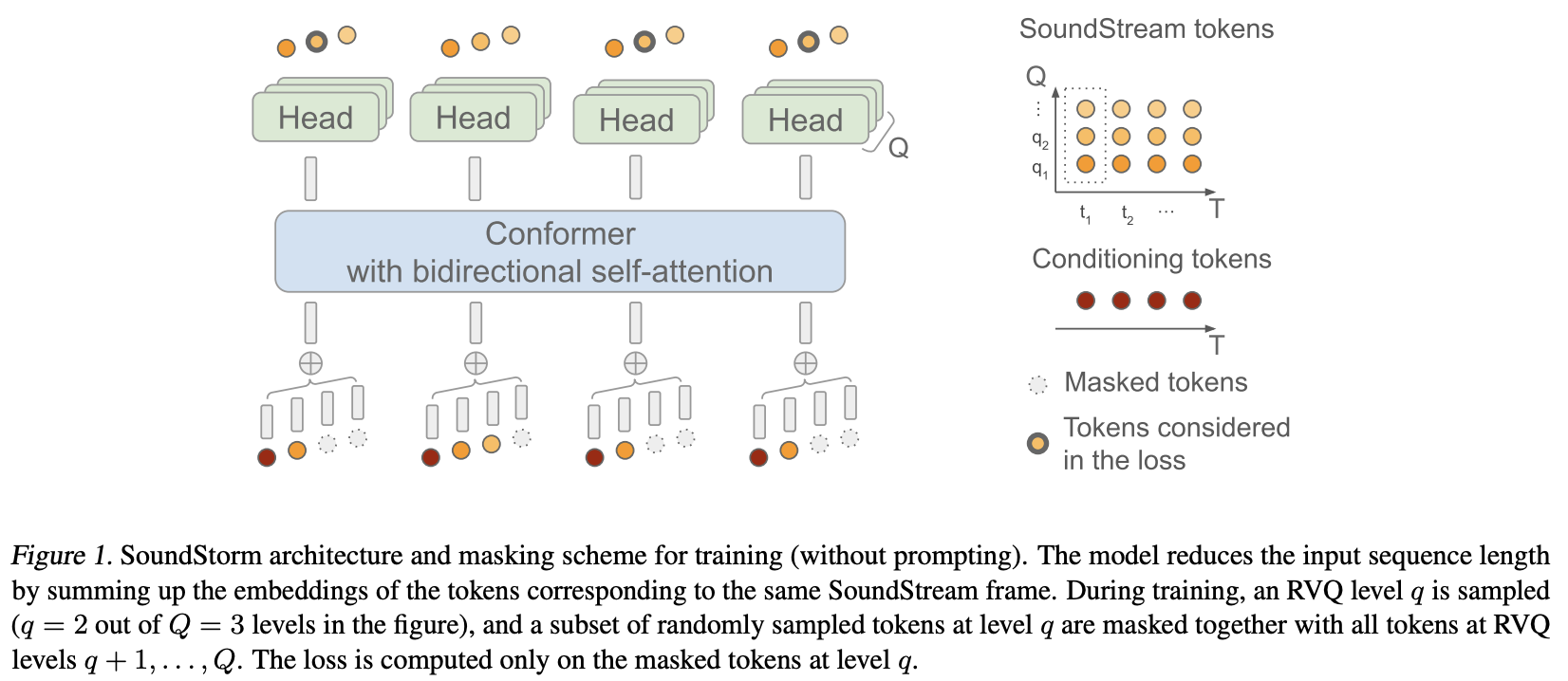
Google Deepmind からの効率的な並列オーディオ生成である SoundStorm を Pytorch で実装します。
彼らは基本的に、Soundstream からの残差ベクトル量子化コードに MaskGiT を適用しました。彼らが使用することを選択したトランス アーキテクチャは、Conformer と呼ばれる、オーディオ ドメインによく適合するものです。
プロジェクトページ
安定性と?最先端の人工知能研究に取り組み、オープンソース化するための寛大なスポンサーシップにハグフェイス
Lucas Newman には、初期トレーニング コード、音響プロンプト ロジック、レベルごとの量子化器のデコードなど、数多くの貢献をしていただきました。
?トレーニングのためのシンプルかつ強力なソリューションの提供を加速します
Einops : ニューラル ネットワークの構築を楽しく、簡単にし、気分を高揚させる不可欠な抽象化
Steven Hillis さん、正しいマスキング戦略を提出し、リポジトリが機能することを検証してくれました。
Lucas Newman は、複数のリポジトリにわたるモデルを使用して小規模な動作する Soundstorm を基本的にトレーニングし、すべてがエンドツーエンドで機能することを示しました。モデルには、SoundStream、Text-to-Semantic T5、そして最後に SoundStorm トランスフォーマーが含まれます。
@Jiang-Stan、反復マスク解除の重大なバグを特定してくれました。
$ pip install soundstorm-pytorch import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
model = SoundStorm (
conformer ,
steps = 18 , # 18 steps, as in original maskgit paper
schedule = 'cosine' # currently the best schedule is cosine
)
# get your pre-encoded codebook ids from the soundstream from a lot of raw audio
codes = torch . randint ( 0 , 1024 , ( 2 , 1024 , 12 )) # (batch, seq, num residual VQ)
# do the below in a loop for a ton of data
loss , _ = model ( codes )
loss . backward ()
# model can now generate in 18 steps. ~2 seconds sounds reasonable
generated = model . generate ( 1024 , batch_size = 2 ) # (2, 1024)生のオーディオで直接トレーニングするには、事前トレーニングされたSoundStream SoundStormに渡す必要があります。 audiolm-pytorch で独自のSoundStreamをトレーニングできます。
import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper , Conformer , SoundStream
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
soundstream = SoundStream (
codebook_size = 1024 ,
rq_num_quantizers = 12 ,
attn_window_size = 128 ,
attn_depth = 2
)
model = SoundStorm (
conformer ,
soundstream = soundstream # pass in the soundstream
)
# find as much audio you'd like the model to learn
audio = torch . randn ( 2 , 10080 )
# course it through the model and take a gazillion tiny steps
loss , _ = model ( audio )
loss . backward ()
# and now you can generate state-of-the-art speech
generated_audio = model . generate ( seconds = 30 , batch_size = 2 ) # generate 30 seconds of audio (it will calculate the length in seconds based off the sampling frequency and cumulative downsamples in the soundstream passed in above)完全なテキスト読み上げは、トレーニングされたTextToSemanticエンコーダー/デコーダー トランスフォーマーに依存します。次に、ウェイトをロードし、それをspear_tts_text_to_semanticとしてSoundStormに渡します。
spear-tts-pytorchはモデル アーキテクチャのみが完成しており、事前トレーニング + 疑似ラベル付け + 逆変換ロジックは完成していないため、これは進行中の作業です。
from spear_tts_pytorch import TextToSemantic
text_to_semantic = TextToSemantic (
dim = 512 ,
source_depth = 12 ,
target_depth = 12 ,
num_text_token_ids = 50000 ,
num_semantic_token_ids = 20000 ,
use_openai_tokenizer = True
)
# load the trained text-to-semantic transformer
text_to_semantic . load ( '/path/to/trained/model.pt' )
# pass it into the soundstorm
model = SoundStorm (
conformer ,
soundstream = soundstream ,
spear_tts_text_to_semantic = text_to_semantic
). cuda ()
# and now you can generate state-of-the-art speech
generated_speech = model . generate (
texts = [
'the rain in spain stays mainly in the plain' ,
'the quick brown fox jumps over the lazy dog'
]
) # (2, n) - raw waveform decoded from soundstream サウンドストリームを統合する
生成時に長さを秒単位で定義できます(サンプリング周波数などを考慮)
グループ化された RVQ がサポートされていることを確認してください。グループ次元全体の合計ではなく、埋め込みを連結します
配座異性体をコピーして、ロータリー埋め込みを使用して shaw の相対位置埋め込みをやり直すだけです。もう誰もショーを使いません。
デフォルトのフラッシュ アテンションは true
バッチノルムを削除し、レイヤーノルムだけを使用しますが、スウィッシュの後(ノームフォーマーの論文のように)
加速付きトレーナー - @lucasnewman に感謝
forwardにmaskを渡してgenerateことで、可変長シーケンスのトレーニングと生成を可能にします。
生成時にオーディオファイルのリストを返すオプション
コマンドラインツールに変える
クロスアテンションと適応レイヤーノルムコンディショニングを追加
@misc { borsos2023soundstorm ,
title = { SoundStorm: Efficient Parallel Audio Generation } ,
author = { Zalán Borsos and Matt Sharifi and Damien Vincent and Eugene Kharitonov and Neil Zeghidour and Marco Tagliasacchi } ,
year = { 2023 } ,
eprint = { 2305.09636 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @article { Chang2022MaskGITMG ,
title = { MaskGIT: Masked Generative Image Transformer } ,
author = { Huiwen Chang and Han Zhang and Lu Jiang and Ce Liu and William T. Freeman } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11305-11315 }
} @article { Lezama2022ImprovedMI ,
title = { Improved Masked Image Generation with Token-Critic } ,
author = { Jos{'e} Lezama and Huiwen Chang and Lu Jiang and Irfan Essa } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2209.04439 }
} @inproceedings { Nijkamp2021SCRIPTSP ,
title = { SCRIPT: Self-Critic PreTraining of Transformers } ,
author = { Erik Nijkamp and Bo Pang and Ying Nian Wu and Caiming Xiong } ,
booktitle = { North American Chapter of the Association for Computational Linguistics } ,
year = { 2021 }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

