rotary embedding torch
0.8.6
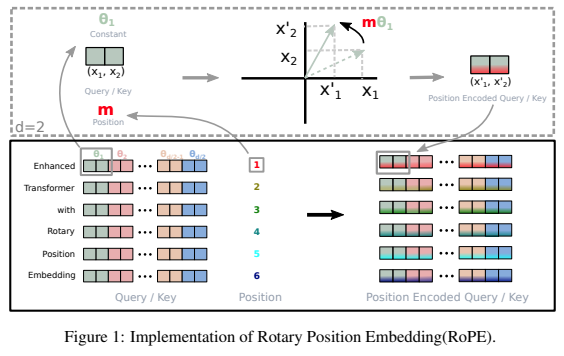
相対位置エンコーディングとしての成功に続き、Pytorch のトランスフォーマーに回転埋め込みを追加するためのスタンドアロン ライブラリ。具体的には、位置が固定されているか学習されたかに関係なく、情報をテンソルの任意の軸に回転させることが簡単かつ効率的になります。このライブラリは、わずかなコストで位置埋め込みの最先端の結果を提供します。
私の直感では、回転には人工ニューラル ネットワークで活用できる何かがあるとも思っています。
$ pip install rotary-embedding-torch import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding ( dim = 32 )
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
q = rotary_emb . rotate_queries_or_keys ( q )
k = rotary_emb . rotate_queries_or_keys ( k )
# then do your attention with your queries (q) and keys (k) as usual上記の手順をすべて正しく実行すると、トレーニング中に劇的な改善が見られるはずです。
推論時にキー/値キャッシュを扱う場合、クエリ位置はkey_value_seq_length - query_seq_lengthでオフセットされる必要があります。
これを簡単にするには、 rotate_queries_with_cached_keysメソッドを使用します。
q = torch . randn ( 1 , 8 , 1 , 64 ) # only one query at a time
k = torch . randn ( 1 , 8 , 1024 , 64 ) # key / values with cache concatted
q , k = rotary_emb . rotate_queries_with_cached_keys ( q , k )次のようにこれを手動で行うこともできます
q = rotary_emb . rotate_queries_or_keys ( q , offset = k . shape [ - 2 ] - q . shape [ - 2 ])n 次元の軸方向相対位置埋め込みを簡単に使用するため。ビデオトランスフォーマー
import torch
from rotary_embedding_torch import (
RotaryEmbedding ,
apply_rotary_emb
)
pos_emb = RotaryEmbedding (
dim = 16 ,
freqs_for = 'pixel' ,
max_freq = 256
)
# queries and keys for frequencies to be rotated into
# say for a video with 8 frames, and rectangular image (feature dimension comes last)
q = torch . randn ( 1 , 8 , 64 , 32 , 64 )
k = torch . randn ( 1 , 8 , 64 , 32 , 64 )
# get axial frequencies - (8, 64, 32, 16 * 3 = 48)
# will automatically do partial rotary
freqs = pos_emb . get_axial_freqs ( 8 , 64 , 32 )
# rotate in frequencies
q = apply_rotary_emb ( freqs , q )
k = apply_rotary_emb ( freqs , k )この論文では、回転埋め込みに ALiBi と同様の減衰を与えることで、長さの外挿の問題を修正することができました。この手法は XPos と名付けられており、初期化時にuse_xpos = Trueに設定することで使用できます。
これは自己回帰トランスフォーマーにのみ使用できます
import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding (
dim = 32 ,
use_xpos = True # set this to True to make rotary embeddings extrapolate better to sequence lengths greater than the one used at training time
)
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
# instead of using `rotate_queries_or_keys`, you will use `rotate_queries_and_keys`, the rest is taken care of
q , k = rotary_emb . rotate_queries_and_keys ( q , k )この MetaAI 論文では、事前トレーニング済みモデルのコンテキスト長をより長くするために、シーケンス位置の補間を簡単に微調整することを提案しています。彼らは、これが同じシーケンス位置をさらに拡張して単に微調整するよりもはるかに優れたパフォーマンスを示すことを示しています。
これを使用するには、初期化時にinterpolate_factor 1.より大きい値に設定します。(たとえば、事前トレーニングされたモデルが 2048 でトレーニングされた場合、 interpolate_factor = 2.に設定すると2048 x 2. = 4096まで微調整できます)。
更新: コミュニティ内の誰かが、うまく機能しないと報告しました。肯定的または否定的な結果が表示された場合は、メールでご連絡ください
import torch
from rotary_embedding_torch import RotaryEmbedding
rotary_emb = RotaryEmbedding (
dim = 32 ,
interpolate_factor = 2. # add this line of code to pretrained model and fine-tune for ~1000 steps, as shown in paper
) @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { Chen2023ExtendingCW ,
title = { Extending Context Window of Large Language Models via Positional Interpolation } ,
author = { Shouyuan Chen and Sherman Wong and Liangjian Chen and Yuandong Tian } ,
year = { 2023 }
} @misc { bloc97-2023
title = { NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. } ,
author = { /u/bloc97 } ,
url = { https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/ }
}

