q transformer
0.3.0
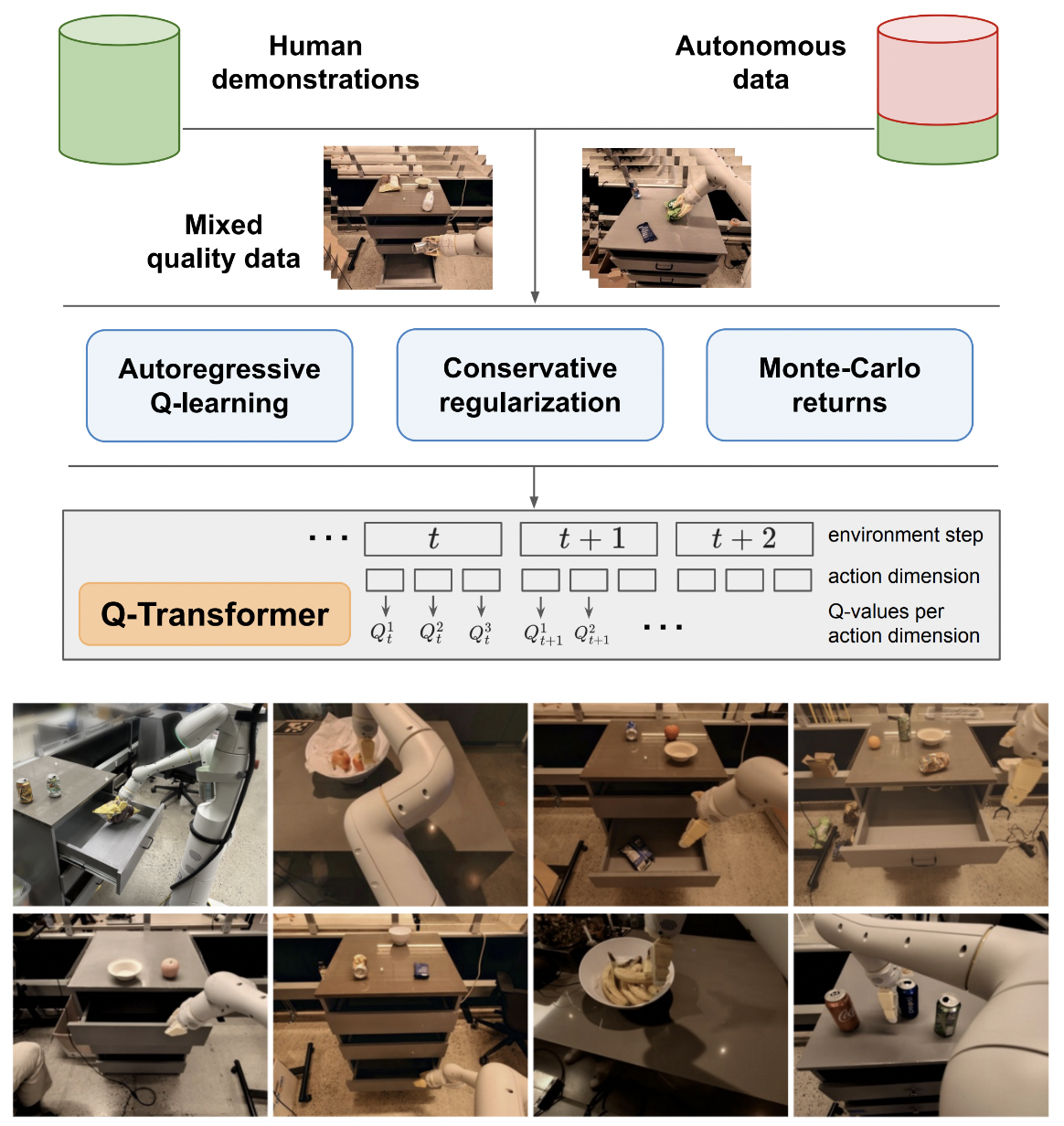
Google Deepmind からの Q-Transformer、自己回帰 Q 関数によるスケーラブルなオフライン強化学習の実装
複数のアクションで提案されている自己回帰 Q 学習との最終比較のためだけに、単一アクションでの Q 学習のロジックについては残しておきます。また、私自身と一般の人々への教育としても役立ちます。
自己回帰 Q 学習の定式化は Kotb らによって再現されました。
$ pip install q-transformer import torch
from q_transformer import (
QRoboticTransformer ,
QLearner ,
Agent ,
ReplayMemoryDataset
)
# the attention model
model = QRoboticTransformer (
vit = dict (
num_classes = 1000 ,
dim_conv_stem = 64 ,
dim = 64 ,
dim_head = 64 ,
depth = ( 2 , 2 , 5 , 2 ),
window_size = 7 ,
mbconv_expansion_rate = 4 ,
mbconv_shrinkage_rate = 0.25 ,
dropout = 0.1
),
num_actions = 8 ,
action_bins = 256 ,
depth = 1 ,
heads = 8 ,
dim_head = 64 ,
cond_drop_prob = 0.2 ,
dueling = True
)
# you need to supply your own environment, by overriding BaseEnvironment
from q_transformer . mocks import MockEnvironment
env = MockEnvironment (
state_shape = ( 3 , 6 , 224 , 224 ),
text_embed_shape = ( 768 ,)
)
# env.init() should return instructions and initial state: Tuple[str, Tensor[*state_shape]]
# env(actions) should return rewards, next state, and done flag: Tuple[Tensor[()], Tensor[*state_shape], Tensor[()]]
# agent is a class that allows the q-model to interact with the environment to generate a replay memory dataset for learning
agent = Agent (
model ,
environment = env ,
num_episodes = 1000 ,
max_num_steps_per_episode = 100 ,
)
agent ()
# Q learning on the replay memory dataset on the model
q_learner = QLearner (
model ,
dataset = ReplayMemoryDataset (),
num_train_steps = 10000 ,
learning_rate = 3e-4 ,
batch_size = 4 ,
grad_accum_every = 16 ,
)
q_learner ()
# after much learning
# your robot should be better at selecting optimal actions
video = torch . randn ( 2 , 3 , 6 , 224 , 224 )
instructions = [
'bring me that apple sitting on the table' ,
'please pass the butter'
]
actions = model . get_optimal_actions ( video , instructions )シングルアクションサポートに向けた最初の取り組み
SOTA気象モデルmetnet3で行われているように、maxvitのバッチノームレスバリアントを提供します
オプションのディープデュエルアーキテクチャを追加
nステップQ学習を追加
保守的な正則化を構築する
主な提案を紙で作成する(最後のアクションまでの自己回帰的離散アクション、最後にのみ報酬が与えられる)
フレーム + 学習トークンの段階で以前のアクションを連結するのではなく、即興デコーダー ヘッドのバリアントを作成します。言い換えれば、クラシックなエンコーダ - デコーダを使用します。
アキシャルロータリーエンベディング+シグモイドゲートを使用して何も気にしないようにmaxvitをやり直します。この変更により、maxvi のフラッシュ アテンションが有効になります
単純なデータセット作成クラスを構築し、環境とモデルを取得して、 ReplayDatasetが受け入れることができるフォルダーを返します。
ReplayDataset 複数の命令を正しく処理する
他のすべてのリポジトリと同じスタイルで、単純なエンドツーエンドの例を示します。
命令を処理せず、CFG ライブラリの null コンディショナーを利用する
アクションのデコード用に KV をキャッシュする
探索のために、一度にすべてのアクションを実行するのではなく、アクションのサブセットを細かくランダム化することができます。
RLの専門家に相談し、妄想バイアスの解決に向けた新たな前進があるかどうかを判断する
アクションのランダムな順序でトレーニングできるかどうかを確認します。順序は、注意層の前に連結または合計される条件付けとして送信される可能性があります。
最適な動作を実現する簡易ビームサーチ機能
過去のアクションとタイムステップの状態に対する即興のクロスアテンション、transformer-xl 方式 (構造化メモリ ドロップアウトあり)
この論文の主な考え方が言語モデルに適用できるかどうかをここで確認してください
@inproceedings { qtransformer ,
title = { Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions } ,
authors = { Yevgen Chebotar and Quan Vuong and Alex Irpan and Karol Hausman and Fei Xia and Yao Lu and Aviral Kumar and Tianhe Yu and Alexander Herzog and Karl Pertsch and Keerthana Gopalakrishnan and Julian Ibarz and Ofir Nachum and Sumedh Sontakke and Grecia Salazar and Huong T Tran and Jodilyn Peralta and Clayton Tan and Deeksha Manjunath and Jaspiar Singht and Brianna Zitkovich and Tomas Jackson and Kanishka Rao and Chelsea Finn and Sergey Levine } ,
booktitle = { 7th Annual Conference on Robot Learning } ,
year = { 2023 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Kumar2023MaintainingPI ,
title = { Maintaining Plasticity in Continual Learning via Regenerative Regularization } ,
author = { Saurabh Kumar and Henrik Marklund and Benjamin Van Roy } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:261076021 }
}

