point transformer pytorch
0.1.5
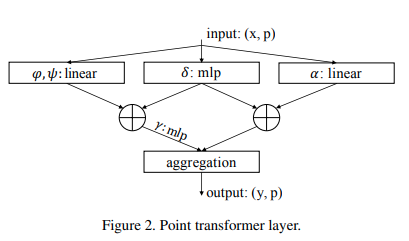
Pytorch での Point Transformer セルフアテンション レイヤーの実装。上記の単純な回路により、彼らのグループは点群の分類とセグメンテーションにおいてこれまでのすべての方法を上回るパフォーマンスを発揮できたようです。
$ pip install point-transformer-pytorch import torch
from point_transformer_pytorch import PointTransformerLayer
attn = PointTransformerLayer (
dim = 128 ,
pos_mlp_hidden_dim = 64 ,
attn_mlp_hidden_mult = 4
)
feats = torch . randn ( 1 , 16 , 128 )
pos = torch . randn ( 1 , 16 , 3 )
mask = torch . ones ( 1 , 16 ). bool ()
attn ( feats , pos , mask = mask ) # (1, 16, 128)このタイプのベクトル注意は、従来のものよりもはるかに高価です。この論文では、遠く離れた点への注意を排除するために、点に対して k 最近傍法を使用しました。 1 つの追加設定で同じことを行うことができます。
import torch
from point_transformer_pytorch import PointTransformerLayer
attn = PointTransformerLayer (
dim = 128 ,
pos_mlp_hidden_dim = 64 ,
attn_mlp_hidden_mult = 4 ,
num_neighbors = 16 # only the 16 nearest neighbors would be attended to for each point
)
feats = torch . randn ( 1 , 2048 , 128 )
pos = torch . randn ( 1 , 2048 , 3 )
mask = torch . ones ( 1 , 2048 ). bool ()
attn ( feats , pos , mask = mask ) # (1, 16, 128) @misc { zhao2020point ,
title = { Point Transformer } ,
author = { Hengshuang Zhao and Li Jiang and Jiaya Jia and Philip Torr and Vladlen Koltun } ,
year = { 2020 } ,
eprint = { 2012.09164 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

