RETRO pytorch
0.3.9
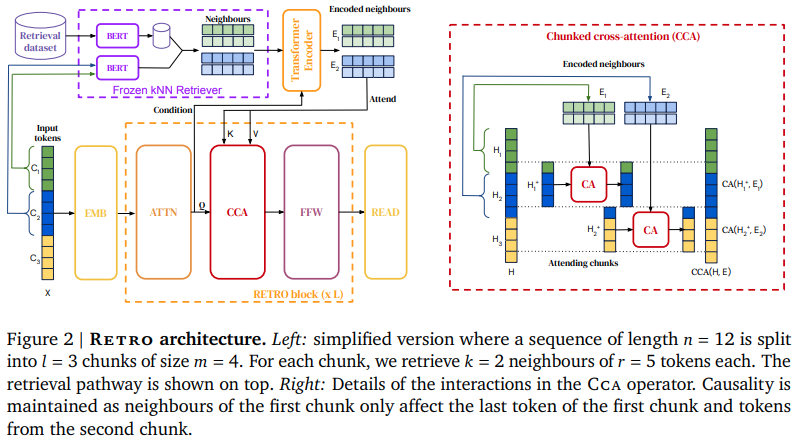
Deepmind の検索ベースのアテンション ネットである RETRO を Pytorch に実装します。これは論文からわずかに逸脱しますが、相対位置エンコーディングにロータリー埋め込みを使用し、Scann の代わりに Faiss ライブラリを使用します。
このライブラリは、インデックスを構築し、すべてのチャンクの k 最近傍を計算するために autofaiss を利用します。
ジェイ・アラマーの説明ブログ投稿
このレトリーバー アプローチのセールス ポイントは、10 分の 1 のパラメータで GPT-3 のパフォーマンスに達することです。この分野では間違いなくさらなる研究が必要です。
DeepNet 論文の主張を信じるのであれば、検索トランスフォーマーを 1000 レイヤーに拡張するために必要な機能も含めました。
最新情報: Reddit 上の誰かが私に金賞を贈ってくれました。何か分かりませんが、ありがとうございます!
最新情報: Deepnorm は清華社の 130B モデルで大規模に検証されました。 use_deepnet Trueに設定してトレーニングすることをお勧めします。
$ pip install retro-pytorch import torch
from retro_pytorch import RETRO
retro = RETRO (
chunk_size = 64 , # the chunk size that is indexed and retrieved (needed for proper relative positions as well as causal chunked cross attention)
max_seq_len = 2048 , # max sequence length
enc_dim = 896 , # encoder model dim
enc_depth = 2 , # encoder depth
dec_dim = 796 , # decoder model dim
dec_depth = 12 , # decoder depth
dec_cross_attn_layers = ( 3 , 6 , 9 , 12 ), # decoder cross attention layers (with causal chunk cross attention)
heads = 8 , # attention heads
dim_head = 64 , # dimension per head
dec_attn_dropout = 0.25 , # decoder attention dropout
dec_ff_dropout = 0.25 , # decoder feedforward dropout
use_deepnet = True # turn on post-normalization with DeepNet residual scaling and initialization, for scaling to 1000 layers
)
seq = torch . randint ( 0 , 20000 , ( 2 , 2048 + 1 )) # plus one since it is split into input and labels for training
retrieved = torch . randint ( 0 , 20000 , ( 2 , 32 , 2 , 128 )) # retrieved tokens - (batch, num chunks, num retrieved neighbors, retrieved chunk with continuation)
loss = retro ( seq , retrieved , return_loss = True )
loss . backward ()
# do above for many steps TrainingWrapperの目的は、 RETROトレーニングを開始するために、テキスト ドキュメントのフォルダーを必要な memmapped numpy 配列に処理することです。
import torch
from retro_pytorch import RETRO , TrainingWrapper
# instantiate RETRO, fit it into the TrainingWrapper with correct settings
retro = RETRO (
max_seq_len = 2048 , # max sequence length
enc_dim = 896 , # encoder model dimension
enc_depth = 3 , # encoder depth
dec_dim = 768 , # decoder model dimensions
dec_depth = 12 , # decoder depth
dec_cross_attn_layers = ( 1 , 3 , 6 , 9 ), # decoder cross attention layers (with causal chunk cross attention)
heads = 8 , # attention heads
dim_head = 64 , # dimension per head
dec_attn_dropout = 0.25 , # decoder attention dropout
dec_ff_dropout = 0.25 # decoder feedforward dropout
). cuda ()
wrapper = TrainingWrapper (
retro = retro , # path to retro instance
knn = 2 , # knn (2 in paper was sufficient)
chunk_size = 64 , # chunk size (64 in paper)
documents_path = './text_folder' , # path to folder of text
glob = '**/*.txt' , # text glob
chunks_memmap_path = './train.chunks.dat' , # path to chunks
seqs_memmap_path = './train.seq.dat' , # path to sequence data
doc_ids_memmap_path = './train.doc_ids.dat' , # path to document ids per chunk (used for filtering neighbors belonging to same document)
max_chunks = 1_000_000 , # maximum cap to chunks
max_seqs = 100_000 , # maximum seqs
knn_extra_neighbors = 100 , # num extra neighbors to fetch
max_index_memory_usage = '100m' ,
current_memory_available = '1G'
)
# get the dataloader and optimizer (AdamW with all the correct settings)
train_dl = iter ( wrapper . get_dataloader ( batch_size = 2 , shuffle = True ))
optim = wrapper . get_optimizer ( lr = 3e-4 , wd = 0.01 )
# now do your training
# ex. one gradient step
seq , retrieved = map ( lambda t : t . cuda (), next ( train_dl ))
# seq - (2, 2049) - 1 extra token since split by seq[:, :-1], seq[:, 1:]
# retrieved - (2, 32, 2, 128) - 128 since chunk + continuation, each 64 tokens
loss = retro (
seq ,
retrieved ,
return_loss = True
)
# one gradient step
loss . backward ()
optim . step ()
optim . zero_grad ()
# do above for many steps, then ...
# topk sampling with retrieval at chunk boundaries
sampled = wrapper . generate ( filter_thres = 0.9 , temperature = 1.0 ) # (1, <2049) terminates early if all <eos>
# or you can generate with a prompt, knn retrieval for initial chunks all taken care of
prompt = torch . randint ( 0 , 1000 , ( 1 , 128 )) # start with two chunks worth of sequence
sampled = wrapper . generate ( prompt , filter_thres = 0.9 , temperature = 1.0 ) # (1, <2049) terminates early if all <eos>トレーニング データの再処理を強制したい場合は、単にREPROCESS=1環境フラグを指定してスクリプトを実行します。
$ REPROCESS=1 python train.pyRETRODatasetクラスは、チャンク、(RETRO デコーダーで) トレーニングされるシーケンス内の最初のチャンクのインデックス、およびチャンクごとの k 最近傍の事前計算されたインデックスを含む、多数の memmapped numpy 配列へのパスを受け入れます。
上記のTrainingWrapper使用したくない場合は、これを使用してRETROトレーニング用のデータを簡単に組み立てることができます。
さらに、必要な memmapped データを作成するために必要な関数はすべて、以降のセクションにあります。
import torch
from torch . utils . data import DataLoader
from retro_pytorch import RETRO , RETRODataset
# mock data constants
import numpy as np
NUM_CHUNKS = 1000
CHUNK_SIZE = 64
NUM_SEQS = 100
NUM_NEIGHBORS = 2
def save_memmap ( path , tensor ):
f = np . memmap ( path , dtype = tensor . dtype , mode = 'w+' , shape = tensor . shape )
f [:] = tensor
del f
# generate mock chunk data
save_memmap (
'./train.chunks.dat' ,
np . int32 ( np . random . randint ( 0 , 8192 , size = ( NUM_CHUNKS , CHUNK_SIZE + 1 )))
)
# generate nearest neighbors for each chunk
save_memmap (
'./train.chunks.knn.dat' ,
np . int32 ( np . random . randint ( 0 , 1000 , size = ( NUM_CHUNKS , NUM_NEIGHBORS )))
)
# generate seq data
save_memmap (
'./train.seq.dat' ,
np . int32 ( np . random . randint ( 0 , 128 , size = ( NUM_SEQS ,)))
)
# instantiate dataset class
# which constructs the sequence and neighbors from memmapped chunk and neighbor information
train_ds = RETRODataset (
num_sequences = NUM_SEQS ,
num_chunks = NUM_CHUNKS ,
num_neighbors = NUM_NEIGHBORS ,
chunk_size = CHUNK_SIZE ,
seq_len = 2048 ,
chunk_memmap_path = './train.chunks.dat' ,
chunk_nn_memmap_path = './train.chunks.knn.dat' ,
seq_memmap_path = './train.seq.dat'
)
train_dl = iter ( DataLoader ( train_ds , batch_size = 2 ))
# one forwards and backwards
retro = RETRO (
max_seq_len = 2048 , # max sequence length
enc_dim = 896 , # encoder model dimension
enc_depth = 3 , # encoder depth
dec_dim = 768 , # decoder model dimensions
dec_depth = 12 , # decoder depth
dec_cross_attn_layers = ( 1 , 3 , 6 , 9 ), # decoder cross attention layers (with causal chunk cross attention)
heads = 8 , # attention heads
dim_head = 64 , # dimension per head
dec_attn_dropout = 0.25 , # decoder attention dropout
dec_ff_dropout = 0.25 # decoder feedforward dropout
). cuda ()
seq , retrieved = map ( lambda t : t . cuda (), next ( train_dl ))
# seq - (2, 2049) - 1 extra token since split by seq[:, :-1], seq[:, 1:]
# retrieved - (2, 32, 2, 128) - 128 since chunk + continuation, each 64 tokens
loss = retro (
seq ,
retrieved ,
return_loss = True
)
loss . backward ()このリポジトリは、BERT のケース化バージョンのデフォルトのトークナイザー (センテンスピース) を使用します。埋め込みはバニラ BERT からフェッチされ、マスクされた平均プール表現または CLS トークンのいずれかになります。
元。マスクされた平均プール表現
from retro_pytorch . retrieval import bert_embed , tokenize
ids = tokenize ([
'hello world' ,
'foo bar'
])
embeds = bert_embed ( ids ) # (2, 768) - 768 is hidden dimension of BERT元。 CLS トークンの表現
from retro_pytorch . retrieval import bert_embed , tokenize
ids = tokenize ([
'hello world' ,
'foo bar'
])
embeds = bert_embed ( ids , return_cls_repr = True ) # (2, 768) text_folder_to_chunks_を使用して、チャンクとチャンク開始インデックス (自己回帰トレーニングのシーケンス範囲を計算するため) を作成します。
from retro_pytorch . retrieval import text_folder_to_chunks_
stats = text_folder_to_chunks_ (
folder = './text_folder' ,
glob = '**/*.txt' ,
chunks_memmap_path = './train.chunks.dat' ,
seqs_memmap_path = './train.seq.dat' ,
doc_ids_memmap_path = './train.doc_ids.dat' , # document ids are needed for filtering out neighbors belonging to same document appropriately during computation of nearest neighbors
chunk_size = 64 ,
seq_len = 2048 ,
max_chunks = 1_000_000 ,
max_seqs = 100_000
)
# {'chunks': <number of chunks>, 'docs': <number of documents>, 'seqs': <number of sequences>} 1 つのコマンドで、memmapped チャンクの numpy 配列を埋め込みと faiss インデックスに変換できます
from retro_pytorch . retrieval import chunks_to_index_and_embed
index , embeddings = chunks_to_index_and_embed (
num_chunks = 1000 ,
chunk_size = 64 ,
chunk_memmap_path = './train.chunks.dat'
)
query_vector = embeddings [: 1 ] # use first embedding as query
_ , indices = index . search ( query_vector , k = 2 ) # fetch 2 neighbors, first indices should be self
neighbor_embeddings = embeddings [ indices ] # (1, 2, 768) chunks_to_precalculated_knn_コマンドを使用して、トレーニングに必要な最近傍ファイルを直接計算することもできます。
from retro_pytorch . retrieval import chunks_to_precalculated_knn_
chunks_to_precalculated_knn_ (
num_chunks = 1000 ,
chunk_size = 64 ,
chunk_memmap_path = './train.chunks.dat' , # path to main chunks dataset
doc_ids_memmap_path = './train.doc_ids.dat' , # path to document ids created by text_folder_to_chunks_, used for filtering out neighbors that belong to the same document
num_nearest_neighbors = 2 , # number of nearest neighbors you'd like to use
num_extra_neighbors = 10 # fetch 10 extra neighbors, in the case that fetched neighbors are frequently from same document (filtered out)
)
# nearest neighbor info saved to ./train.chunks.knn.dat @misc { borgeaud2022improving ,
title = { Improving language models by retrieving from trillions of tokens } ,
author = { Sebastian Borgeaud and Arthur Mensch and Jordan Hoffmann and Trevor Cai and Eliza Rutherford and Katie Millican and George van den Driessche and Jean-Baptiste Lespiau and Bogdan Damoc and Aidan Clark and Diego de Las Casas and Aurelia Guy and Jacob Menick and Roman Ring and Tom Hennigan and Saffron Huang and Loren Maggiore and Chris Jones and Albin Cassirer and Andy Brock and Michela Paganini and Geoffrey Irving and Oriol Vinyals and Simon Osindero and Karen Simonyan and Jack W. Rae and Erich Elsen and Laurent Sifre } ,
year = { 2022 } ,
eprint = { 2112.04426 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @article { Wang2022DeepNetST ,
title = { DeepNet: Scaling Transformers to 1, 000 Layers } ,
author = { Hongyu Wang and Shuming Ma and Li Dong and Shaohan Huang and Dongdong Zhang and Furu Wei } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2203.00555 }
} @misc { zhang2021sparse ,
title = { Sparse Attention with Linear Units } ,
author = { Biao Zhang and Ivan Titov and Rico Sennrich } ,
year = { 2021 } ,
eprint = { 2104.07012 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
}私はいつも、大人になってからの人生は、子供時代を繰り返し思い出すことだと考えています。 - ウンベルト・エーコ


