rtdl revisiting models
1.0.0
重要
新しい表形式 DL モデル: TabM をチェックしてください。
arXiv ? Python パッケージその他の表形式 DL プロジェクト
これは、論文「表形式データの深層学習モデルの再検討」の正式な実装です。
一言で言えば、MLP のようなモデルは依然として優れたベースラインであり、FT-Transformer は表形式のデータの問題に Transformer アーキテクチャを新しく強力に適応させたものです。
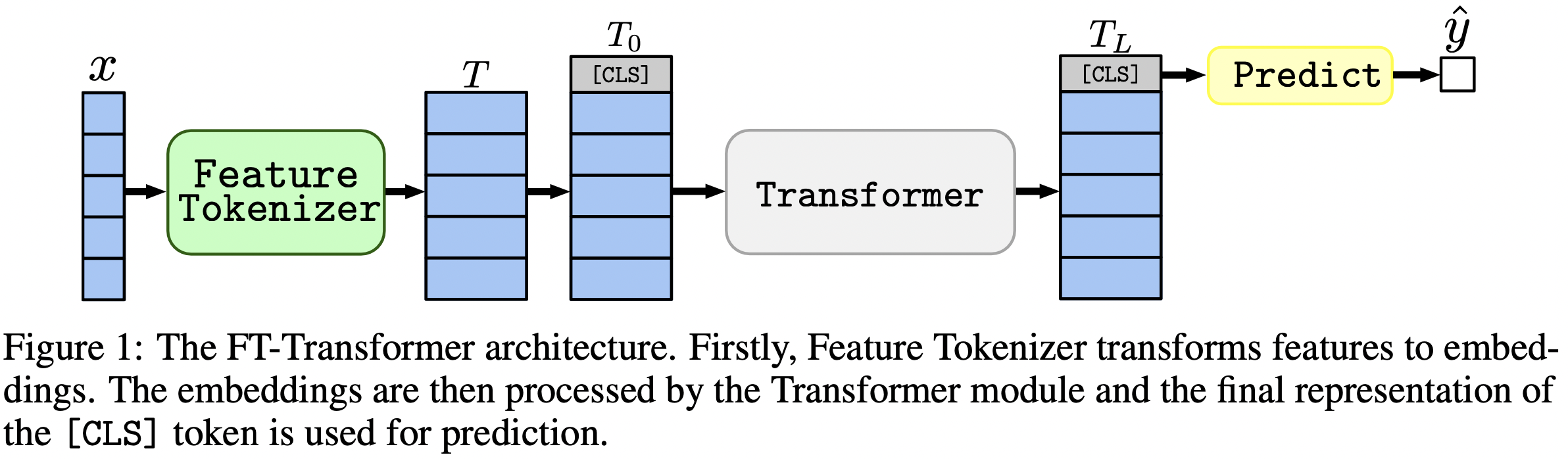
この論文では、表形式のデータ問題のアーキテクチャに焦点を当てています。結果:
package/ディレクトリ内の Python パッケージは、論文を実際に使用する場合や将来の作業に使用する場合に推奨される方法です。
文書の残りの部分:
output/ディレクトリには、論文で使用されているさまざまなモデルやデータセットの多数の結果と (調整された) ハイパーパラメータが含まれています。
たとえば、MLP モデルのメトリクスを調べてみましょう。まず、レポート ( stats.jsonファイル) をロードしましょう。
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'output' ). glob ( '*/mlp/tuned/*/stats.json' )
])ここで、データセットごとに、すべてのランダム シードの平均テスト スコアを計算してみましょう。
print ( df . groupby ( 'dataset' )[ 'metrics.test.score' ]. mean (). round ( 3 ))出力は論文の表 2 と完全に一致します。
dataset
adult 0.852
aloi 0.954
california_housing -0.499
covtype 0.962
epsilon 0.898
helena 0.383
higgs_small 0.723
jannis 0.719
microsoft -0.747
yahoo -0.757
year -8.853
Name: metrics.test.score, dtype: float64
上記のアプローチは、さまざまなアルゴリズムの一般的なハイパーパラメーター値を直感的に把握するためにハイパーパラメーターを調査するために使用することもできます。たとえば、MLP モデルの調整された学習率の中央値を計算する方法は次のとおりです。
注記
一部のアルゴリズム (MLP など) では、より最近のプロジェクトでは、同様の方法で調査できるより多くの結果が提供されます。たとえば、TabR に関するこの論文を参照してください。
警告
このアプローチは注意して使用してください。ハイパーパラメータ値を調べる場合:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002161505605899536注記
このセクションは長いです。このセクションの概要を理解するには、テキスト エディターで GitHub の「アウトライン」機能を使用します。
コードは次のように構成されています。
bin :ensemble.pyアンサンブルを実行しますtune.pyハイパーパラメータ調整を実行しますanalysis_gbdt_vs_nn.py実験を実行しますcreate_synthetic_data_plots.pyプロットを構築しますlib bin内のプログラムで使用される共通ツールが含まれていますoutput構成ファイル ( bin内のプログラムの入力) と結果 (メトリック、調整された構成など) が含まれます。packageこの論文の Python パッケージが含まれていますconda をインストールする
export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/revisiting-models
git clone https://github.com/yandex-research/tabular-dl-revisiting-models $PROJECT_DIR
cd $PROJECT_DIR
conda create -n revisiting-models python=3.8.8
conda activate revisiting-models
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1.243 numpy=1.19.2 -c pytorch -y
conda install cudnn=7.6.5 -c anaconda -y
pip install -r requirements.txt
conda install nodejs -y
jupyter labextension install @jupyter-widgets/jupyterlab-manager
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
conda env config vars set LD_LIBRARY_PATH= ${CONDA_PREFIX} /lib: ${LD_LIBRARY_PATH}
conda env config vars set CUDA_HOME= ${CONDA_PREFIX}
conda env config vars set CUDA_ROOT= ${CONDA_PREFIX}
conda deactivate
conda activate revisiting-modelsこの環境は、TabNet を実験する場合にのみ必要です。それ以外の場合はすべて、PyTorch 環境を使用します。
この手順は PyTorch 環境の場合と同じです (PyTorch のインストールを含む)。ただし、次の点が異なります。
python=3.7.10cudatoolkit=10.0pip install -r requirements.txtの直前に次の操作を実行します。pip install tensorflow-gpu==1.14tensorboard requirements.txtでコメントアウトします。ライセンス:データセットをダウンロードすると、そのすべてのコンポーネントのライセンスに同意したことになります。これらのライセンスに加えて、新たな制限を課すことはありません。出典のリストは、この論文の「参考文献」セクションにあります。
wget https://www.dropbox.com/s/o53umyg6mn3zhxy/data.tar.gz?dl=1 -O revisiting_models_data.tar.gzmv revisiting_models_data.tar.gz $PROJECT_DIRcd $PROJECT_DIRtar -xvf revisiting_models_data.tar.gz このセクションでは、特定のコマンドのみを説明し、いくつかのコメントを付けます。チュートリアルを完了したら、リポジトリの操作方法をよりよく理解するために次のセクションを確認することをお勧めします。チュートリアルをより深く理解するのにも役立ちます。
このチュートリアルでは、カリフォルニアの住宅データセットで MLP の結果を再現します。以下について説明します。
まったく同じ結果が得られる可能性はかなり低いですが、今回の結果とそれほど変わらないはずであることに注意してください。何かを実行する前に、リポジトリのルートに移動し、 CUDA_VISIBLE_DEVICES明示的に設定します (GPU を使用する予定の場合)。
cd $PROJECT_DIR
export CUDA_VISIBLE_DEVICES=0始める前に、環境が正常に構成されていることを確認してください。次のコマンドは、California Housing データセットで 1 つの MLP をトレーニングする必要があります。
mkdir draft
cp output/california_housing/mlp/tuned/0.toml draft/check_environment.toml
python bin/mlp.py draft/check_environment.toml結果はディレクトリdraft/check_environmentにあるはずです。今のところ、結果の内容は重要ではありません。
California Housing データセットで MLP を調整するための構成はoutput/california_housing/mlp/tuning/0.tomlにあります。チューニングを再現するには、設定をコピーしてチューニングを実行します。
# you can choose any other name instead of "reproduced.toml"; it is better to keep this
# name while completing the tutorial
cp output/california_housing/mlp/tuning/0.toml output/california_housing/mlp/tuning/reproduced.toml
# let's reduce the number of tuning iterations to make tuning fast (and ineffective)
python -c "
from pathlib import Path
p = Path('output/california_housing/mlp/tuning/reproduced.toml')
p.write_text(p.read_text().replace('n_trials = 100', 'n_trials = 5'))
"
python bin/tune.py output/california_housing/mlp/tuning/reproduced.tomlチューニングの結果はoutput/california_housing/mlp/tuning/reproducedにあり、私たちのものと比較できます: output/california_housing/mlp/tuning/0 。ファイルbest.tomlには、次のセクションで評価する最適な構成が含まれています。
次に、15 の異なるランダム シードを使用して調整された構成を評価する必要があります。
# create a directory for evaluation
mkdir -p output/california_housing/mlp/tuned_reproduced
# clone the best config from the tuning stage with 15 different random seeds
python -c "
for seed in range(15):
open(f'output/california_housing/mlp/tuned_reproduced/{seed}.toml', 'w').write(
open('output/california_housing/mlp/tuning/reproduced/best.toml').read().replace('seed = 0', f'seed = {seed}')
)
"
# train MLP with all 15 configs
for seed in {0..14}
do
python bin/mlp.py output/california_housing/mlp/tuned_reproduced/ ${seed} .toml
done評価結果が含まれるディレクトリは、あなたのディレクトリのすぐ隣、つまり、 output/california_housing/mlp/tunedにあります。
# just run this single command
python bin/ensemble.py mlp output/california_housing/mlp/tuned_reproduced結果はoutput/california_housing/mlp/tuned_reproduced_ensembleにあり、私たちの結果と比較できます ( output/california_housing/mlp/tuned_ensemble 。
ここで説明するアプローチを使用して、実施された実験の結果を要約します (それに応じて.glob(...)のパス フィルターを変更します: tuned -> tuned_reproduced )。
同様の手順をすべてのモデルとデータセットに対して実行できます。グリッド検索の場合、調整プロセスは少し異なります。必要な構成をすべて実行し、検証パフォーマンスに基づいて最適な構成を手動で選択する必要があります。たとえば、 output/epsilon/ft_transformerを参照してください。
Python スクリプトはリポジトリのルートから実行する必要があります。ほとんどのプログラムは、構成ファイルを唯一の引数として想定します。出力は、構成と同じ名前の拡張子を除いたディレクトリになります。構成は TOML で記述されます。プログラムに使用できる引数のリストは提供されていないため、スクリプトから推測する必要があります (通常、構成はスクリプト内のargs変数で表されます)。 CUDA を使用する場合は、 CUDA_VISIBLE_DEVICES環境変数を明示的に設定する必要があります。例えば:
# The result will be at "path/to/my_experiment"
CUDA_VISIBLE_DEVICES=0 python bin/mlp.py path/to/my_experiment.toml
# The following example will run WITHOUT CUDA
python bin/mlp.py path/to/my_experiment.toml常に CUDA を使用する場合は、環境変数を Conda 環境に保存できます。
conda env config vars set CUDA_VISIBLE_DEVICES= " 0 " -f ( --force ) オプションは、既存の結果を削除し、スクリプトを最初から実行します。
python bin/whatever.py path/to/config.toml -f # rewrites path/to/config bin/tune.py継続をサポートしています。
python bin/tune.py path/to/config.toml --continuestats.jsonとその他の結果すべてのスクリプトにとって、 stats.json出力の最も重要な部分です。内容は番組によって異なります。以下を含めることができます。
通常、トレーニング、検証、テスト セットの予測も保存されます。
これで、すべての結果を再現し、ニーズに合わせてこのリポジトリを拡張するために必要なことがすべてわかりました。チュートリアルもよりわかりやすくなったはずです。気軽に問題を開いて質問してください。
@inproceedings{gorishniy2021revisiting,
title={Revisiting Deep Learning Models for Tabular Data},
author={Yury Gorishniy and Ivan Rubachev and Valentin Khrulkov and Artem Babenko},
booktitle={{NeurIPS}},
year={2021},
}


