video diffusion pytorch
0.7.0
これらの花火は存在しません
テキストをビデオに変換する、それが実現しています!公式プロジェクトページ
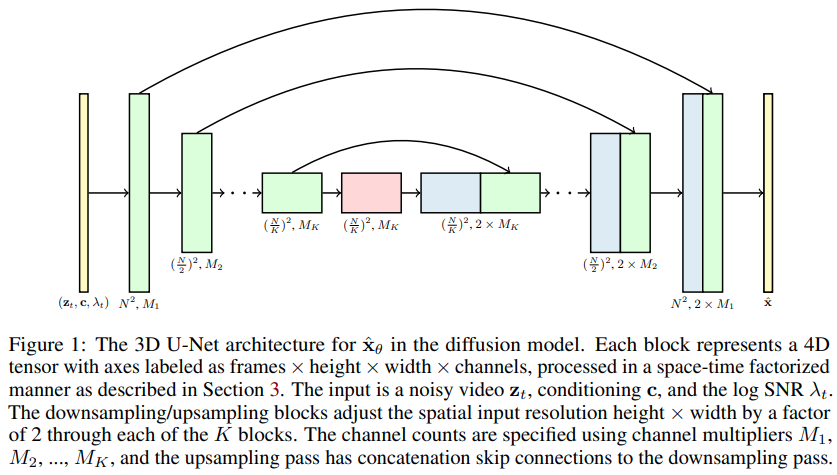
ビデオ拡散モデルの実装、DDPM をビデオ生成に拡張する Jonathan Ho の新しい論文 - Pytorch で。特別な時空因数分解 U-net を使用し、2D 画像から 3D ビデオまで生成を拡張します。
難しい移動の mnist の場合は 14k (NUWA よりもはるかに高速かつ優れた収束) - ウィップ

上記の実験は、Stability.ai が提供するリソースによってのみ可能です。
テキストとビデオの合成に関する新しい開発は Imagen-pytorch に集中されます。
$ pip install video-diffusion-pytorch import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 1 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width) - normalized from -1 to +1
loss = diffusion ( videos )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( batch_size = 4 )
sampled_videos . shape # (4, 3, 5, 32, 32)テキストを条件付けするために、最初にトークン化されたテキストを BERT-large に渡すことでテキスト埋め込みを導出しました。それなら次のように訓練すればいいだけです
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
cond_dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 2 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = torch . randn ( 2 , 64 ) # assume output of BERT-large has dimension of 64
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text )
sampled_videos . shape # (2, 3, 5, 32, 32)テキスト条件付けに BERT ベースを使用する場合は、ビデオの説明を文字列として直接渡すこともできます。
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
use_bert_text_cond = True , # this must be set to True to auto-use the bert model dimensions
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 , # height and width of frames
num_frames = 5 , # number of video frames
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 3 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text , cond_scale = 2 )
sampled_videos . shape # (3, 3, 5, 32, 32) このリポジトリには、 gifsのフォルダーでトレーニングするための便利なTrainerクラスも含まれています。各gif 、正しい寸法image_sizeおよびnum_framesである必要があります。
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion , Trainer
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 64 ,
num_frames = 10 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
). cuda ()
trainer = Trainer (
diffusion ,
'./data' , # this folder path needs to contain all your training data, as .gif files, of correct image size and number of frames
train_batch_size = 32 ,
train_lr = 1e-4 ,
save_and_sample_every = 1000 ,
train_num_steps = 700000 , # total training steps
gradient_accumulate_every = 2 , # gradient accumulation steps
ema_decay = 0.995 , # exponential moving average decay
amp = True # turn on mixed precision
)
trainer . train ()サンプル ビデオ ( gifファイルとして) は、拡散モデル パラメータと同様に、 ./resultsに定期的に保存されます。
この論文の主張の 1 つは、因数分解された時空アテンションを行うことで、画像とビデオを組み合わせてトレーニングするためにネットワークに現在へのアテンションを強制することができ、より良い結果につながるというものです。
彼らがどのようにしてこれを達成したのかは明らかではありませんでしたが、私は推測を進めました。
バッチ ビデオ サンプルの特定の割合について現在の瞬間に注目を集めるには、単純に diffusion forward メソッドでprob_focus_present = <prob>を渡します。
loss = diffusion ( videos , cond = text , prob_focus_present = 0.5 ) # for 50% of videos, focus on the present during training
loss . backward ()これがどのように行われるかについてより詳しいアイデアがある場合は、github のイシューを開いてください。
@misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Saharia2022 ,
title = { Imagen: unprecedented photorealism × deep level of language understanding } ,
author = { Chitwan Saharia*, William Chan*, Saurabh Saxena†, Lala Li†, Jay Whang†, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho†, David Fleet†, Mohammad Norouzi* } ,
year = { 2022 }
}

