nano neuron
1.0.0
機械が実際にどのように「学習」するかを実感できる 7 つのシンプルな JavaScript 関数。
その他の言語: Русский、ポルトガル語
あなたも興味があるかもしれません?インタラクティブな機械学習の実験
NanoNeuron は、Neural Networks の Neuron コンセプトを過度に簡略化したバージョンです。 NanoNeuron は、温度値を摂氏から華氏に変換するようにトレーニングされています。
NanoNeuron.js コード サンプルには 7 つの単純な JavaScript 関数 (モデルの予測、コスト計算、順方向/逆方向の伝播、およびトレーニングに関するもの) が含まれており、マシンが実際にどのように「学習」できるかを実感できます。サードパーティのライブラリ、外部データセットや依存関係はなく、純粋でシンプルな JavaScript 関数のみが使用されます。
☝?これらの関数は、決して機械学習の完全なガイドではありません。多くの機械学習の概念が省略され、過度に単純化されています。この単純化は、読者に機械がどのように学習するのかについての本当に基本的な理解と感覚を与え、最終的には「機械学習の魔法」ではなく「機械学習の数学」であることを読者が認識できるようにするために意図的に行われています。
おそらく、ニューラル ネットワークの文脈でニューロンについて聞いたことがあるでしょう。 NanoNeuron はまさにその通りですが、よりシンプルなので、最初から実装していきます。簡単にするために、NanoNeurons 上にネットワークを構築するつもりもありません。すべてを自動的に動作させ、魔法のような予測を実行します。つまり、この特異な NanoNeuron に温度を摂氏から華氏に変換 (予測) するよう教えます。
ちなみに、摂氏を華氏に変換する式は次のとおりです。
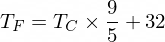
しかし今のところ、私たちの NanoNeuron はそれについて知りません...
NanoNeuron モデル関数を実装してみましょう。これは、 y = w * x + bのようなxとy間の基本的な線形依存関係を実装します。簡単に言うと、私たちの NanoNeuron は、 XY座標で直線を引くように教えられている「学校」の「子供」です。
変数w 、 bモデルのパラメーターです。 NanoNeuron は、線形関数のこれら 2 つのパラメーターについてのみ知っています。これらのパラメータは、NanoNeuron がトレーニング プロセス中に「学習」するものです。
NanoNeuron ができる唯一のことは、線形依存関係を模倣することです。そのpredict()メソッドでは、入力x受け取り、出力y予測します。ここには魔法はありません。
function NanoNeuron ( w , b ) {
this . w = w ;
this . b = b ;
this . predict = ( x ) => {
return x * this . w + this . b ;
}
}(...待って...線形回帰、あなたですか?) ?
摂氏の温度値は、次の式を使用して華氏に変換できます: f = 1.8 * c + 32はcの温度、 f計算された華氏の温度です。
function celsiusToFahrenheit ( c ) {
const w = 1.8 ;
const b = 32 ;
const f = c * w + b ;
return f ;
} ;最終的には、これらのパラメーターを事前に知らなくても、NanoNeuron にこの関数を模倣するように ( w = 1.8およびb = 32あることを学習させるように) 教えたいと考えています。
摂氏から華氏への変換関数は次のようになります。
トレーニングの前に、 celsiusToFahrenheit()関数に基づいてトレーニングとテストのデータセットを生成する必要があります。データセットは、入力値と正しくラベル付けされた出力値のペアで構成されます。
実際には、ほとんどの場合、このデータは生成されるのではなく、収集されることになります。たとえば、手書きの数字の画像のセットと、各画像に書かれている数字を説明する対応する数字のセットがあるとします。
TRAINING サンプル データを使用して NanoNeuron をトレーニングします。 NanoNeuron が成長して自ら意思決定できるようになる前に、トレーニング サンプルを使用して何が正しくて何が間違っているかを教える必要があります。
TEST サンプルを使用して、NanoNeuron がトレーニング中に表示されなかったデータに対してどの程度うまく機能するかを評価します。この時点で、「子供」は成長し、自分で判断できるようになったことがわかります。
function generateDataSets ( ) {
// xTrain -> [0, 1, 2, ...],
// yTrain -> [32, 33.8, 35.6, ...]
const xTrain = [ ] ;
const yTrain = [ ] ;
for ( let x = 0 ; x < 100 ; x += 1 ) {
const y = celsiusToFahrenheit ( x ) ;
xTrain . push ( x ) ;
yTrain . push ( y ) ;
}
// xTest -> [0.5, 1.5, 2.5, ...]
// yTest -> [32.9, 34.7, 36.5, ...]
const xTest = [ ] ;
const yTest = [ ] ;
// By starting from 0.5 and using the same step of 1 as we have used for training set
// we make sure that test set has different data comparing to training set.
for ( let x = 0.5 ; x < 100 ; x += 1 ) {
const y = celsiusToFahrenheit ( x ) ;
xTest . push ( x ) ;
yTest . push ( y ) ;
}
return [ xTrain , yTrain , xTest , yTest ] ;
}モデルの予測が正しい値にどの程度近づいているかを示す何らかのメトリクスが必要です。 NanoNeuron が作成したyの正しい出力値とprediction間のコスト (間違い) の計算は、次の式を使用して行われます。
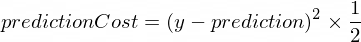
これは 2 つの値間の単純な違いです。値が互いに近いほど、差は小さくなります。ここでは、 (1 - 2) ^ 2 (2 - 1) ^ 2と同じになるように負の数を取り除くためだけに2の累乗を使用しています。 2による除算は、逆方向伝播の式をさらに単純化するために行われています (以下を参照)。
この場合のコスト関数は次のように単純になります。
function predictionCost ( y , prediction ) {
return ( y - prediction ) ** 2 / 2 ; // i.e. -> 235.6
}順伝播を行うということは、 xTrainおよびyTrainデータセットからのすべてのトレーニング サンプルに対して予測を実行し、途中でそれらの予測の平均コストを計算することを意味します。
この時点では、温度の変換方法を推測できるようにするだけで、NanoNeuron に意見を言わせるだけです。ここは愚かな間違いかもしれません。平均コストは、モデルが現時点でどれほど間違っているかを示します。 NanoNeuron パラメーターwとb変更し、順方向伝播を再度実行するため、このコスト値は非常に重要です。これらのパラメータを変更した後、NanoNeuron がより賢くなったかどうかを評価できるようになります。
平均コストは次の式を使用して計算されます。
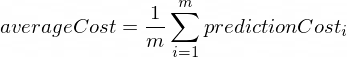
ここで、 mトレーニング例の数です (この場合: 100 )。
これをコードに実装する方法は次のとおりです。
function forwardPropagation ( model , xTrain , yTrain ) {
const m = xTrain . length ;
const predictions = [ ] ;
let cost = 0 ;
for ( let i = 0 ; i < m ; i += 1 ) {
const prediction = nanoNeuron . predict ( xTrain [ i ] ) ;
cost += predictionCost ( yTrain [ i ] , prediction ) ;
predictions . push ( prediction ) ;
}
// We are interested in average cost.
cost /= m ;
return [ predictions , cost ] ;
}NanoNeuron の予測が (この時点での平均コストに基づいて) どれだけ正しいか間違っているかがわかったら、予測をより正確にするために何をすべきでしょうか?
逆伝播によって、この質問に対する答えが得られます。逆方向伝播は、予測のコストを評価し、次回および将来の予測がより正確になるように NanoNeuron のパラメーターwおよびbを調整するプロセスです。
これは機械学習が魔法のように見える場所です?♂️。ここでの重要な概念は、コスト関数の最小値に近づくためにどのようなステップを踏むべきかを示す導関数です。
コスト関数の最小値を見つけることがトレーニング プロセスの最終目標であることを忘れないでください。平均コスト関数が小さくなるようなwとbの値が見つかった場合、NanoNeuron モデルが非常に優れた正確な予測を行っていることを意味します。
デリバティブは独立した大きなトピックですが、この記事では取り上げません。 MathIsFun は、基本的な理解を得るのに適したリソースです。
導関数に関して、逆伝播がどのように機能するかを理解するのに役立つことの 1 つは、導関数はその意味上、関数の最小値の方向を指す関数曲線の接線であるということです。
画像ソース: MathIsFun
たとえば、上のプロットでは、 (x=2, y=4)の点にいる場合、関数の最小値に到達するにはleftにdown進む必要があることがわかります。また、傾きが大きいほど、最小値まで速く移動する必要があることに注意してください。
パラメーターwおよびbのaverageCost関数の導関数は次のようになります。
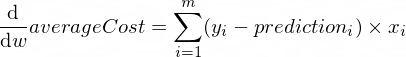
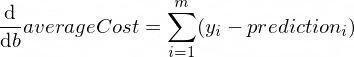
ここで、 mトレーニング例の数です (この場合: 100 )。
導関数のルールと複雑な関数の導関数を取得する方法について詳しくは、こちらをご覧ください。
function backwardPropagation ( predictions , xTrain , yTrain ) {
const m = xTrain . length ;
// At the beginning we don't know in which way our parameters 'w' and 'b' need to be changed.
// Therefore we're setting up the changing steps for each parameters to 0.
let dW = 0 ;
let dB = 0 ;
for ( let i = 0 ; i < m ; i += 1 ) {
dW += ( yTrain [ i ] - predictions [ i ] ) * xTrain [ i ] ;
dB += yTrain [ i ] - predictions [ i ] ;
}
// We're interested in average deltas for each params.
dW /= m ;
dB /= m ;
return [ dW , dB ] ;
}これで、すべてのトレーニング セットの例に対するモデルの正確さを評価する方法 (順伝播) がわかりました。また、NanoNeuron モデルのパラメーターwとb微調整する方法 (逆方向伝播) も知っています。しかし、問題は、順伝播を 1 回だけ実行してから逆伝播を実行した場合、モデルがトレーニング データから法則や傾向を学習するのに十分ではないことです。これは、子供が小学校に 1 日通うことにたとえられるかもしれません。一度ではなく、毎日、毎年、何かを学ぶために学校に行くべきです。
したがって、モデルに対して順方向伝播と逆方向伝播を何度も繰り返す必要があります。それはまさにtrainModel()関数が行うことです。これは、NanoNeuron モデルの「教師」のようなものです。
epochs ) 費やして、トレーニング/教育を試みます。xTrainおよびyTrainデータセット) を使用します。alpha使用することで、子供がより激しく (より速く) 学習するように促します。学習率alphaについて少し説明します。これは、逆方向伝播中に計算したdW値とdB値の単なる乗数です。したがって、導関数は、コスト関数 ( dWとdB符号) の最小値を見つけるために取るべき方向を示し、また、その方向にどれだけ早く進む必要があるか ( dWとdBの絶対値) も示しました。次に、動きを最小限に速くまたは遅く調整するために、これらのステップ サイズをalphaに乗算する必要があります。場合によっては、 alphaに大きな値を使用すると、単に最小値を飛び越えてしまい、最小値が見つからない可能性があります。
教師に喩えると、「ナノキッド」を強く押し込めば押すほど、「ナノキッド」の学習は早くなりますが、先生が押し込みすぎると、「子供」は神経衰弱を起こして学習できなくなります。何も学べないのですか?
モデルのwパラメータとbパラメータを更新する方法は次のとおりです。
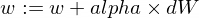
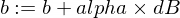
そして、これがトレーナー関数です:
function trainModel ( { model , epochs , alpha , xTrain , yTrain } ) {
// The is the history array of how NanoNeuron learns.
const costHistory = [ ] ;
// Let's start counting epochs.
for ( let epoch = 0 ; epoch < epochs ; epoch += 1 ) {
// Forward propagation.
const [ predictions , cost ] = forwardPropagation ( model , xTrain , yTrain ) ;
costHistory . push ( cost ) ;
// Backward propagation.
const [ dW , dB ] = backwardPropagation ( predictions , xTrain , yTrain ) ;
// Adjust our NanoNeuron parameters to increase accuracy of our model predictions.
nanoNeuron . w += alpha * dW ;
nanoNeuron . b += alpha * dB ;
}
return costHistory ;
}上で作成した関数を使用してみましょう。
NanoNeuron モデル インスタンスを作成しましょう。現時点では、NanoNeuron はパラメーターwおよびbにどのような値を設定する必要があるかを知りません。そこで、 wとbランダムに設定してみましょう。
const w = Math . random ( ) ; // i.e. -> 0.9492
const b = Math . random ( ) ; // i.e. -> 0.4570
const nanoNeuron = new NanoNeuron ( w , b ) ;トレーニングとテストのデータセットを生成します。
const [ xTrain , yTrain , xTest , yTest ] = generateDataSets ( ) ; 70000エポックの間、小さな増分 ( 0.0005 ) ステップでモデルをトレーニングしてみましょう。これらのパラメータは経験的に定義されているため、いろいろ試すことができます。
const epochs = 70000 ;
const alpha = 0.0005 ;
const trainingCostHistory = trainModel ( { model : nanoNeuron , epochs , alpha , xTrain , yTrain } ) ;トレーニング中にコスト関数がどのように変化したかを確認してみましょう。トレーニング後のコストは以前よりも大幅に低くなるはずです。これは、NanoNeuron がより賢くなったことを意味します。その逆も可能です。
console . log ( 'Cost before the training:' , trainingCostHistory [ 0 ] ) ; // i.e. -> 4694.3335043
console . log ( 'Cost after the training:' , trainingCostHistory [ epochs - 1 ] ) ; // i.e. -> 0.0000024これは、エポックの経過とともにトレーニング コストがどのように変化するかです。 x軸はエポック番号 x1000 です。
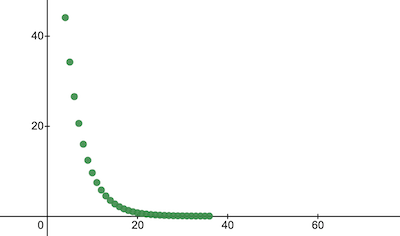
NanoNeuron のパラメーターを見て、何を学習したかを見てみましょう。 NanoNeuron はそれを模倣しようとしたため、NanoNeuron パラメーターwおよびb celsiusToFahrenheit()関数の値 ( w = 1.8およびb = 32 ) と類似していると予想されます。
console . log ( 'NanoNeuron parameters:' , { w : nanoNeuron . w , b : nanoNeuron . b } ) ; // i.e. -> {w: 1.8, b: 31.99}テスト データセットのモデルの精度を評価して、NanoNeuron が新しい未知のデータ予測をどの程度うまく処理できるかを確認します。テストセットでの予測のコストは、トレーニングのコストに近いと予想されます。これは、NanoNeuron が既知のデータでも未知のデータでも良好に動作することを意味します。
[ testPredictions , testCost ] = forwardPropagation ( nanoNeuron , xTest , yTest ) ;
console . log ( 'Cost on new testing data:' , testCost ) ; // i.e. -> 0.0000023さて、NanoNeuron の「子供」がトレーニング中に「学校」で良い成績を収め、見たことのないデータであっても摂氏を華氏に正しく変換できることがわかったので、それを「賢い」と呼ぶことができます。そして彼にいくつか質問してください。これがトレーニング プロセス全体の最終目標でした。
const tempInCelsius = 70 ;
const customPrediction = nanoNeuron . predict ( tempInCelsius ) ;
console . log ( `NanoNeuron "thinks" that ${ tempInCelsius } °C in Fahrenheit is:` , customPrediction ) ; // -> 158.0002
console . log ( 'Correct answer is:' , celsiusToFahrenheit ( tempInCelsius ) ) ; // -> 158とても近いです!私たち人間として、NanoNeuron は優れていますが、理想的ではありません :)
楽しく学んでください!
リポジトリのクローンを作成し、ローカルで実行できます。
git clone https://github.com/trekhleb/nano-neuron.git
cd nano-neuronnode ./NanoNeuron.js説明を簡単にするために、次の機械学習の概念は省略され、単純化されています。
トレーニング/テストのデータセット分割
通常、1 つの大きなデータセットがあります。そのセット内のサンプルの数に応じて、トレーニング セット/テスト セットに対して 70/30 の比率で分割することをお勧めします。セット内のデータは、分割前にランダムにシャッフルされる必要があります。例の数が大きい場合 (つまり数百万)、トレーニング/テスト データセットの分割は 90/10 または 95/5 に近い割合で発生する可能性があります。
ネットワークが力をもたらす
通常、スタンドアロン ニューロンが 1 つだけ使用されていることには気づきません。力はそのようなニューロンのネットワークにあります。ネットワークはさらに複雑な機能を学習する可能性があります。 NanoNeuron 単体では、ニューラル ネットワークというよりも単純な線形回帰のように見えます。
入力の正規化
トレーニングの前に、入力値を正規化することをお勧めします。
ベクトル化された実装
ネットワークの場合、ベクトル化された (行列) 計算はforループよりもはるかに高速に動作します。通常、順方向/逆方向伝播は、ベクトル化された形式で実装され、Numpy Python ライブラリなどを使用して計算される場合、はるかに高速に動作します。
コスト関数の最小値
この例で使用していたコスト関数は過度に単純化されています。対数成分が含まれている必要があります。コスト関数を変更すると、その導関数も変更されるため、逆伝播ステップでも異なる式が使用されます。
アクティベーション機能
通常、ニューロンの出力は、Sigmoid や ReLU などの活性化関数を通過する必要があります。


