PALM E
0.0.4

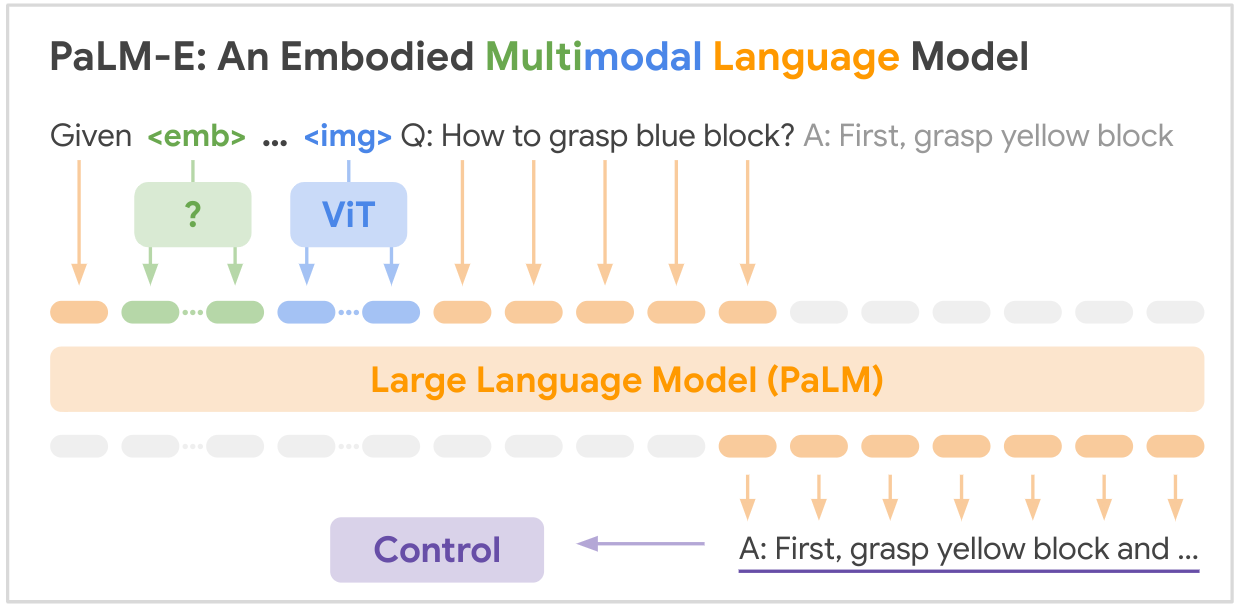
これは、Google の SOTA マルチモーダリティ基盤モデル「PALM-E: An Embodied Multimodal Language Model」のオープンソース実装です。PALM-E は、単一の大規模な具体化されたマルチモーダル モデルであり、さまざまな具体化された推論タスクに対処できます。複数の実施形態でのさまざまな観察モダリティは、さらにポジティブな転移を示します。モデルは、インターネット規模の言語、視覚、および視覚言語の領域にわたる多様な共同トレーニングの恩恵を受けています。
論文リンク: PaLM-E: 身体化されたマルチモーダル言語モデル
pip install palme import torch
from palme . model import PalmE
#usage
img = torch . randn ( 1 , 3 , 256 , 256 )
caption = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
model = PalmE ()
output = model ( img , caption )
print ( output . shape ) # (1, 1024, 20000)
以下は、論文で言及されている主要なデータセットの要約表です。
| データセット | タスク | サイズ | リンク |
|---|---|---|---|
| タンプ | ロボット操作計画、VQA | 96,000シーン | カスタム データセット |
| 言語テーブル | ロボット操作計画 | カスタム データセット | リンク |
| モバイル操作 | ロボットのナビゲーションと操作の計画、VQA | 2912 シーケンス | SayCan データセットに基づく |
| WebLI | 画像とテキストの検索 | 6,600万の画像とキャプションのペア | リンク |
| VQAv2 | 視覚的な質問応答 | COCO 画像に関する 110 万件の質問 | リンク |
| OK-VQA | 外部知識を必要とする視覚的な質問応答 | COCO 画像に関する 14,031 件の質問 | リンク |
| ココ | 画像のキャプション | キャプション付きの 330,000 枚の画像 | リンク |
| ウィキペディア | テキストコーパス | 該当なし | リンク |
主要なロボット データセットはこの作業のために特別に収集されたものですが、より大きな視覚言語データセット (WebLI、VQAv2、OK-VQA、COCO) はこの分野の標準ベンチマークです。データセットの範囲は、ロボット工学ドメインの数万の例から、インターネット スケールの視覚言語データの数千万に及びます。
あなたの輝きが必要です!参加して、一緒に PALM-E をさらに素晴らしいものにしましょう:
?修正、?機能拡張、ドキュメント、アイデアなど、すべて大歓迎です。手を携えて AI の未来を形作っていきましょう。
@article{driess2023palme,
title={PALM-E: An Embodied Multimodal Language Model},
author={Driess, Danny and Xia, Fei and Sajjadi, Mehdi S. M. and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and Huang, Wenlong and Chebotar, Yevgen and Sermanet, Pierre and Duckworth, Daniel and Levine, Sergey and Vanhoucke, Vincent and Hausman, Karol and Toussaint, Marc and Greff, Klaus and Zeng, Andy and Mordatch, Igor and Florence, Pete},
journal={arXiv preprint arXiv:2303.03378},
year={2023},
url={https://doi.org/10.48550/arXiv.2303.03378}
}

